Evaluating and starting to develop professional, production-grade GUIs on embedded Linux should be frictionless. Based on this statement, we are always working with our partners to improve the Qt developer experience. Together with Toradex we recently made major improvements to the Torizon Qt VS Code template, making it easier for you as a developer to use Qt Device Creation Enterprise workflows inside the same template that you might already have been using with the Device Creation Community Edition. On top of that, there is a brand-new Qt demo in the Torizon Demo Gallery which you can try right away.
Torizon is a production-ready, container-based embedded Linux platform that simplifies how Qt applications are deployed and maintained. Qt developers may already be familiar with Boot2Qt, which is a useful tool to get a Qt prototype running quickly. However, scaling that prototype into a secure, maintainable, and updatable product usually requires building and managing your own Yocto stack. Torizon removes this burden, providing a pre-integrated OS, hardware-optimized Qt runtime, OTA automated updates, CVE tracking and a consistent containerized workflow, letting you focus entirely on your Qt application instead of maintaining the underlying Linux distribution.Below you’ll find what’s new, why it helps Qt developers, and exactly how to try it.
Explore how SWHID is applied in real-world scenarios to improve SBOMs, support Cyber Resilience Act compliance, and enable software traceability. Discover practical use cases across telecom and automotive industries, based on insights from recent industry talks.
At the first start of an application, user can be a bit confused in front of all of these features, buttons and data.
In response to that, we often have a short presentation of each element on the screen.
This also presents a typical workflow with the application.
First, You need to create a project or document.
Then, define the name, the type…
Then add content using this or that.
This feature is often called UI walk through, or UI tour.
UI Walker
I made this library to provide an easy way to do a walkthrough in any QML application.
Using cmake it is really easy. You can define the library to be a git submodule and then
Prepare you qml code
The whole concept is based on attached property.
To highlight a item, you must define two properties:
WalkerItem.description: the text that will be displayed when this element is highlighted
WalkerItem.weight: Numeric value to define the order (ascending order).
ToolButton {
WalkerItem.description: qsTr("Description of the element")
WalkerItem.weight: 104
}
Add the UI walker
Currently, you have to add one item. It should have the size of the whole window.
This item provides several properties in order to help you manage the output.
Highlighted items get notified through two signals: enter and exit.
Defining signal handlers allow you to react. So you can show the full workflow to add new data.
In order, to start the UI tour, you simply have to call the function: start() of the Item.
Of course, it is up to you to trigger it automatically when it’s the first start of the application or if the user asked for the tour.
I have a CPP controller with property UiTour which gives the current status of the tour.
Here, I call directly the walker function. But it may be safer to call a function to reset the state of the window.
Navigation
The walker provides two important function next() and previous() to navigate.
Basically on the walker, you can add buttons in the available Rect to manage the navigation.
Other option, you can define an interval in milliseconds which will call the next() function.
You have to make sure the item is visible while the walker highlight it. It could be tricky to make the path from the end to be beginning. In some case, it is easier to never use the previous function.
Finish it!
Calling the function skip(), close the walker. Then the application is displayed normally.
It can be called at any time.
Cheat code
Function
description
start()
The walker becomes visible, and the first item is highligthed
next()
Highlight the next item, trigger appropriated signals
previous()
Highlight the previous item, trigger appropriated signals
skip()
Hide the walker
How it works ?
The attached properties
In order to harvest all data from the QML, I had to define attached property.
This is the definition of QObject which will be attached, each time a QML item has defined any Walker property.
In the WalkerItem.h, I have to create this static function.
// …
Q_OBJECT
QML_ATTACHED(WalkerAttachedType)
// …
static WalkerAttachedType* qmlAttachedProperties(QObject* object)
{
QQuickItem* item= qobject_cast<QQuickItem*>(object);
if(!item)
qDebug() << "Walker must be attached to an Item";
s_items.append(item);
return new WalkerAttachedType(object);
}
QSceneGraph and Nodes
WalkreItem defines a QML item, written in cpp to be light-weighted.
I used QSGNode to draw it on screen. The item code manages the logic of the walkthrough and the update of the geometry.
To make it short, the SceneGraph is the rendering engine of QML. QSGNode defines an API to communicate with it directly.
First, I create the QML item in cpp, using QSGNode to be rendered.
//walkeritem.h
class WalkerItem : public QQuickItem
{
Q_OBJECT
QML_ATTACHED(WalkerAttachedType)
QML_ELEMENT
Q_PROPERTY(QString currentDesc READ currentDesc NOTIFY currentChanged FINAL)
Q_PROPERTY(QColor dimColor READ dimColor WRITE setDimColor NOTIFY dimColorChanged FINAL)
Q_PROPERTY(qreal dimOpacity READ dimOpacity WRITE setDimOpacity NOTIFY dimOpacityChanged FINAL)
Q_PROPERTY(QRectF availableRect READ availableRect NOTIFY availableRectChanged FINAL)
Q_PROPERTY(QRectF borderRect READ borderRect NOTIFY borderRectChanged FINAL)
Q_PROPERTY(int interval READ interval WRITE setInterval NOTIFY intervalChanged FINAL)
Q_PROPERTY(bool active READ active NOTIFY activeChanged FINAL)
public:
WalkerItem();
// accessors, signals, slots…
protected:
QSGNode* updatePaintNode(QSGNode*, UpdatePaintNodeData*) override;// update scenegraph
};
//walkeritem.cpp
WalkerItem::WalkerItem()// in the constructor
{
setFlag(QQuickItem::ItemHasContents);// must be called
connect(child, &QQuickItem::widthChanged, this, &WalkerItem::updateComputation);
connect(child, &QQuickItem::heightChanged, this, &WalkerItem::updateComputation);
}
void WalkerItem::updateComputation()
{
// compute geometry and list any changes that must be sync with the SceneGraph.
m_change|= WalkerItem::ChangeType::GeometryChanged;
update();// call to paint the item
}
QSGNode* WalkerItem::updatePaintNode(QSGNode* node, UpdatePaintNodeData*)
{
auto wNode= static_cast<WalkerNode*>(node);
if(!wNode)
{
wNode= new WalkerNode();//first time
}
if(m_change & WalkerItem::ChangeType::ColorChanged)
wNode->updateColor(m_dimColor);
if(m_change & WalkerItem::ChangeType::GeometryChanged)
wNode->update(boundingRect(), m_targetRect);
if(m_change & WalkerItem::ChangeType::OpacityChanged)
wNode->updateOpacity(m_dimOpacity);
m_change= WalkerItem::ChangeType::NoChanges;
return wNode;
}
We have here an item with a geometry like any other item (x,y,width, height), we also have a dimColor and dimOpacity.
Any time one of these properties change. I have to sync with the QSceneGraph to update either the geometry, the dimColor or the dimOpacity.
Each time, one property changes, I stored the type of change in the m_change member and I call update().
The render engine will call my item with the QSGNode reprenting it on the SceneGraph side.
Then I can call function on my SGNode. When sync is finished I reset the change to NoChange and return the node.
The updatePaintNode can be called with a null node. In this case, you have to create it. It will be the case, the first time. And it could happen later in some cases for optimalization reason.
Now, let see the code of the QSGNode. You have to see the QSGNode as the root item of a tree. Where each node is in charge of representing one aspect of the item: its geometry, its color and its opacity.
void WalkerNode::update(const QRectF& out, const QRectF& in)
{
// out is the geometry of the window
// in is the geometry of the highlighted item
const auto a= out.topLeft();
const auto b= in.topLeft();
const auto c= in.topRight();
const auto d= out.topRight();
const auto e= in.bottomRight();
const auto f= out.bottomRight();
const auto g= in.bottomLeft();
const auto h= out.bottomLeft();
{
auto gem= m_dim.geometry();
auto vertices= gem->vertexDataAsPoint2D();
QList<std::array<QPointF, 3>> triangles{{a, b, d}, {b, d, c}, {d, c, f}, {c, f, e},
{f, e, h}, {e, g, h}, {h, g, a}, {g, a, b}};
int i= 0;
for(auto t : triangles)
{
vertices[i + 0].set(t[0].x(), t[0].y());
vertices[i + 1].set(t[1].x(), t[1].y());
vertices[i + 2].set(t[2].x(), t[2].y());
i+= 3;
}
m_dim.markDirty(QSGNode::DirtyGeometry | QSGNode::DirtyMaterial);
}
markDirty(QSGNode::DirtyGeometry | QSGNode::DirtyMaterial);
}
We split the surface we have to cover in triangles.
Todo
Animations: Smooth animation while transiting from one item to another.
Test on bigger apps
Find a logic to allow previous
Use shader effect to make it better.
Other…
Conclusion:
UiWalker is already in production. It works like a charm. I hope to use it elsewhere. Then, I will add some new features. Contributions and comments are welcomed.
Tuesday, 7 April 2026. Today KDE releases a bugfix update to KDE Plasma 6, versioned 6.6.4.
Plasma 6.6 was released in February 2026 with many feature refinements and new modules to complete the desktop experience.
This release adds three weeks’ worth of new translations and fixes from KDE’s contributors. The bugfixes are typically small but important and include:
The last post regarding work on fixing Oxygen was a month and a half ago. With all that's happened in between, it feels like so much more time has actually passed. With this post, I'd like to do a sort of mid-term update summing up all of the improvements done so far. These improvements are...... Continue Reading →
For the next digiKam releases, the digiKam team needs photographs for digiKam and Showfoto splash-screens.
Proposing photo samples as splash-screens is a simple way for users to contribute to digiKam project. The pictures must be correctly exposed/composed, and the subject must be chosen from a real photographer’s inspiration. Note that we will add a horizontal frame to the bottom of the image as in the current splashes.
The Kdenlive 26.04 Release Candidate is ready for testing. Many bug fixes and workflow adjustments should make your editing sessions nicer. It is also worth noting that we had quite a few new contributors helping our small team on this, so thanks to all those who helped us!
Please remember that this is an RC version, not yet final, to be used only for testing and reporting issues.
Features highlights:
Added animated previews for transitions
Added a feature to mirror the monitor to an external monitor, allowing you to see the image in the usual interface, while duplicating the output to a secondary monitor
Added an entry in the timeline context menu to directly import a clip to the project and add it at click position
Added an option to always zoom on the mouse position instead of the timeline playhead
Generate audio thumbnails for sequences
Dropping a transition to timeline will automatically adjust its duration to the above/below clips
Allow changing speed of multiple clips
Feedback Needed
Now is your chance to test it and let us know if you encounter any bugs or have suggestions to help us polish the final release. Share your feedback in the comments below
Available Binaries
The AppImage and Windows versions can be downloaded through the links below. Update: the MacOS binaries are now also available
Download the binaries from below and give it a spin!
The (translated) session notes are in the wiki.
There’s some recurring themes, such as increasing the level of detail in the third dimension,
as well as how to properly map inclined areas and two-dimensional walls. None of that has a good solution yet, so we are trying to get the right
people together for a multi-day in-person workshop to finally progress those topics.
I’m also increasingly wondering whether we need to replace the term “indoor” in this context, as that means
different things to different people:
Mapping physically within a building. That separation is all but clear-cut though, in particular in and around train stations.
Mapping using areas rather than ways. That’s also not unique for being “indoor”.
Using the level tagging from SIT. While referring to
“floor levels”, this is the best way we have to place features vertically, and that’s also something that isn’t limited
to buildings.
Triggered by talks on indoor navigation in previous years which weren’t as forthcoming
with actually publishing their code or papers as one might expect for a conference with “FOSS” in the name
already, I presented the work we did in KDE
for OSM-based indoor routing for Itinerary and Kongress.
The implementation is part of the KOSMIndoorMaps library and
uses Recast Navigation under the hood. This works solely on areas, without needing an explicit routing graph.
And it allows for routing to/from any arbitrary point, which is a requirement for localization/navigation use-cases.
There’s drawbacks as well, directional cost on inclined ways are hard to consider with this for example.
OSM Indoor routing talk.
Richard from TU Dresden presented an alternative approach
for indoor routing, semi-automatically generating routing graphs inside areas. This provides visually nicer
results in narrow corridors, but becomes more challenging in open areas. By pure chance both our talks
used the same building for demonstration, quite useful for discussing the strength and weaknesses of both ways.
Another topic of discussions was how to scale this up from working on a single building to something a
planet-scale router such as MOTIS could integrate. Neither approach is well suited
for that out of the box.
The conference provided the opportunity to talk to data providers about what we would need or would like to have
for Transitous, as well as to data consumers, such as CoMaps, who are exploring integrating
public transport routing.
And with several Transitous contributors around we also discussed a bunch of topics being currently looked into:
How to integrate the Danish Siri-over-AMQP feeds.
Parsing issues with the Swiss aerial lift NeTEx feed.
Sorting out the API key handling for the Baden-Württemberg Amarillo ride sharing feed.
Implementing spport for temporary POIs such as events.
Getting “DIID” elevator identifiers into OSM, for matching SIRI-FM realtime status feeds to OSM data for routing.
How to integrate empirical delay data into the MOTIS API.
KDE Itinerary
I also met a few Itinerary users and got feedback on current issues.
An area that needs work is the fallback handling in the KPublicTransport library.
We aren’t very good (yet) at switching to different sources when the primary one fails to deliver useful results.
With the DB API becoming increasingly unreliable due to randomly blocking access (not just our apps,
also affects their website), this becomes increasingly visible.
FOSSGIS e.V.
FOSSGIS e.V. is the German local chapter for OSM, and the organizer of the FOSSGIS-Konferenz.
Given the significant overlap in topics (and some overlap in people) FOSSGIS e.V. has been one of the obvious organizational
umbrellas for both the Open Transport Community Conference and Transitous.
This has been moving forward recently, and will solve a few practical problems:
Allow us to hold assets like domains independent of individual contributors, removing single points of failure.
Allows us to receive and spend money in a clean way.
This is rather important for the long-term sustainability of both initiatives. Being able to handle money is especially pressing for the
Open Transport conference, as given the rather expensive location this year we’d like to offer some form of travel
support for people who aren’t attending this as part of their job.
Dynamic traffic data
Following a joined HeiGIT/BKG talk on routing quality there were a lot of
hallway discussions on dynamic traffic data, as well as a
session
during the unconference part, all focusing on a proper free and open solution for this.
Dynamic traffic data includes:
(Aggregated) realtime traffic flow data (ie. current traffic jams).
Raw traffic flow sensor data, ie. sensors counting vehicles or floating vehicle position/speed vector data.
Statistical traffic flow data (ie. high traffic expected during specific times).
Dynamic traffic sign data, such as adaptive speed limits.
Temporary closures due to construction work, accidents, etc.
Realtime availability data for bike or car parking spaces.
This is crucial information for road routing, traffic planning and research. However currently this data is collected and owned
by a few proprietary vendors. Google is a particularly big player here, using the position data submitted by Android phones.
In order to build a free and open replacement the only chance we have is to do that jointly, between all parties with any interest
in this, otherwise this wont gather the necessary critical mass. Doing this under the OSM umbrella seems to be the
obvious choice, especially since this needs to be mapped on to the static OSM road network data anyway.
It would certainly be an ambitious project, but there’s a bunch of building blocks to work with already:
Sensor data from some public authorities, with various levels of processing applied.
A few cases of realtime data for dynamic traffic signs from their operators.
(Planned) construction site data in Datex II format by public authorities,
Floating vehicle information from GTFS-RT vehicle position feeds for busses (which we consume for Transitous already).
While this is mostly affecting roads (and thus cars and busses), construction work can also affect pedestrian and bike routing,
either entirely or by changing e.g. relevant accessibility properties for wheelchair routing. There was agreement that any free and open
effort should equally consider those modes of transportation.
The open source routing engines either already have support for integrating dynamic traffic data, or have adding support
on their roadmap, Transitous would certainly integrate that as well. Public agencies were equally interested
in open traffic data, but not all of them did show quite the same enthusiasm for also contributing to that yet.
This was a somewhat quiet week mostly full of UI and stability improvements, perhaps because many KDE contributors are gearing up for next week’s mega-sprint in Graz! For the same reason, expect next week’s post to be short or non-existent.
Notable UI improvements
Plasma 6.7
Breeze-themed menu items throughout KDE’s software ecosystem now visually change when clicked. (Akseli Lahtinen, breeze MR #605)
A variety of tooltips throughout Plasma now follow the styling of the active Plasma theme as expected. (Nicolas Fella, libplasma MR #1435)
Improved the Mouse Mark effect’s support for touchscreens: now you can draw multiple lines at a time if you have a multi-touch-capable screen. (Tin Dao, kwin MR #8951)
Synchronizing settings to the Plasma Login Manager now includes the current set of keyboard layouts. (Oliver Beard, KDE Bugzilla #516778)
Simplified the UI for the Clipboard widget’s QR code page: now the copy button is in the header, rather than all alone on its own row. (Tobias Fella, plasma-workspace MR #6451)
Removed the feature to force the Task Manager and System Tray widgets to use a large spacing and icon size while in touch/tablet mode; it just didn’t work out, and caused un-resolvable sizing bugs. (Nate Graham, KDE Bugzilla #511439)
Improved the accuracy of widget positioning on the desktop: dragging a widget somewhere it won’t fit will now show its preview rectangle in the nearest place where it will fit, which is where it will end up. (Tobias Fella, plasma-workspace MR #6452)
Discover now uses consistent terminology when it asks you to restart. (Nate Graham, KDE Bugzilla #517630)
Frameworks 6.25
Trying to paste when your clipboard is empty now fails silently rather than showing a notification about it. (Tobias Fella, kio MR #2168)
Notable bug fixes
Plasma 6.6.4
Hardened Plasma against crashing while trying to load a broken widget. (Harald Sitter, libplasma MR #1456)
Fixed a case where the KDED background daemon could die with a Wayland protocol error when changing the screen resolution. (Xaver Hugl, KDE Bugzilla #516217)
Fixed a bizarre issue that mangled certain text formatted with Markdown styling while Plasma’s on-screen keyboard was enabled but not visible. (Devin Lin, KDE Bugzilla #516511)
Fixed a case where System Settings’ Plasma Style page could crash on certain distros shipping Qt 6.11 with asserts turned on. (Ismael Asensio, plasma-workspace MR #6458)
Fixed usage graphs for certain NVIDIA GPUs being broken in the System Monitor app and widgets. (Bernhard Friedreich, libksysguard MR #465)
Popups for editing widgets while in Plasmas’s edit mode now work with a touchscreen. (Marco Martin, KDE Bugzilla #509880)
Hardened KWin against XWayland apps being sized incorrectly on systems with config files containing inappropriate scale values. (Xaver Hugl, kwin MR #9049)
Rolled out a more complete fix for context menus of System Tray icons sometimes having ugly square black corners. (Nate Graham, KDE Bugzilla #513307)
Implemented support for the xx-fractional-scale-v2 Wayland protocol, which improves visual fidelity by reducing gaps between adjacent items. (Vlad Zahorodnii, kwin MR #9023)
Continued with the work to add Vulkan support. (Diego Gomez, kwin MR #9027)
How you can help
KDE has become important in the world, and your time and contributions have helped us get there. As we grow, we need your support to keep KDE sustainable.
Would you like to help put together this weekly report? Introduce yourself in the Matrix room and join the team!
Beyond that, you can help KDE by directly getting involved in any other projects. Donating time is actually more impactful than donating money. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine! You don’t have to be a programmer, either; many other opportunities exist.
You can also help out by making a donation! This helps cover operational costs, salaries, travel expenses for contributors, and in general just keeps KDE bringing Free Software to the world.
To get a new Plasma feature or a bug fix mentioned here

 toscalix
toscalix
 obiwan_kennedy
obiwan_kennedy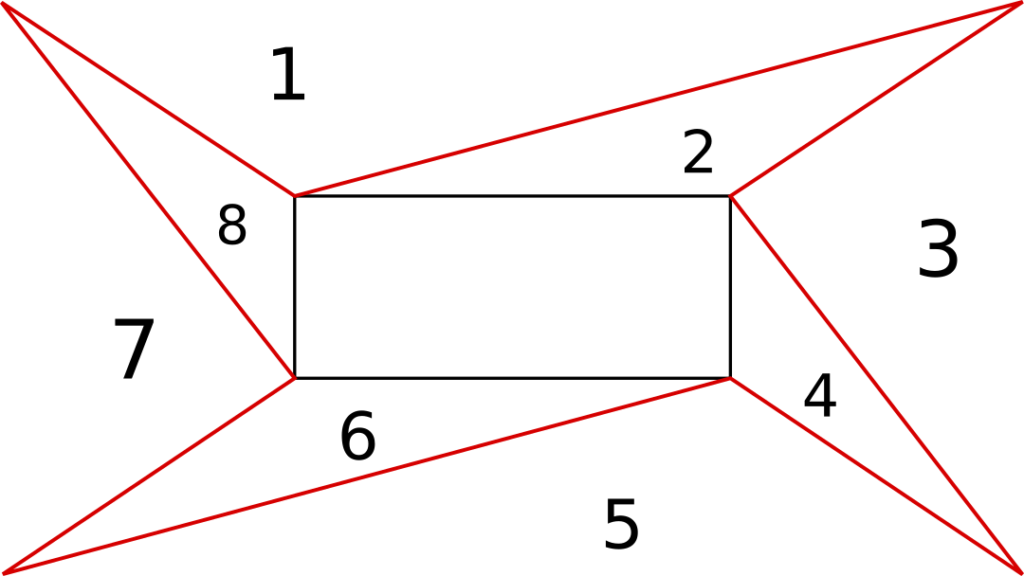



 @shibe_13:matrix.org
@shibe_13:matrix.org







