The secret weapon for processing millions of messages in order with Elixir
Modern distributed systems need to process massive amounts of data efficiently while maintaining strict ordering guarantees. This is especially challenging when scaling horizontally across multiple nodes. How do we ensure messages from specific sources are processed in order while still taking advantage of parallelism and fault tolerance?
Elixir, with its robust concurrency model and distributed computing capabilities, is well-suited for solving this problem. In this article, we’ll build a scalable, distributed message pipeline that:
- Bridges RabbitMQ and Google Cloud PubSub, delivering messages from RabbitMQ queues to a PubSub topic.
- Ensures message ordering for each RabbitMQ queue.
- Scales horizontally across multiple nodes.
- Distribute the message pipelines evenly across the Elixir cluster.
- Gracefully handles failures and network partitions.
Many modern applications require processing large volumes of data while preserving message order from individual sources. Consider, for example, IoT systems where sensor readings must be processed in sequence, or multi-tenant applications where each tenant’s data requires sequential processing.
The solution we’ll build addresses these requirements by treating each RabbitMQ queue as an ordered data source.
Let’s explore how to design this system using Elixir’s distributed computing libraries: Broadway, Horde, and libcluster.
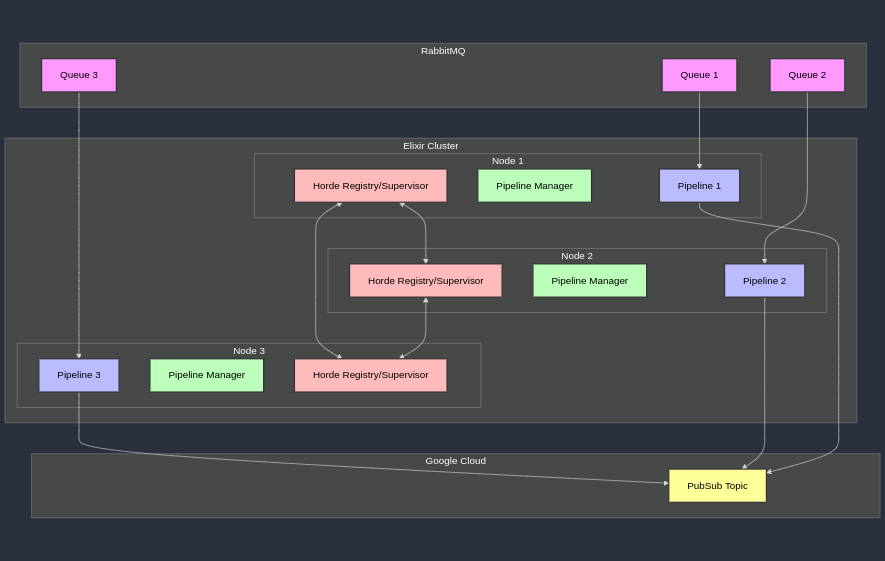
Architecture overview
The system consists of multiple Elixir nodes forming a distributed cluster. Each node runs one or more Broadway pipelines to process messages from RabbitMQ queues and forward them to Google Cloud PubSub. To maintain message ordering, each queue has exactly one pipeline instance running across the cluster at any time. If a node fails the system must redistribute its pipelines to other nodes automatically, and if a new node joins the cluster then the existing pipelines should be redistributed to ensure a balanced load.
Elixir natively supports the ability to cluster multiple nodes together so that processes and distributed components within the cluster can communicate seamlessly. We will employ the libcluster library since it provides several strategies to automatize cluster formation and healing.
For the data pipelines, the Broadway library provides a great framework to support multi-stage data processing while handling back-pressure, batching, fault tolerance and other good features.
To correctly maintain the distribution of data pipelines across the Elixir nodes, the Horde library comes to the rescue by providing the building blocks we need: a distributed supervisor that we can use to distribute and maintain healthy pipelines on the nodes, and a distributed registry that we use directly to track which pipelines exist and on which nodes they are.
Finally, a PipelineManager component will take care of monitoring RabbitMQ for new queues and starting/stopping corresponding pipelines dynamically across the cluster.
Technical implementation
Let’s initiate a new Elixir app with a supervision tree.
mix new message_pipeline --sup
First, we’ll need to add our library dependencies in mix.exs and run mix deps.get:
defmodule MessagePipeline.MixProject do
use Mix.Project
def project do
[
app: :message_pipeline,
version: "0.1.0",
elixir: "~> 1.17",
start_permanent: Mix.env() == :prod,
deps: deps()
]
end
def application do
[
extra_applications: [:logger],
mod: {MessagePipeline.Application, []}
]
end
defp deps do
[
{:libcluster, "~> 3.3"},
{:broadway, "~> 1.0"},
{:broadway_rabbitmq, "~> 0.7"},
{:google_api_pub_sub, "~> 0.34"},
{:goth, "~> 1.4"},
{:tesla, "~> 1.12"},
{:jason, "~> 1.4"},
{:amqp, "~> 4.0"}
]
end
end
Rolling our own PubSub client
Since we just need to publish messages to Google Cloud PubSub and the API is straightforward, we don’t need fancy libraries here.
Let’s start by adding Goth to the supervision tree to manage Google’s service account credentials.
defmodule MessagePipeline.Application do
use Application
def start(_type, _args) do
credentials =
"GOOGLE_APPLICATION_CREDENTIALS_PATH"
|> System.fetch_env!()
|> File.read!()
|> Jason.decode!()
children = [
{Goth, name: MessagePipeline.Goth, source: {:service_account, credentials}},
# Other children...
]
Supervisor.start_link(children, strategy: :one_for_one)
end
end
And here’s our HTTP client to publish messages to Google Cloud PubSub
defmodule MessagePipeline.GooglePubsub do
@google_pubsub_base_url "https://pubsub.googleapis.com"
def publish_messages(messages) when is_list(messages) do
project_id = System.fetch_env!("GOOGLE_PUBSUB_PROJECT_ID")
topic_name = System.fetch_env!("GOOGLE_PUBSUB_TOPIC")
topic = "projects/#{project_id}/topics/#{topic_name}"
request = %{
messages: Enum.map(messages, &%{data: Base.encode64(&1)})
}
with {:ok, auth_token} <- generate_auth_token(),
client = client(auth_token),
{:ok, response} <- Tesla.post(client, "/v1/#{topic}:publish", request) do
%{body: %{"messageIds" => message_ids}} = response
{:ok, message_ids}
end
end
defp client(auth_token) do
middleware = [
{Tesla.Middleware.BaseUrl, @google_pubsub_base_url},
Tesla.Middleware.JSON,
{Tesla.Middleware.Headers, [{"Authorization", "Bearer " <> auth_token}]}
]
Tesla.client(middleware)
end
defp generate_auth_token do
with {:ok, %{token: token}} <- Goth.fetch(MessagePipeline.Goth) do
{:ok, token}
end
end
end
Clustering with libcluster
We’ll use libcluster to establish communication between our Elixir nodes. Here’s an example configuration that uses the Gossip strategy to form a cluster between nodes:
defmodule MessagePipeline.Application do
use Application
def start(_type, _args) do
topologies = [
gossip_example: [
strategy: Elixir.Cluster.Strategy.Gossip
]
]
children = [
{Cluster.Supervisor, [topologies, [name: MessagePipeline.ClusterSupervisor]]},
# Other children...
]
Supervisor.start_link(children, strategy: :one_for_one)
end
end
Distributed process management with Horde
We’ll use Horde to manage our Broadway pipelines across the cluster. Horde ensures that each pipeline runs on exactly one node and handles redistribution when nodes fail.
Let’s add Horde’s supervisor and registry to the application’s supervision tree.
The UniformQuorumDistribution distribution strategy distributes processes using a hash mechanism among all reachable nodes. In the event of a network partition, it enforces a quorum and will shut down all processes on a node if it is split from the rest of the cluster: the unreachable node is drained and the pipelines can be resumed on the other cluster nodes.
defmodule MessagePipeline.Application do
use Application
def start(_type, _args) do
children = [
{Horde.Registry, [
name: MessagePipeline.PipelineRegistry,
members: :auto,
keys: :unique
]},
{Horde.DynamicSupervisor, [
name: MessagePipeline.PipelineSupervisor,
members: :auto,
strategy: :one_for_one,
distribution_strategy: Horde.UniformQuorumDistribution
]}
# Other children...
]
Supervisor.start_link(children, strategy: :one_for_one)
end
end
Broadway pipeline implementation
Each pipeline uses Broadway to consume messages from RabbitMQ and publish them to Google PubSub.
A strict, per-queue ordering is guaranteed by setting a concurrency of 1.
defmodule MessagePipeline.Pipeline do
use Broadway
alias Broadway.Message
def child_spec(opts) do
queue_name = Keyword.fetch!(opts, :queue_name)
pipeline_name = pipeline_name(queue_name)
%{
id: pipeline_name,
start: {__MODULE__, :start_link, opts}
}
end
def start_link(opts) do
queue_name = Keyword.fetch!(opts, :queue_name)
pipeline_name = pipeline_name(queue_name)
pipeline_opts = [
name: {:via, Horde.Registry, {MessagePipeline.PipelineRegistry, pipeline_name}},
producer: [
module: {
BroadwayRabbitMQ.Producer,
queue: queue_name,
connection: [
host: System.fetch_env!("RABBITMQ_HOST"),
port: String.to_integer(System.fetch_env!("RABBITMQ_PORT")),
username: System.fetch_env!("RABBITMQ_USER"),
password: System.fetch_env!("RABBITMQ_PASSWORD")
]
},
concurrency: 1
],
processors: [
default: [
concurrency: 1
]
],
batchers: [
default: [
batch_size: 100,
batch_timeout: 200,
concurrency: 1
]
]
]
case Broadway.start_link(__MODULE__, pipeline_opts) do
{:ok, pid} ->
{:ok, pid}
{:error, {:already_started, _pid}} ->
:ignore
end
end
def pipeline_name(queue_name) do
String.to_atom("pipeline_#{queue_name}")
end
@impl true
def handle_message(_, message, _) do
message
|> Message.update_data(&process_data/1)
end
@impl true
def handle_batch(_, messages, _, _) do
case publish_to_pubsub(messages) do
{:ok, _message_ids} -> messages
{:error, reason} ->
# Mark messages as failed
Enum.map(messages, &Message.failed(&1, reason))
end
end
defp process_data(data) do
# Transform message data as needed
data
end
defp publish_to_pubsub(messages) do
MessagePipeline.GooglePubsub.publish_messages(messages)
end
end
Queue discovery and pipeline management
Finally, we need a process to monitor RabbitMQ queues and ensure pipelines are running for each one.
The Pipeline Manager periodically queries RabbitMQ for existing queues. If a new queue appears, it starts a Broadway pipeline only if one does not already exist in the cluster. If a queue is removed, the corresponding pipeline is shut down.
defmodule MessagePipeline.PipelineManager do
use GenServer
@timeout :timer.minutes(1)
def start_link(opts) do
GenServer.start_link(__MODULE__, opts, name: __MODULE__)
end
def init(_opts) do
state = %{managed_queues: MapSet.new()}
{:ok, state, {:continue, :start}}
end
def handle_continue(:start, state) do
state = manage_queues(state)
{:noreply, state, @timeout}
end
def handle_info(:timeout, state) do
state = manage_queues(state)
{:noreply, state, @timeout}
end
def manage_queues(state) do
{:ok, new_queues} = discover_queues()
current_queues = state.managed_queues
queues_to_add = MapSet.difference(new_queues, current_queues)
queues_to_remove = MapSet.difference(current_queues, new_queues)
Enum.each(queues_to_add, &start_pipeline/1)
Enum.each(queues_to_remove, &stop_pipeline/1)
%{state | managed_queues: new_queues}
end
defp discover_queues do
{:ok, conn} =
AMQP.Connection.open(
host: System.fetch_env!("RABBITMQ_HOST"),
port: String.to_integer(System.fetch_env!("RABBITMQ_PORT")),
username: System.fetch_env!("RABBITMQ_USER"),
password: System.fetch_env!("RABBITMQ_PASSWORD")
)
{:ok, chan} = AMQP.Channel.open(conn)
{:ok, queues} = AMQP.Queue.list(chan)
# Filter out system queues
queues
|> Enum.reject(fn %{name: name} ->
String.starts_with?(name, "amq.") or
String.starts_with?(name, "rabbit")
end)
|> Enum.map(& &1.name)
|> MapSet.new()
end
defp start_pipeline(queue_name) do
pipeline_name = MessagePipeline.Pipeline.pipeline_name(queue_name)
case Horde.Registry.lookup(MessagePipeline.PipelineRegistry, pipeline_name) do
[{pid, _}] ->
{:error, :already_started}
[] ->
Horde.DynamicSupervisor.start_child(
MessagePipeline.PipelineSupervisor,
{MessagePipeline.Pipeline, queue_name: queue_name}
)
end
end
defp stop_pipeline(queue_name) do
pipeline_name = MessagePipeline.Pipeline.pipeline_name(queue_name)
case Horde.Registry.lookup(MessagePipeline.PipelineRegistry, pipeline_name) do
[{pid, _}] ->
Horde.DynamicSupervisor.terminate_child(MessagePipeline.PipelineSupervisor, pid)
[] ->
{:error, :not_found}
end
end
end
Let’s not forget to also add the pipeline manager to the application’s supervision tree.
defmodule MessagePipeline.Application do
use Application
def start(_type, _args) do
children = [
{MessagePipeline.PipelineManager, []}
# Other children...
]
Supervisor.start_link(children, strategy: :one_for_one)
end
end
Test the system
We should now have a working and reliable system. To quickly test it out, we can configure a local RabbitMQ broker, a Google Cloud PubSub topic, and finally a couple of Elixir nodes to verify that distributed pipelines are effectively run to forward messages between RabbitMQ queues and PubSub.
Let’s start by running RabbitMQ with the management plugin. RabbitMQ will listen for connections on the 5672 port, while also exposing the management interface at http://localhost:15672. The default credentials are guest/guest.
docker run -d --name rabbitmq \
-p 5672:5672 \
-p 15672:15672 \
rabbitmq:3-management
Next, install and use the gcloud CLI to create a Google Cloud project, a PubSub topic, and a a service account to access PubSub programmatically.
# Login to Google Cloud
gcloud auth login
# Create a new project (or use an existing one)
gcloud projects create message-pipeline-test
gcloud config set project message-pipeline-test
# Enable PubSub API
gcloud services enable pubsub.googleapis.com
# Create a topic
gcloud pubsub topics create test-topic
# Create service account for local testing
gcloud iam service-accounts create local-test-sa
# Generate and download credentials
gcloud iam service-accounts keys create ./google-credentials.json \
--iam-account local-test-sa@message-pipeline-test.iam.gserviceaccount.com
# Grant publish permissions
gcloud pubsub topics add-iam-policy-binding test-topic \
--member="serviceAccount:local-test-sa@message-pipeline-test.iam.gserviceaccount.com" \
--role="roles/pubsub.publisher"
It’s now time to start two terminal sessions where we can export the needed environment variables before running two Elixir nodes.
# In terminal 1
export RABBITMQ_HOST=localhost
export RABBITMQ_PORT=5672
export RABBITMQ_USER=guest
export RABBITMQ_PASSWORD=guest
export GOOGLE_PUBSUB_PROJECT_ID=message-pipeline-test
export GOOGLE_PUBSUB_TOPIC=test-topic
export GOOGLE_APPLICATION_CREDENTIALS_PATH=$(pwd)/google-credentials.json
export RELEASE_COOKIE=my-secret-cookie
iex --sname node1 -S mix
# In terminal 2 (same variables)
export RABBITMQ_HOST=localhost
export RABBITMQ_PORT=5672
export RABBITMQ_USER=guest
export RABBITMQ_PASSWORD=guest
export GOOGLE_PUBSUB_PROJECT_ID=message-pipeline-test
export GOOGLE_PUBSUB_TOPIC=test-topic
export GOOGLE_APPLICATION_CREDENTIALS_PATH=$(pwd)/google-credentials.json
export RELEASE_COOKIE=my-secret-cookie
iex --sname node2 -S mix
To verify cluster formation, from one of the nodes:
# List all nodes in the cluster, should show the other node
Node.list()
# Check Horde supervisor distribution
:sys.get_state(MessagePipeline.PipelineSupervisor)
Now let’s create some test queues on RabbitMQ and start publishing some messages.
# Download rabbitmqadmin if not already available
wget http://localhost:15672/cli/rabbitmqadmin
chmod +x rabbitmqadmin
# Create queues
./rabbitmqadmin declare queue name=test-queue-1
./rabbitmqadmin declare queue name=test-queue-2
# Publish test messages
./rabbitmqadmin publish routing_key=test-queue-1 payload="Message 1 for queue 1"
./rabbitmqadmin publish routing_key=test-queue-1 payload="Message 2 for queue 1"
./rabbitmqadmin publish routing_key=test-queue-2 payload="Message 1 for queue 2"
# List queues and their message counts
./rabbitmqadmin list queues name messages_ready messages_unacknowledged
# Get messages (without consuming them)
./rabbitmqadmin get queue=test-queue-1 count=5 ackmode=reject_requeue_true
One can also use the RabbitMQ management interface at http://localhost:15672, authenticate with the guest/guest default credentials, go to the “Queues” tab, click “Add a new queue”, and create “test-queue-1” and “test-queue-2”.
After a minute, the Elixir nodes should automatically start some pipelines corresponding to the RabbitMQ queues.
# List all registered pipelines
Horde.Registry.select(MessagePipeline.PipelineRegistry, [{{:"$1", :"$2", :"$3"}, [], [:"$2"]}])
# Check specific pipeline
pipeline_name = :"pipeline_test-queue-1"
Horde.Registry.lookup(MessagePipeline.PipelineRegistry, pipeline_name)
Now, if we publish messages on the RabbitMQ queues, we should see them appear on the PubSub topic.
We can verify it from Google Cloud Console, or by creating a subscription, publishing some messages on RabbitMQ, and then pulling messages from the PubSub subscription.
gcloud pubsub subscriptions create test-sub --topic test-topic
# ...Publish messages on RabbitMQ queues...
gcloud pubsub subscriptions pull test-sub --auto-ack
If we stop one of the Elixir nodes (Ctrl+C twice in its IEx session) to simulate a failure, the pipelines should be redistributed in the remaining node:
# Check updated node list
Node.list()
# Check pipeline distribution
Horde.Registry.select(MessagePipeline.PipelineRegistry, [{{:"$1", :"$2", :"$3"}, [], [:"$2"]}])
Rebalancing pipelines on new nodes
With our current implementation, pipelines are automatically redistributed when a node fail but they are not redistributed when a new node joins the cluster.
Fortunately, Horde supports precisely this functionality from v0.8+, and we don’t have to manually stop and re-start our pipelines to have them landing on other nodes.
All we need to do is enable the option process_distribution: :active on Horde’s supervisor to automatically rebalance processes on node joining / leaving. The option runs each child spec through the choose_node/2 function of the preferred distribution strategy, detects which processes should be running on other nodes considering the new cluster configuration, and specifically restarts those particular processes such that they run on the correct node.
defmodule MessagePipeline.Application do
use Application
def start(_type, _args) do
children = [
{Horde.Registry, [
name: MessagePipeline.PipelineRegistry,
members: :auto,
keys: :unique
]},
{Horde.DynamicSupervisor, [
name: MessagePipeline.PipelineSupervisor,
members: :auto,
strategy: :one_for_one,
distribution_strategy: Horde.UniformQuorumDistribution,
process_redistribution: :active
]}
# Other children...
]
Supervisor.start_link(children, strategy: :one_for_one)
end
end
Conclusion
This architecture provides a robust solution for processing ordered message streams at scale. The combination of Elixir’s distributed capabilities, Broadway’s message processing features, and careful coordination across nodes enables us to build a system that can handle high throughput while maintaining message ordering guarantees.
To extend this solution for your specific needs, consider these enhancements:
- Adopt a libcluster strategy suitable for a production environment, such as Kubernetes.
- Tune queue discovery latency, configuring the polling interval based on how frequently new queues are created. Better yet, instead of polling RabbitMQ, consider setting up RabbitMQ event notifications to detect queue changes in real-time.
- Declare AMQP queues as durable and make sure that publishers mark published messages as persisted, in order to survive broker restarts and improve delivery guarantees. Use publisher confirms to ensure messages are safely received by the broker. Deploy RabbitMQ in a cluster with queue mirroring or quorum queues for additional reliability.
- Add monitoring, instrumenting Broadway and Horde with Telemetry metrics.
- Enhance error handling and retry mechanisms. For example, retry message publication to PubSub N times before failing the messages, thus invalidating the (possibly costly) processing operation.
- Unit & e2e testing. Consider that the gcloud CLI (gcr.io/google.com/cloudsdktool/google-cloud-cli:emulators) contains a PubSub emulator that may come in handy: e.g. gcloud beta emulators pubsub start — project=test-project — host-port=0.0.0.0:8085
- Leverage an HorizontalPodAutoscaler for automated scaling on Kubernetes environments based on resource demand.
- Evaluate the use of Workload Identities if possible. For instance, you can provide your workloads with access to Google Cloud resources by using federated identities instead of a service account key. This approach frees you from the security concerns of manually managing service account credentials.