Friday, 16 June 2023

There’s no better measure of success than having a diminutive eight-year-old girl demand to know the name of the painting program she has been using for the last 20 minutes.

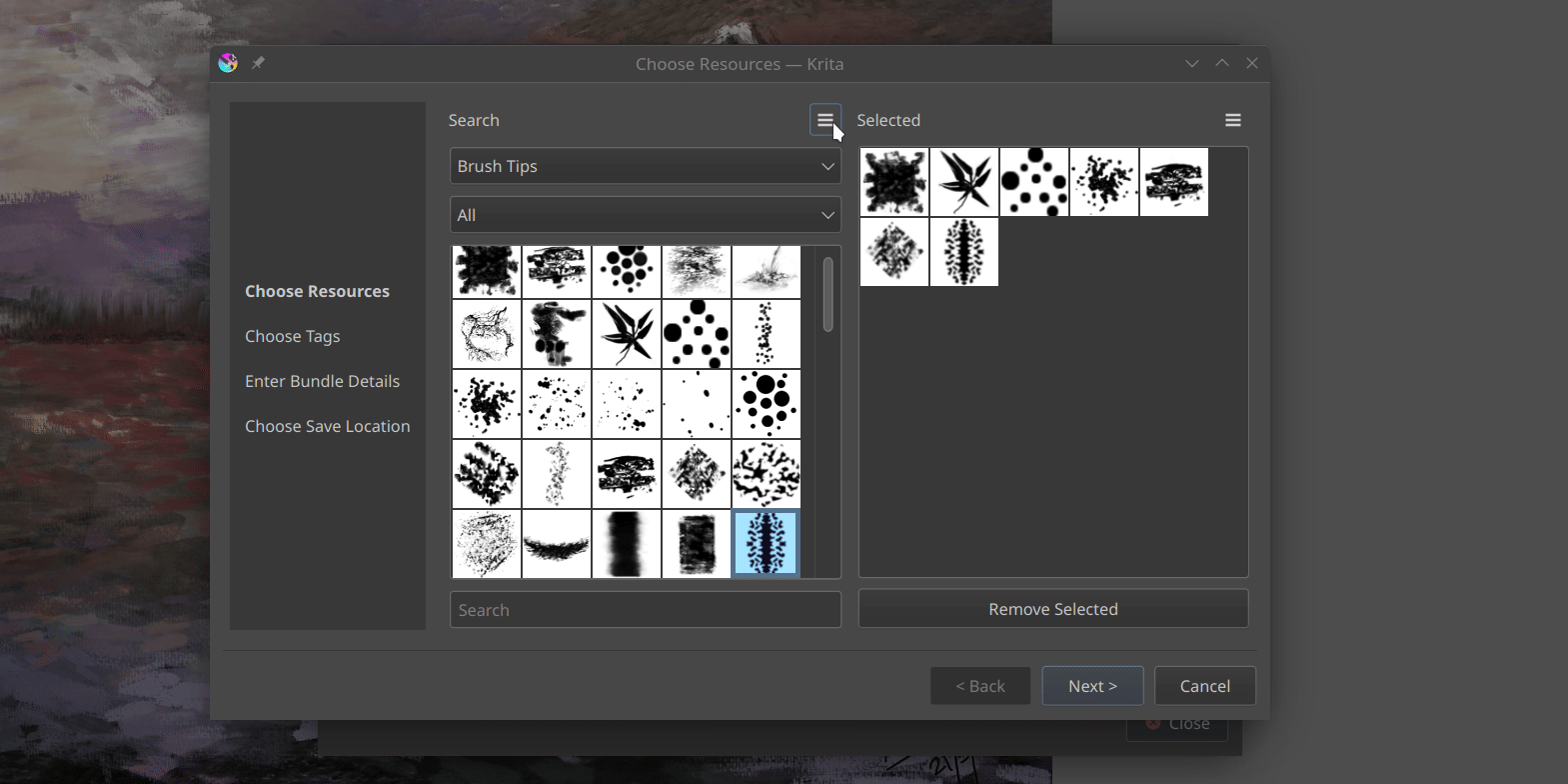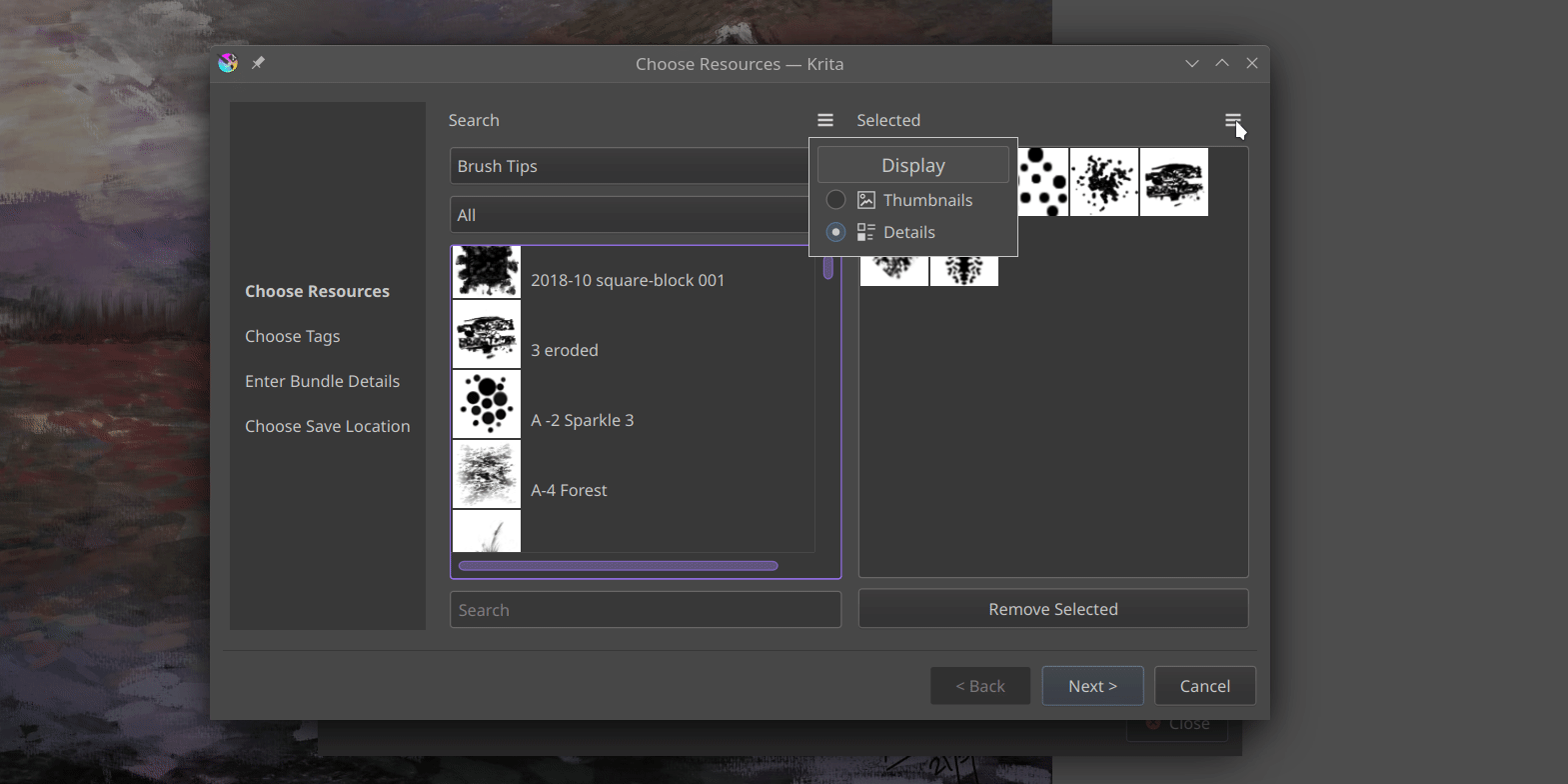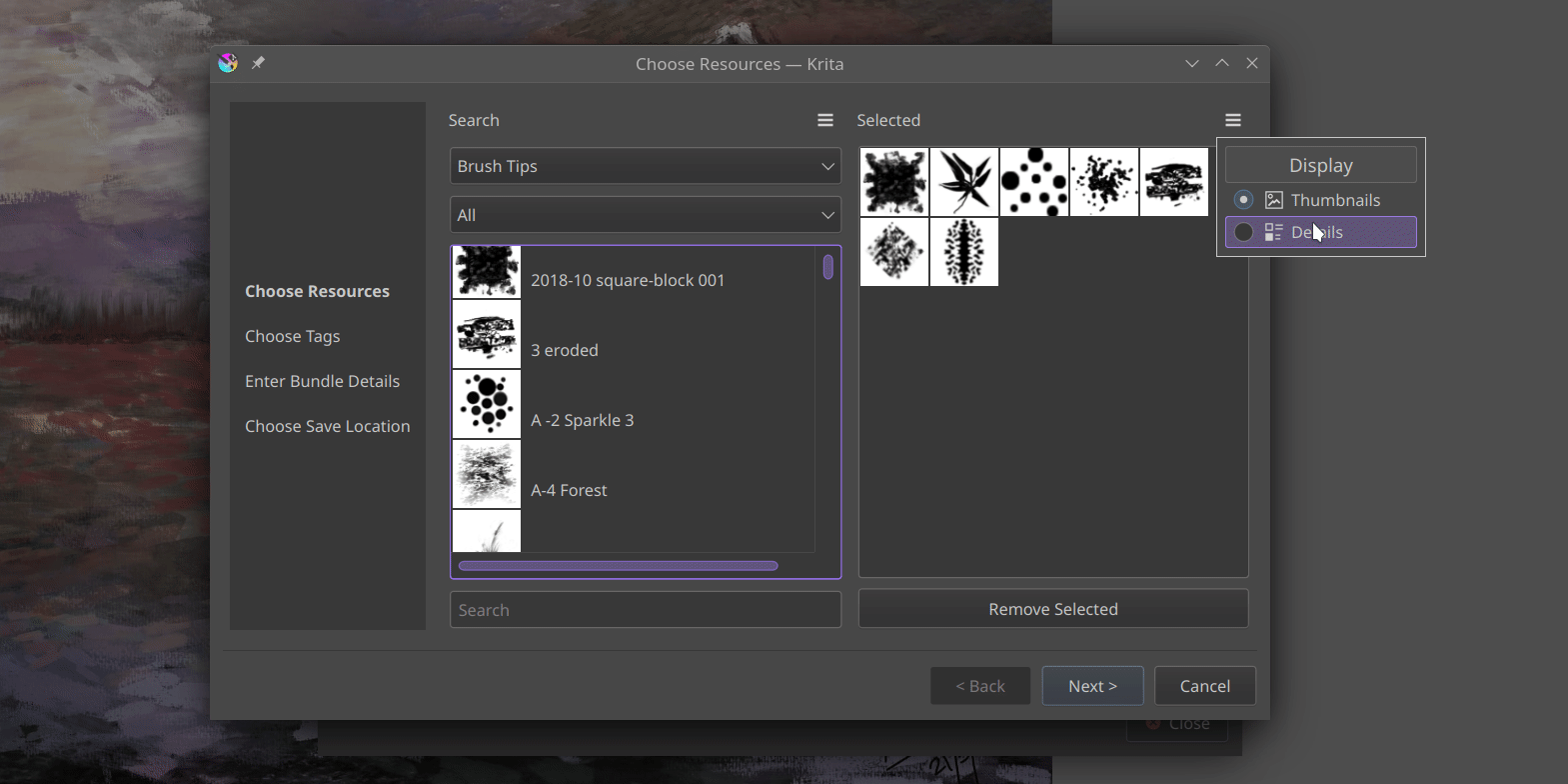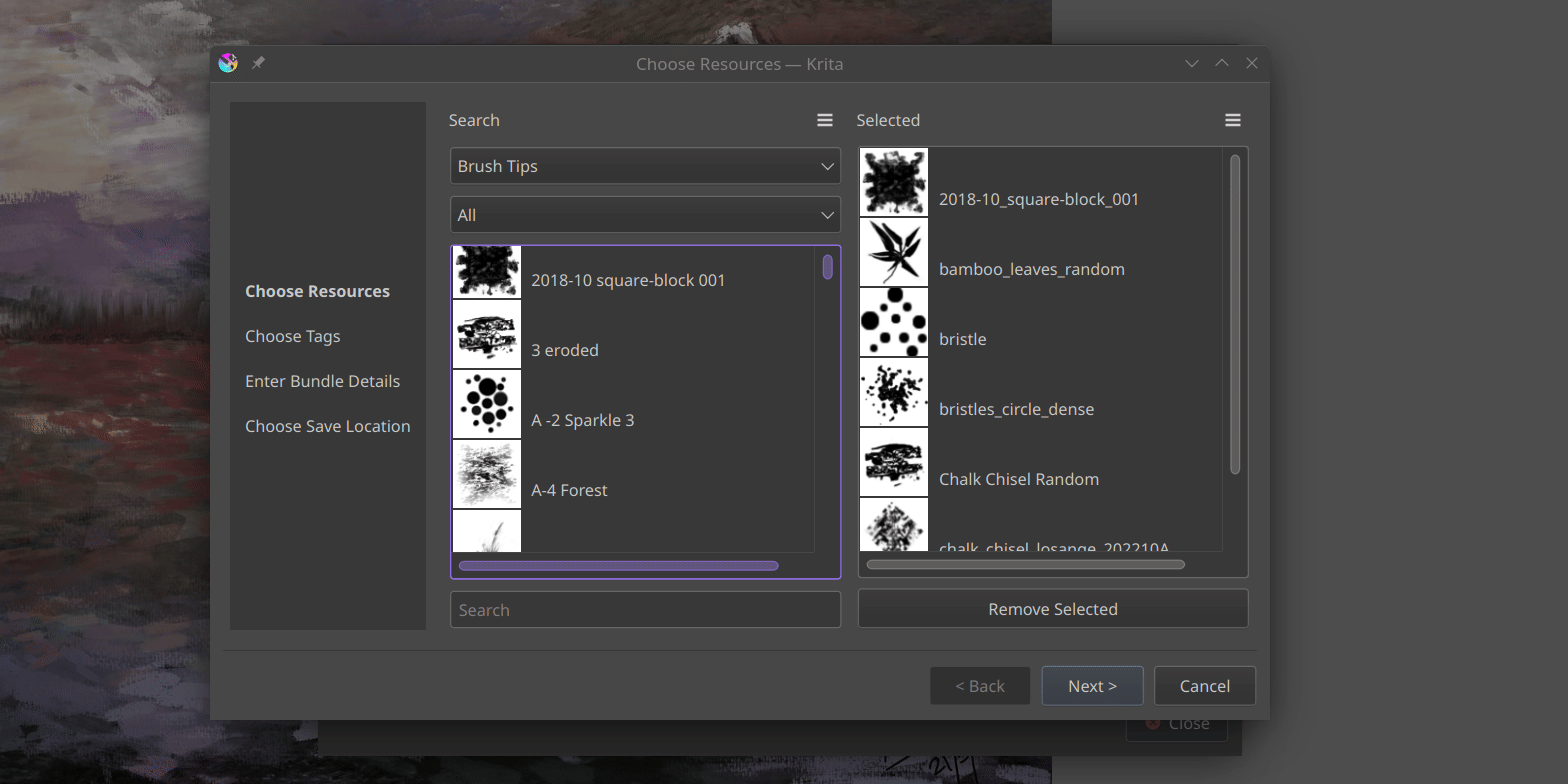
Welcome back! Last time, I successfully completed the development of the Bundle Creator up to the Resource Chooser page. This page now allows us to easily select resource items by applying filters based on tags or names. I’ve introduced some UI improvements, including the ability to click-to-select, the addition of a convenient Remove Selected button and the introduction of a visually appealing grid view to replace the traditional list view. These enhancements enhance the overall user experience and provide a more streamlined resource selection process.
As mentioned in previous blog posts, the Bundle Creator consists of four pages: the Resource Chooser, Tag Chooser, Bundle Details, and Save to pages. These pages can be seen in the wizard’s side widget, and users can navigate between them using the Next and Back buttons. The Tag Chooser page retains a similar design to the Embed Tags page from the previous version of the bundle creator. It offers a familiar interface for users to select and embed tags to their new bundle. Similarly, the Bundle Details page maintains consistency with the previous bundle creator, where one can fill out the bundle name, author, website etc.
The inclusion of the Save to Page adds a crucial final step to the bundle creation process. It provides a summary of the bundle details, which includes the number of selected resource items per resource type, and the tags chosen for embedding. This comprehensive summary allows users to review and confirm their bundle’s content before finalizing the creation process.
By dividing the bundle creation process into these distinct and user-friendly pages, particularly for beginners, the Bundle Creator offers a streamlined and intuitive experience. Users can efficiently navigate through each step, making informed decisions and customizing their bundles according to their specific needs.
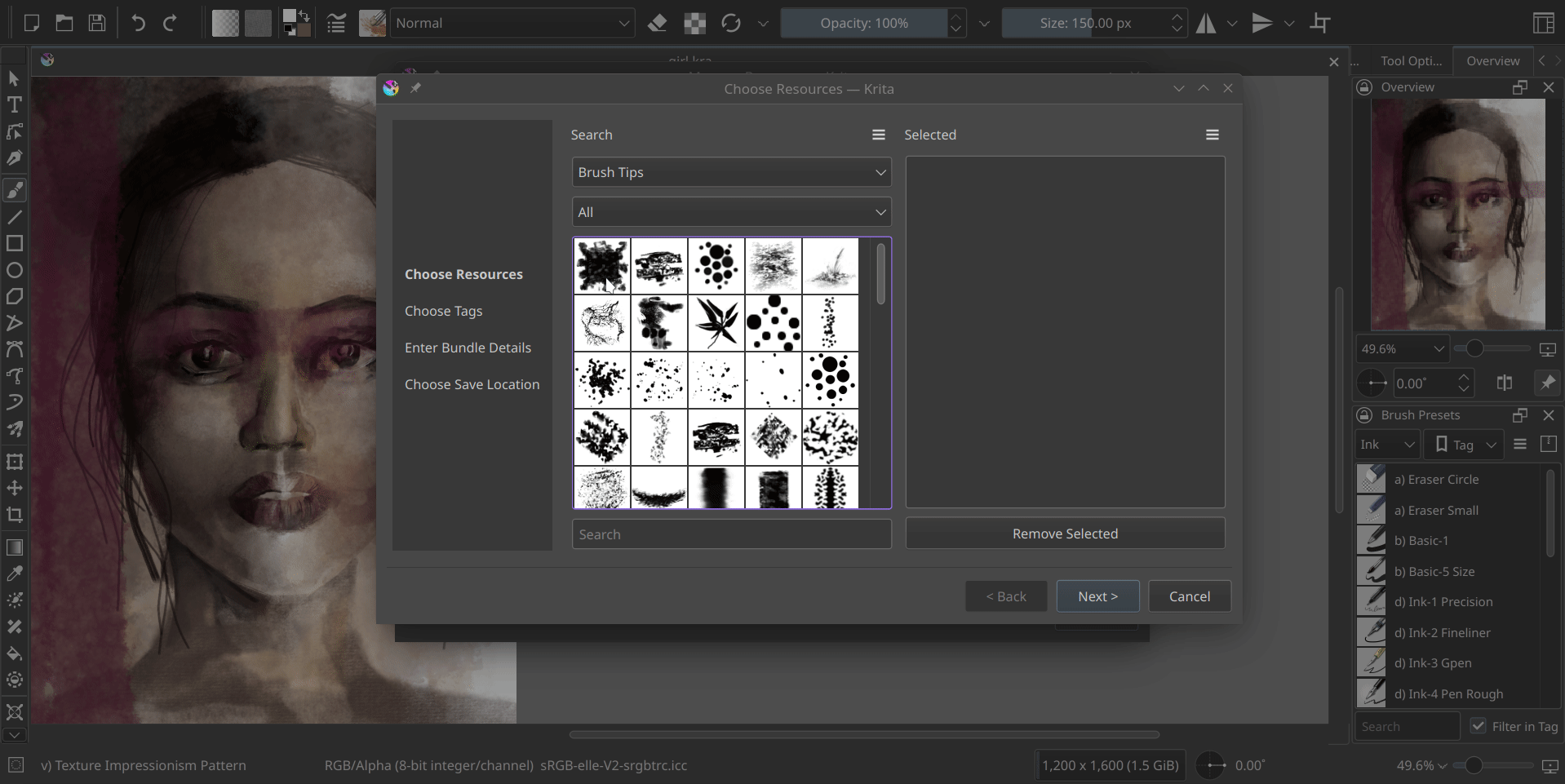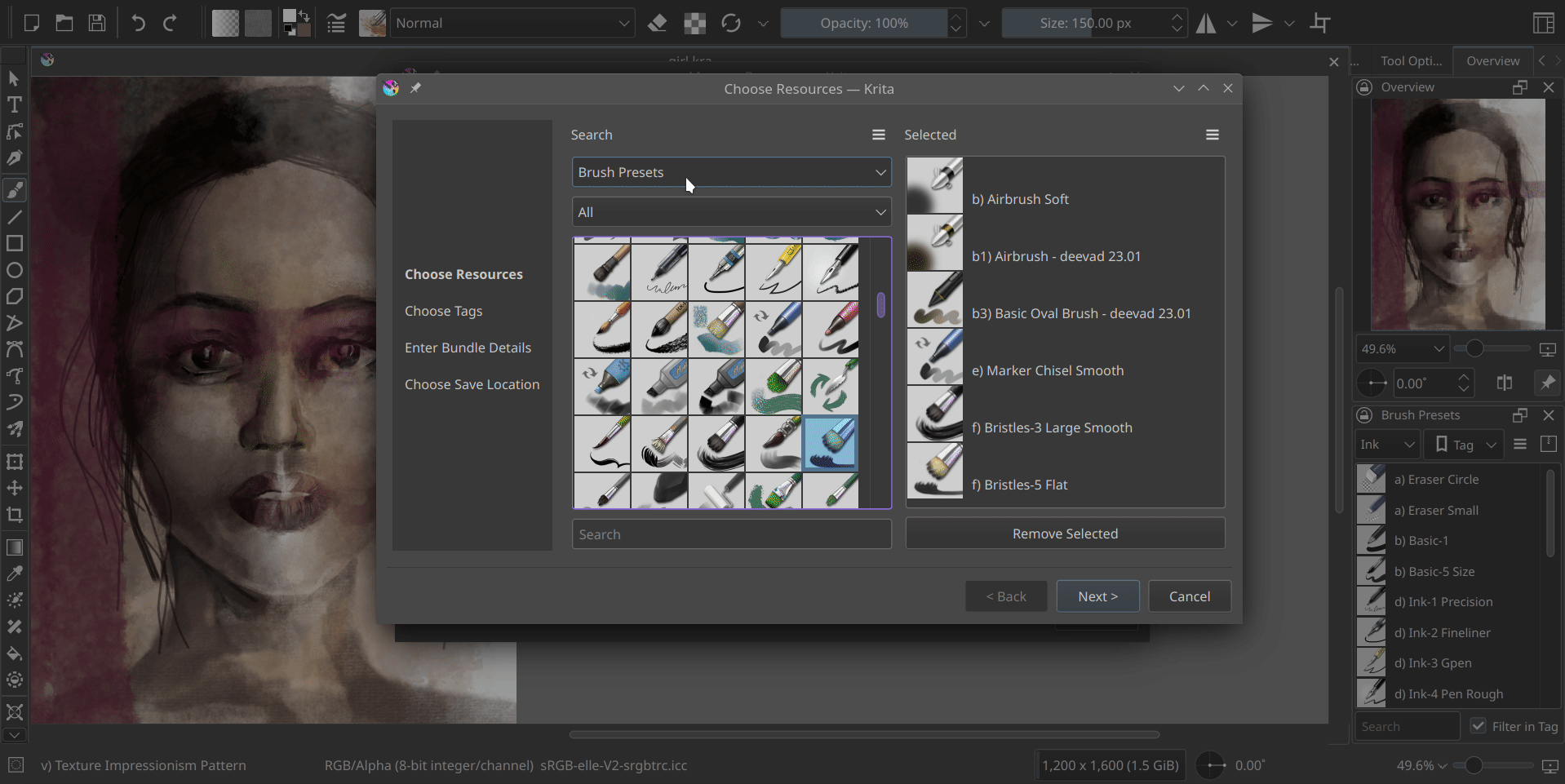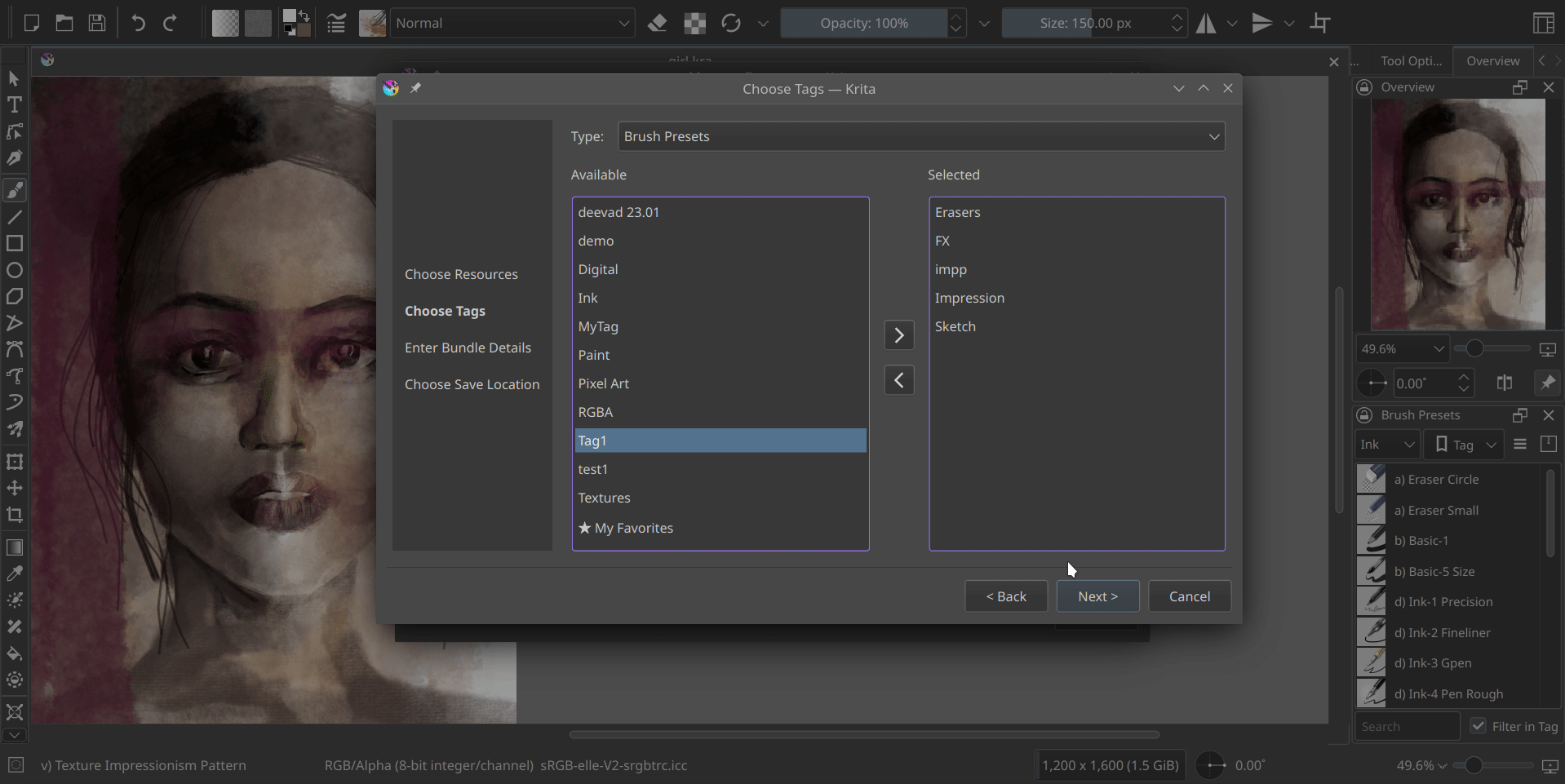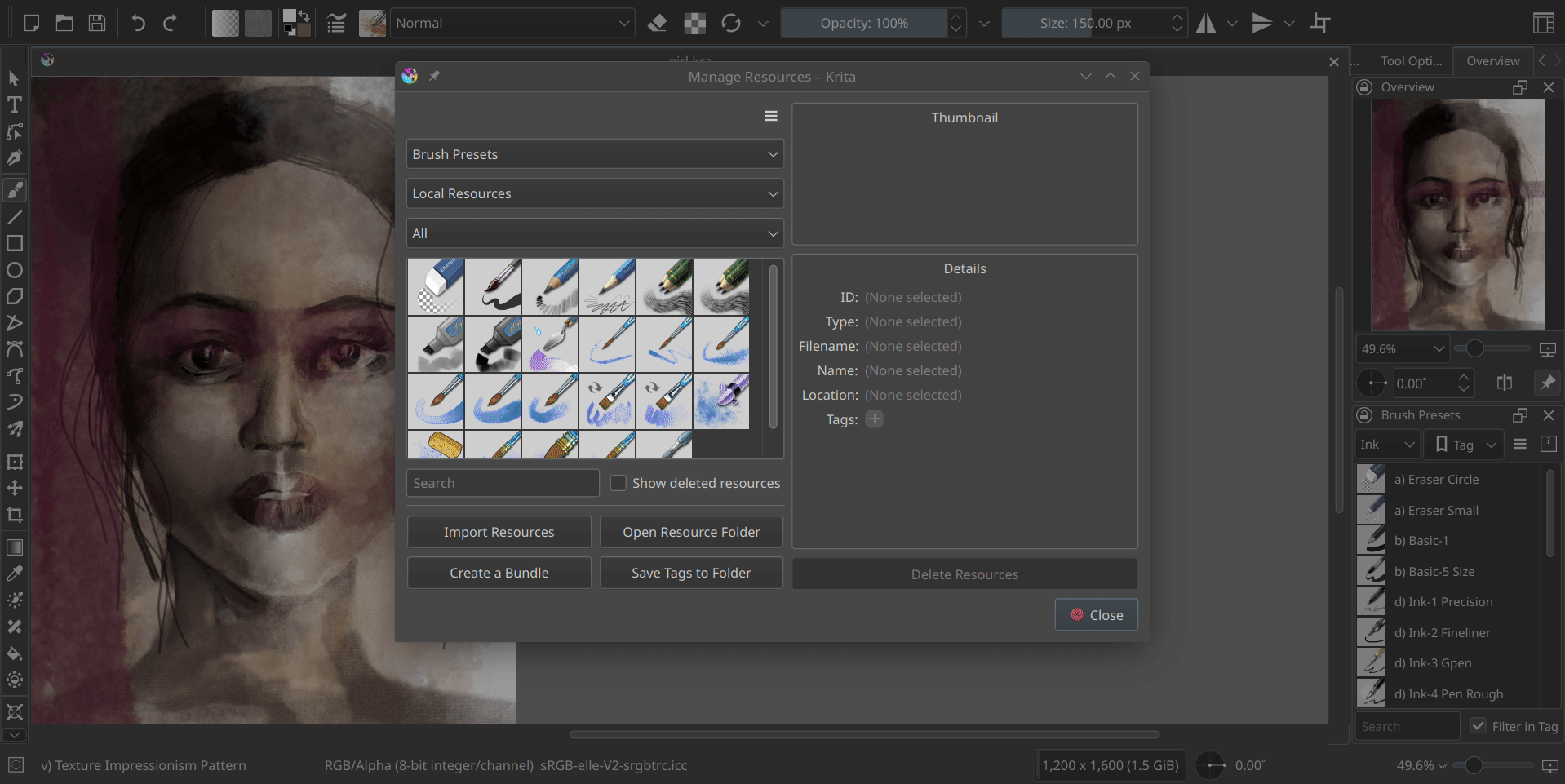
I have added a small tool button that allows switching between grid view and list view in both the resource manager and bundle creator, providing convenience to the users. Additionally, I have made the icons in the bundle creator more consistent.
My merge request can be viewed here.
In the upcoming weeks, I would be working on adding the editing bundles feature, as well as improving the Choose Tags section. This requires some UI related feedback, and if you’re interested to help out, please feel free to drop a comment on this post I created on Krita Artists Forum!
Hello world,
This is my third blog post for Google Summer of Code 2023 where I will be sharing what I was able to accomplish in the first two weeks.
The first task I worked on was implementing the account moderation tool. This tool enables moderators/admins of an instance to view all the accounts available on the server and take action against them.
Before starting with its implementation, I requested Carl to schedule a meeting so that I could gain a better understanding of the implementation process. He advised me to study the already implemented SocialGraph page, along with other helpful insights.
Initially, when attempting to receive raw JSON data from the /api/v1/admin/accounts endpoint, I encountered a 403 error response. Upon spending some time debugging my code I couldn’t determine what I was doing wrong and so I finally resorted to asking for help in the Tokodon matrix chat, where redstrate❣️ helped me identify that we didn’t have the necessary scope set in Tokodon to access admin endpoints.
After setting the correct scope, I was finally able to make network requests to the admin endpoint 🥳. I decided to implement a QAbstractListModel to expose all the data and required properties in the QML UI. With this in mind, I created a new class AccountsToolModel that inherited from QAbstractListModel. For making all the filter options functional I created QProperty instances with the necessary READ, WRITE and NOTIFY methods.
To display the admin-related information for an account, I parsed the received JSON data and created a new method AbstractAccount::adminIdentityLookup which will populate QProperty instances of AdminAccountInfo to store all the required information for the moderation tool. Once all the cpp backend was ready, I started with the qml implementation, figuring out the best way in which the data can be presented.
Once the UI was implemented, I encountered an issue with pagination not functioning correctly. After debugging the issue, I discovered that when requesting a response for the next page using the v2 endpoint, the response received was actually v1. This discrepancy messed up the query parameters and rendered pagination impossible. To address this issue, I implemented a simple code block: url = url.toString().replace("/v1/", "/v2/");. This replacement fixed the problem and allowed proper pagination to occur.
To ensure the issue was addressed, I reported it on Mastodon’s GitHub repository. You can find the detailed report here.
At the end of the first two weeks the initial page of Account Moderation tool was implemented whose Merge Request can be tracked here. I also made significant progress towards developing next page of the account tool during these weeks.
Images showing implemented Account Moderation tool

Next I am working on implementing the second page of account Moderation tool and report Moderation tool :)
I will be writing regular blog posts on my website. You can read my previous blog-posts and follow my progress here
I’m happy to announce the 1.1 release of Arianna. Arianna is a small ePub reader application I started with Niccolo some time ago. Like most of my open source applications, it is built on top of Qt and Kirigami.
Arianna is both an ePub viewer and a library management app. Internally, Arianna uses Baloo to find your existing ePub files in your device and categorize them.
Arianna can now display the table of content of a book. This supports complex hierarchies of headings.
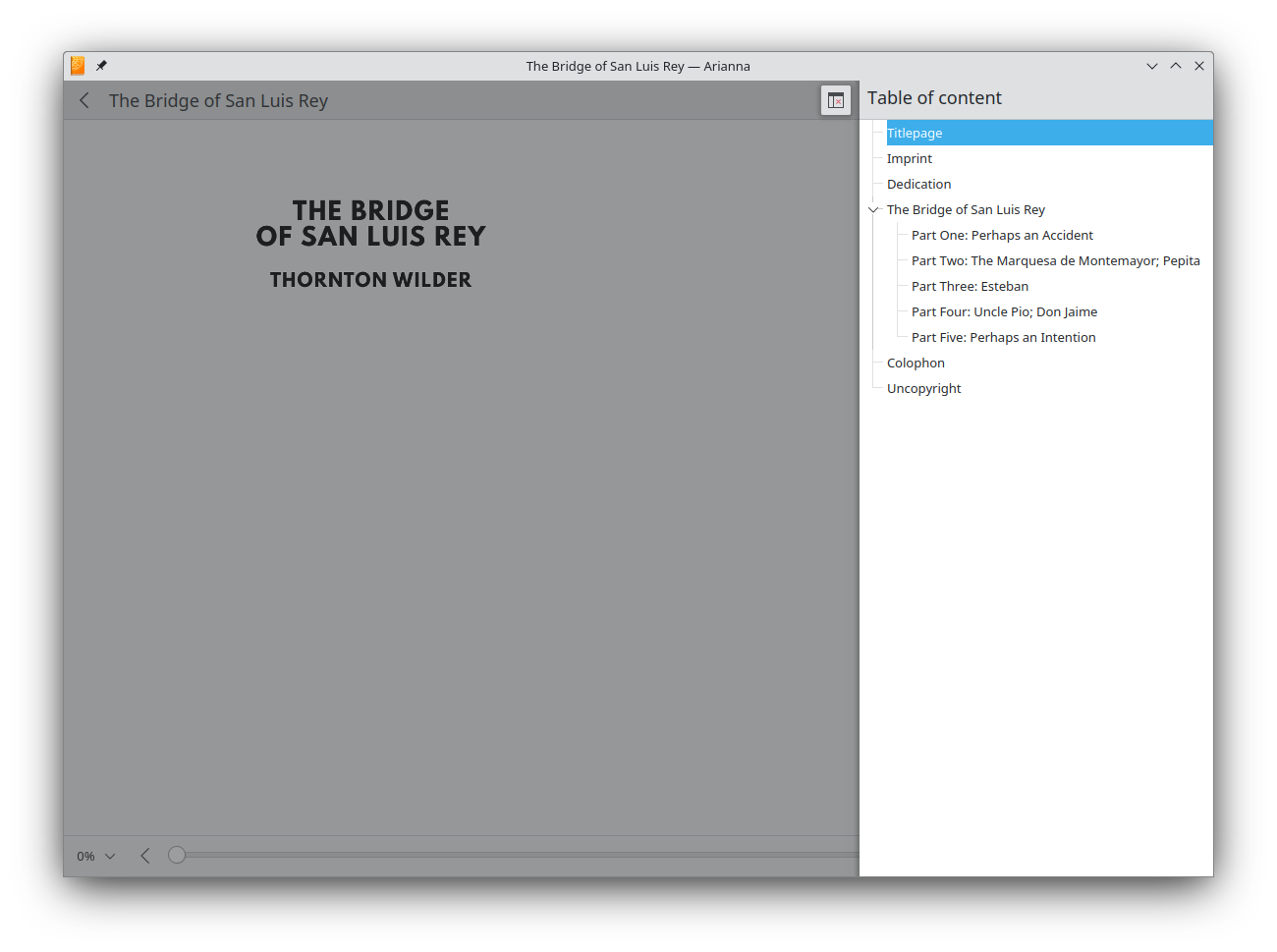
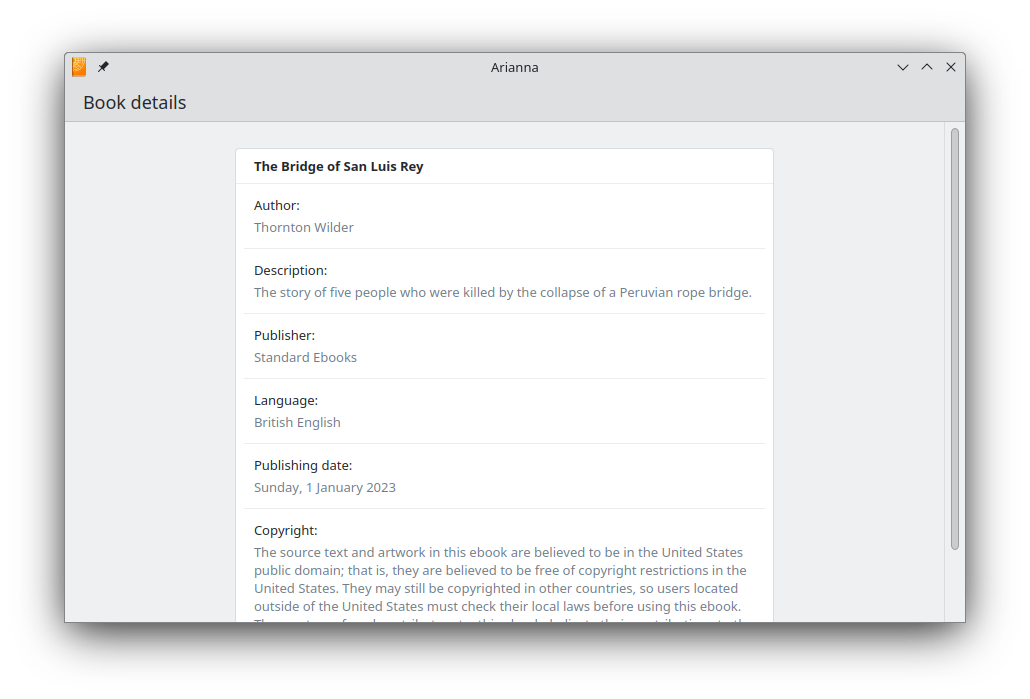
Arianna now provides you with the metadata about your books.
Additionally, you can now disable the reading progress on the library page if it distracts you.
You can now read books without requiring an internet connection. We also fixed various crashes happening when indexing your books.
If you are interested in helping, don’t hesitate to reach out in the Arianna matrix channel (#arianna:kde.org) and I will be happy to guide you.
I also regularly post about my progress on Arianna (and other KDE apps) on my Mastodon account, so don’t hesitate to follow me there ;) We also now have an official Mastodon account for Arianna @arianna@kde.social.
And in case you missed it, as a member of KDE’s fundraising working group, I need to remind you that KDE e.V., the non-profit behind the KDE community accepts donations.
You can find the package on download.kde.org and it has been signed with my GPG key.
Hello world,
This is my second blog post for Google Summer of Code 2023, where I will share what I accomplished during the GSoC-23 community bonding period.
During this time GSoC contributors spend 3 weeks learning about their organization’s community and preparing for their coding project. They get to know mentors, read documentation, get up to speed to begin working on their projects
During the community bonding period, the organizers took two introductory sessions kick starting our journey. The first Welcome Session was about the best practices and tips for a successful Google Summer of Code. Following that, GSoC Contributor Summit took place, during which previous participants and mentors shared their experiences of being part of GSoC.
During this time I also got to interact with fellow GSoC contributors and learned more about their interesting projects and their plans .
Furthermore, I utilized this time to get a head-start on my project by familiarizing myself with QT’s model-view programming with the help of official QT's documentation and Tokodon’s source code. Additionally, I implemented the User-Interface of the button to be used to open the moderation tool. The merge request for which can be found here.
An image showing the User Interface of Tokodon with implemented entry point of moderation Tool can be found below.

Next I am working on implementing the account Moderation tool :)
I will be writing regular blog posts on my website. You can read my previous blog-posts and follow my progress here
I have a few blog posts planned, but the one I wanted to post involving KDE color schemes isn’t finished yet (it’s enormous and tedious). So instead, today I’m showing you how simple it is to compile Kirigami with Qt6 so you can start playing with it ahead of time.
Kirigami, KDE’s library that extends QtQuick, is a Tier 1 KDE Framework. The cool thing about it is that it has effectively no dependency on any KDE libraries. It depends only on two things: Qt and extra-cmake-modules (ECM).

Today we are releasing GCompris version 3.3.
This version adds translations for 2 more languages: Arabic and Esperanto.
It contains bug fixes on multiple activities such as "Path encoding", "Letter in word", "Ballcatch" and "Piano composition".
Some improvements of keyboard handling (shortcuts, focus...) have been done on several activities.
It also contains new graphics and improvements on "Photo hunter".
It is fully translated in the following languages:
It is also partially translated in the following languages:
You can find packages of this new version for GNU/Linux, Windows, Raspberry Pi and macOS on the download page. This update will be available soon in the Android Play store, the F-Droid repository and the Windows store.
Thank you all,
Timothée & Johnny

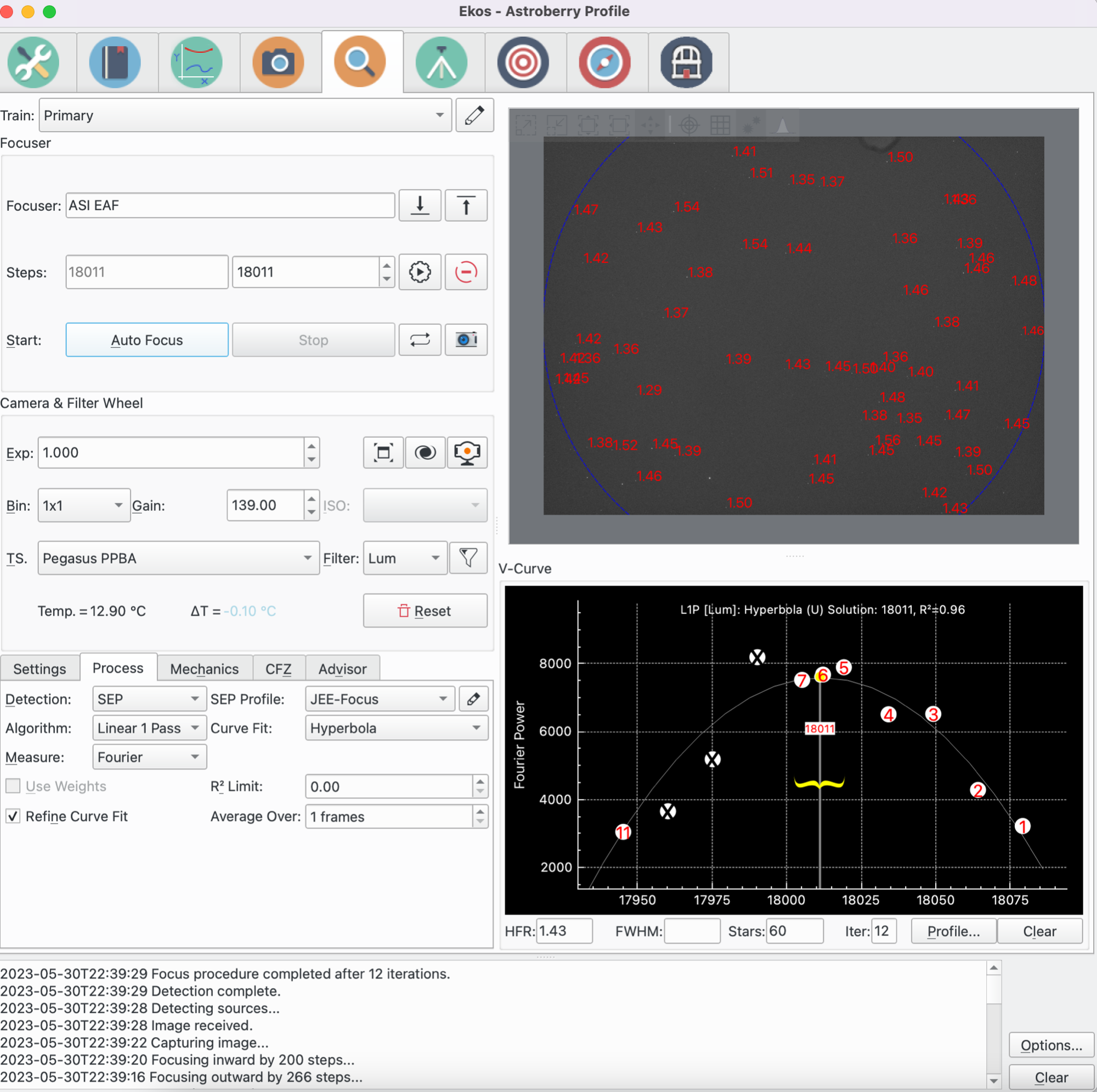
Implementation of an optimal sub-exposure calculator based upon the work of, and presentation by, Dr Robin Glover. The calculator considers multiple inputs to determine a sub-exposure time which will provide minimal overall noise in the image:

As inputs are adjusted the calculator will refresh graphic presentation of potential exposure times of the range of gains, and update calculated outputs. The output values are separated into two sections: one for the sub-exposure, and another for image stacks of various integration times.
The sub-exposure outputs are:
The image stack information is presented in a table showing:
An instance of the sub-exposure calculator can be started from a new 'clock' icon on the ekos capture screen. Multiple instances of the sub-exposure calculator can be started concurrently so that side-by-side comparisons can be made for variations in inputs.
Data for camera read-noise will be provided through individual xml files which will be user maintained and published in a repository. These camera data files persisted within a folder "exposure_calculator" under user/local/share/kstars. The calculator includes the capability to download camera files from a repository. Upon the initial start of the calculator at least one camera data file download will be mandatory before the calculator can be instantiated.
The intent is that camera data file names will be used to allow the calculator to select an appropriate camera data file based upon the device id of the active camera. (But some of the initial camera files were named using educated guesses, and will likely need to be re-named).

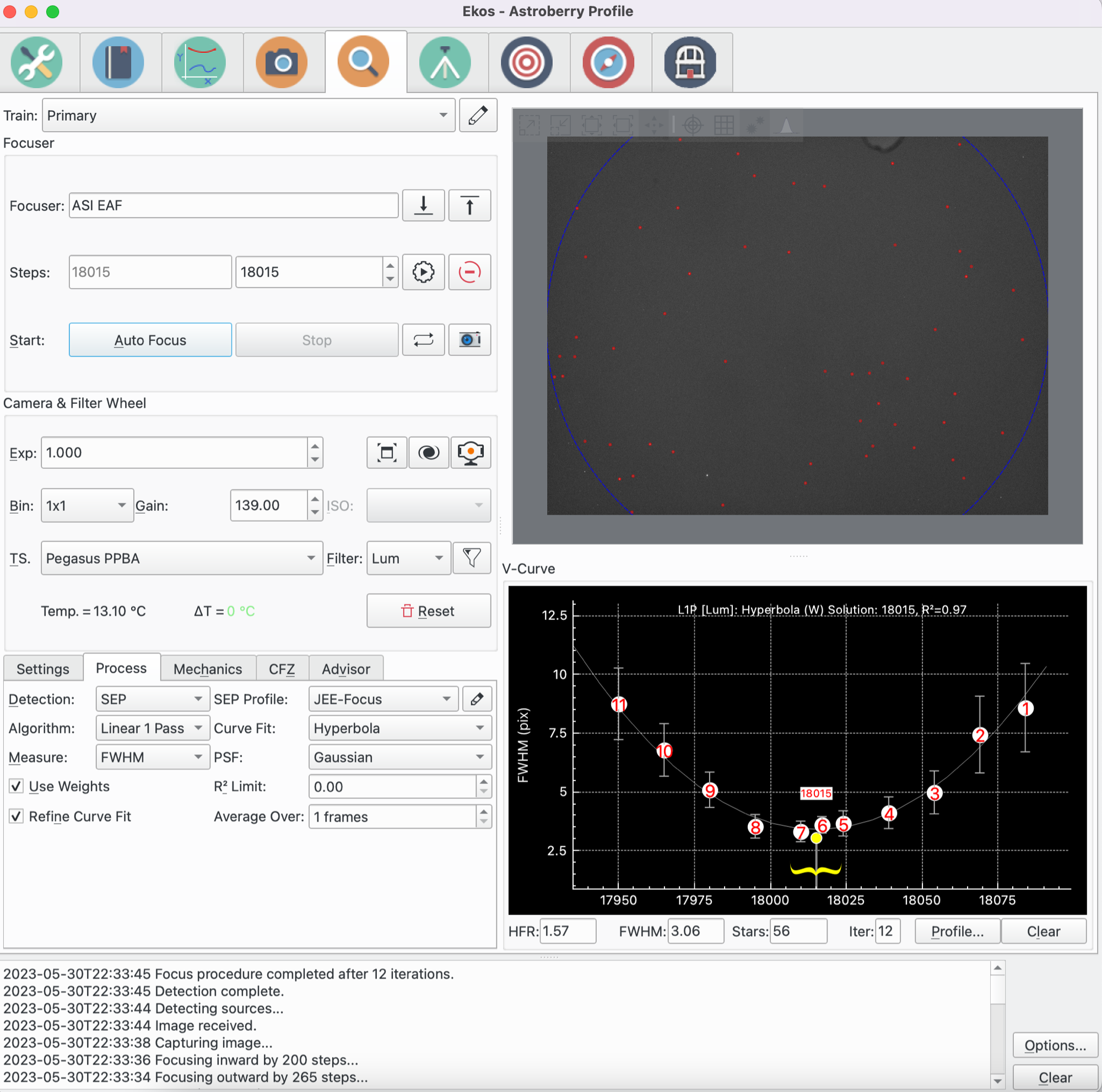
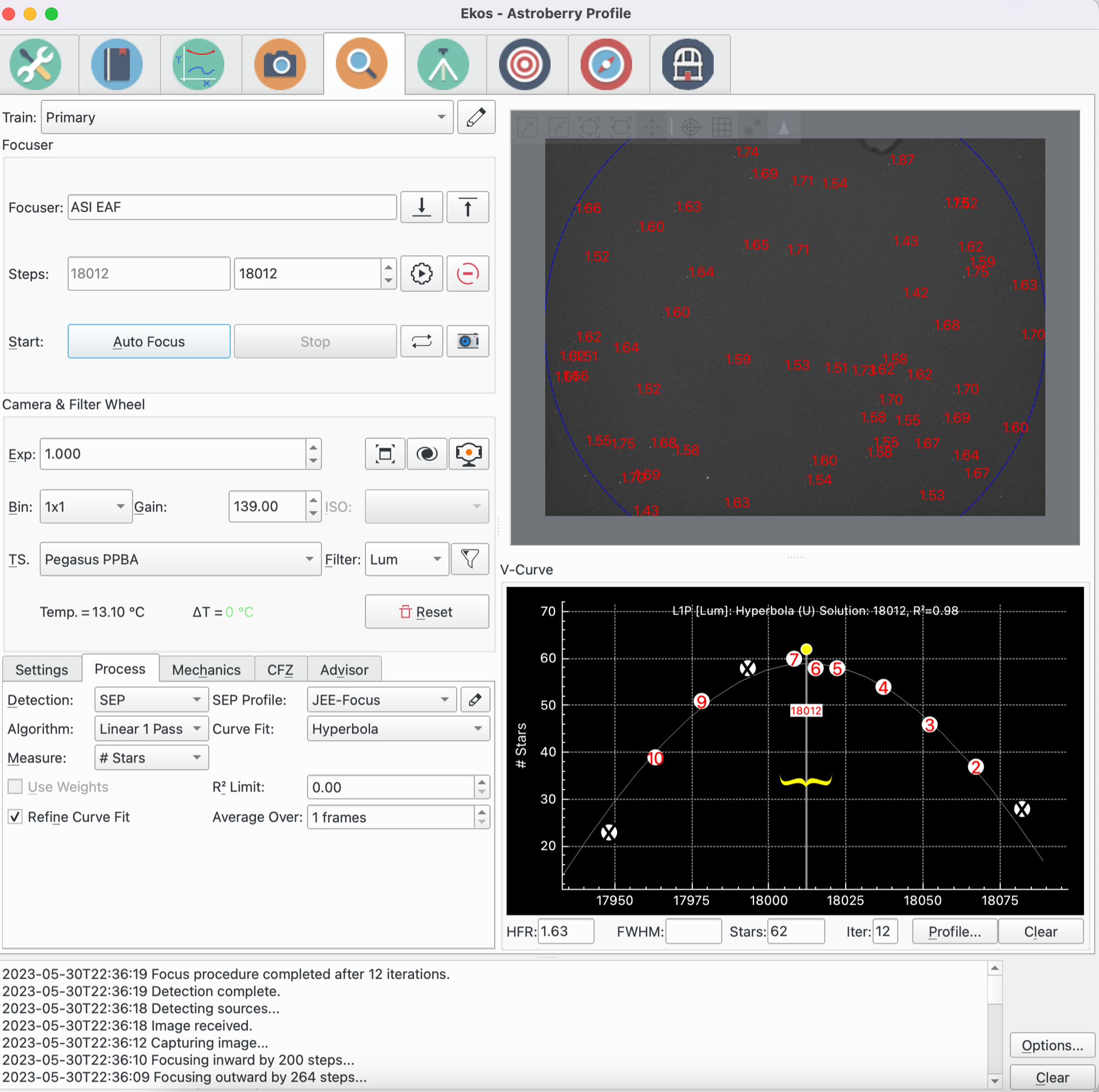
Wolfgang Reissenberger introduced the mosaic view well known from PixInsight's AberrationInspector script that builds a mosaic from all image corners and center tiles such that they can be compared directly.

I can’t believe it’s already the end of May! This month turned out a little meatier than last month I think, but I still have a large backlog of merge requests and TODOs to go through.
[Feature] Now when there isn’t enough space to display the QR code in the clipboard applet, there is a clearer message of what to do next.

[Bugfix] On the topic of QR codes, the menu is now a menu of radio buttons and not checkboxes which didn’t make sense because it’s an exclusive option.

[Feature] There is now a separator above the “Close” action in the window menu!

[Feature] I added a metadata extractor for Krita files, which means certain information about your Krita artwork can show up in Dolphin, Baloo and other programs that can take advantage of it! This includes helpful information such as canvas width, height and creation date.

[Feature]
Soon, the Language and Region settings will support the $LANGUAGE environment variable. This only affects users who did not configure the language explicitly from KDE, like those coming from another computing environment. We already supported loading your pre-existing language from $LANG. Included in that merge request is a fix that stops an erroneous warning message telling you that your language isn’t supported, even though it clearly is.
[Feature]
For new users of the Plasma SDK, there is now a clearer and more helpful message when you start plasmoidviewer without an applet specified.
$ plasmoidviewer
An applet name or path must be specified, e.g. --applet org.kde.plasma.analogclock
[Feature] I proposed making the icon name selectable, because I can’t stop myself from clicking on it!

Jeremy Whiting has been hard at work improving the backend code, and I finally took a shot at creating a proper art prototype of the controller that will be featured in the KCM.
Unable to find image concept.PNG!This will be the base image for the different controller types, and it will change depending on what controller we detect. Neither of us are experts in Inkscape, so we plan for the this to be easily tweakable by actual designers who do not need to know the fine details of the KCM. This is possible because we’re also developing an Inkscape extension to automate exporting SVG files into QML templates that describe button, trigger positions and so on.
The concept is already working in the KCM, but it looks a little off right now and isn’t ready for showcasing yet :-)
[Feature] Many users (including myself) have been experiencing crashes because of the video support added in the last release. QtMultimedia - the library we used for video support - in Qt5 is frustratingly buggy, but has improved in Qt6. Unfortunately, we still have a few more months before KDE Gear applications like Tokodon can switch to Qt6 only and we need a solution for the crashes now. I started porting Tokodon’s video support to mpv which is also used in PlasmaTube!
Playing videos and GIFs should be less crashy, but with worse scrolling performance. However, I worked hard to make sure this only affects auto-play, so if you don’t that option enabled then you shouldn’t notice a difference. This change is almost ready and should appear in the next release, but it lacks testing on Android.
[Feature] You can now change certain account preferences, but the selection is limited due to lack of a proper API. These are preferences that were supported before, but now you can change them from within Tokodon.

And a whole slew of smaller stuff, some which are appearing in the next bugfix release:

[Feature] For the current and future contributors, I started working on better and more detailed documentation. The first two areas I covered was timeline models and the account classes!
[Feature] In terms of starting even more future work, I started implementing QtKeychain support, and rewriting the current, and buggy, account saving mechanism with KConfig. This will hopefully land in the next release, and fix a whole slew of nagging security and account duplication bugs.
If you’ve been noticing that qqc2-desktop-style on Plasma 6 is spitting out some weird stuff in your logs:
Warning: file:///home/josh/kde6/usr/lib/qml/org/kde/desktop/private/MobileCursor.qml:33:13: Unable to assign [undefined] to bool (file:///home/josh/kde6/usr/lib/qml/org/kde/desktop/private/MobileCursor.qml:33, )
Warning: file:///home/josh/kde6/usr/lib/qml/org/kde/desktop/private/MobileCursor.qml:33:13: Unable to assign [undefined] to bool (file:///home/josh/kde6/usr/lib/qml/org/kde/desktop/private/MobileCursor.qml:33, )
Warning: file:///home/josh/kde6/usr/lib/qml/org/kde/desktop/private/MobileCursor.qml:33:13: Unable to assign [undefined] to bool (file:///home/josh/kde6/usr/lib/qml/org/kde/desktop/private/MobileCursor.qml:33, )
Warning: file:///home/josh/kde6/usr/lib/qml/org/kde/desktop/private/MobileCursor.qml:33:13: Unable to assign [undefined] to bool (file:///home/josh/kde6/usr/lib/qml/org/kde/desktop/private/MobileCursor.qml:33, )
[Bugfix] I fixed that! It also needs these ECM changes to work. It turns out ECMQmlModule didn’t handle singleton types, and other nagging problems that qqc2-desktop-style needed. I’ve been dabbling in this module for the past month or so so it’s exciting to be able to help here.
I took some time to improve the codebase of our Japanese reference tool Kiten, because it seems to have not been very active the past few years. I think it was written before we used C++11. I found a bunch of places where 0 was used to set pointers to null!
I started replacing the old foreach macro, use auto to prevent duplicate types and other modern C++ gardening tasks.
The go.kde.org Matrix redirector update is now merged, which I started in February. This means NeoChat is now preferred right below Element Web (which is still pointed towards https://webchat.kde.org/ ). Thanks to Thiago Sueto, the Community Wiki has been updated already and I sent two merge requests to update kde.org and the footer.

To finish off more February work, I got around to working on the two big pieces of API documentation improvements for KDE Frameworks 6. If you don’t remember, I wanted to add import statements for components meant to be used in Qt Quick. Doxygen already gives us hints for C++ headers, so QML users shouldn’t be left in the dust. For example, how are you even supposed to use this component?

In order to accomplish this, subclasses of QQuickItem need to have their doc comments modified. The first library to get this treatment is plasma-framework, see the merge requests for PlasmaCore, PlasmaQuick and hiding ToolTipDialog.
For regular QML-based components, doxyqml (the tool to auto-generate QML documentation, because Doxygen lacks support for the language) needed to spit these out too. The merge request to add import statements is cleaned up, the tests fixed and ready for final review!

I also spent some time cleaning up the Community wiki, which just means I roam around and make sure links aren’t dead and the formatting looks nice. If you’re interested in some wiki improvement, join us in #kde-www and the Issue board!
I was recently researching how well Tokodon works out of the box on other desktop environments. It turns out 90% of issues with Kirigami applications can be solved by installing breeze-icons and qqc2-desktop-style! We might be enforcing this soon, so if you are in charge of packaging Kirigami applications, please make add them as weak or required dependencies! I will probably start filing packaging bugs soon.
In terms of KDE packaging issues in distributions, I opened up two this month:
I’m also attending Akademy this year in Thessaloniki! My passport was delivered this month, which is strangely hard to get in the USA (currently.)
I finally got the passport today! Pretty happy that I no longer have to worry about this little book :bunhdgoogly:
I booked my accommodations last week, so I’m excited to see everyone in-person in July! This is my first time traveling outside of the North American continent, and to Europe no less. I’ll be documenting my experience traveling and at Akademy, but I’m not sure what format it’ll be in yet.
Like or comment on this postHello, Tech enthusiasts! I am beyond excited to introduce to you my first project on GitHub – a Bash-based Telegram Bot that allows you to monitor and control a remote computer!
The idea behind this bot is pretty simple, yet powerful – you can command your PC, retrieve important system information, perform updates and even control system processes directly from your Telegram app. I’ve designed this bot with KDE Neon in mind, but it can be adapted to other Linux-based systems.
Here’s a sneak peek into some of the key functionalities provided by the bot:
function getBattery {
local percentage=$(upower -i /org/freedesktop/UPower/devices/battery_BAT0 | grep percentage | awk ‘{print $2}’)
echo “Battery level: $percentage”
}function getCpuUsage {
local usage=$(top -bn1 | grep “Cpu(s)” | \
sed “s/.*, *([0-9.])% id.*/\1/” | \
awk ‘{print 100 – $1″%”}’)
echo “CPU Usage: $usage”
}
The bot responds to a set of predefined commands that range from simple system status checks like /battery, /status, /uptime, /memory, /disk, /cpu_usage to more complex functionalities such as /shutdown, /upgrade, /screenshot, and so on.
For the bot to run, it requires some prerequisites like curl, jq, bc among others. Some commands also require specific programs to be installed on your system.
The code is still in its initial version (0.1) and there might be some bugs on certain commands. But I am enthusiastic about making it better with every iteration. Future enhancements include multi-language support and other features based on user feedback.
I encourage you to give it a try, and would greatly appreciate your feedback. Feel free to report any issues, or suggest enhancements on the project’s GitHub page.
Here’s the link to the project on GitHub: telegram-remote-bash
Happy Coding!

 @sriru:matrix.org
@sriru:matrix.org GSoC
GSoC

 CarlSchwan
CarlSchwan



