I’m super excited to finally announce the start of the submission process for the brand new KDE Goals!
Starting today, you can submit a new proposal on the workboard and shape the future direction of the KDE community.
This stage in the process lasts 4 weeks, but don’t wait until the last moment! Submit early, and use the remaining time to listen to feedback, refine and update the proposal. Only the submission with good descriptions will move to the next stage: the community vote.
To make things easier, a template ticket is provided that you have to copy and fill out with your content. This way, none of the important parts of a good proposal will be skipped, and there will be consistency between the different proposals.
You will need an account to create a new proposal, and then use the arrow in the “Not ready for voting” column to create a new task. Don’t forget to copy the description from the template!
Remember, by submitting a Goal proposal, you are also submitting yourself as the Goal Champion for it. A Goal Champion is sort of the face of the Goal and the motivator of the initiative, but not necessarily the one that implements most of the tasks. After all, this is a community Goal, so a good Champion will motivate others to join in and help achieve amazing things.
If you want to learn more about the whole process, see the wiki for more details.
Don’t wait, submit your proposal and who knows, perhaps your idea will be announced as one of the new Goals during Akademy 2022!
This is definitely well put, users shouldn’t feel entitled. Maintainers do what they can (even if there’s a company backing up your favorite FOSS project) and if you use the software for free with no support contract… things will be done when they’re done.
I didn’t know about the Lindy effect, this is an interesting point. Obviously I have a different setup (Plasma has been around longer than XMonad after all) but the overall advice is good.
Good ideas to improve your user stories. I often see not so complete stories, it doesn’t stop at the title, there’s more to do. The proposed canvas is interesting and definitely helps.
This is my third post during Google Summer of Code 2022.
During the first week of coding period, I tried my hands at adding a horizontally scrolling bar on top of room list, which would show user's joined spaces.
The first ended in failure, because I was used to using setContext() for controlling QML via C++. NeoChat uses a different method of exposing classes though. Tobias helped me understand the method NeoChat uses.
I gave the thing another try and got some success this time.
I added a new role in roomlistmodel, named IsSpaceRole. This calls the function isSpace() from neochatroom. The function checks room creation event and determines if a given room is space or not.
On the UI part, there was a horizontal scrolling UI module used elsewhere, which I reused.
When it came to integrating the UI component into actual Room List Page, things again took a hit. My first try was to wrap Room List and Space List into a Row layout. That made the Room List not show rooms, and only the categories.
I was suggested by Carl to put Space list as header of the Scrollable Page. Doing so gave better result, apart from the fact that Space list now overlaps with Room List.
Tobias suggested that specifying height of the Space List should fix that. I also need to fix the issue of invisible rooms taking up width in Space list.
For the coming week, I plan to implement room filtering, such that when user clicks on a certain Space, then only the room corresponding to that Space are visible.
During my long train trip to the Linux App Summit 2022, I started
working on a contact book feature in Kalendar. There was already a small contact integration in
the event editor to select attendees for an event and I wanted to extend it with a simple contact
info viewer and editor.
When I started it, I was full of hope that this would be a simple task and would be easy to
finish. Unfortunately more than one month later, it’s not finished but there is a lot of progress
that I can already show off.
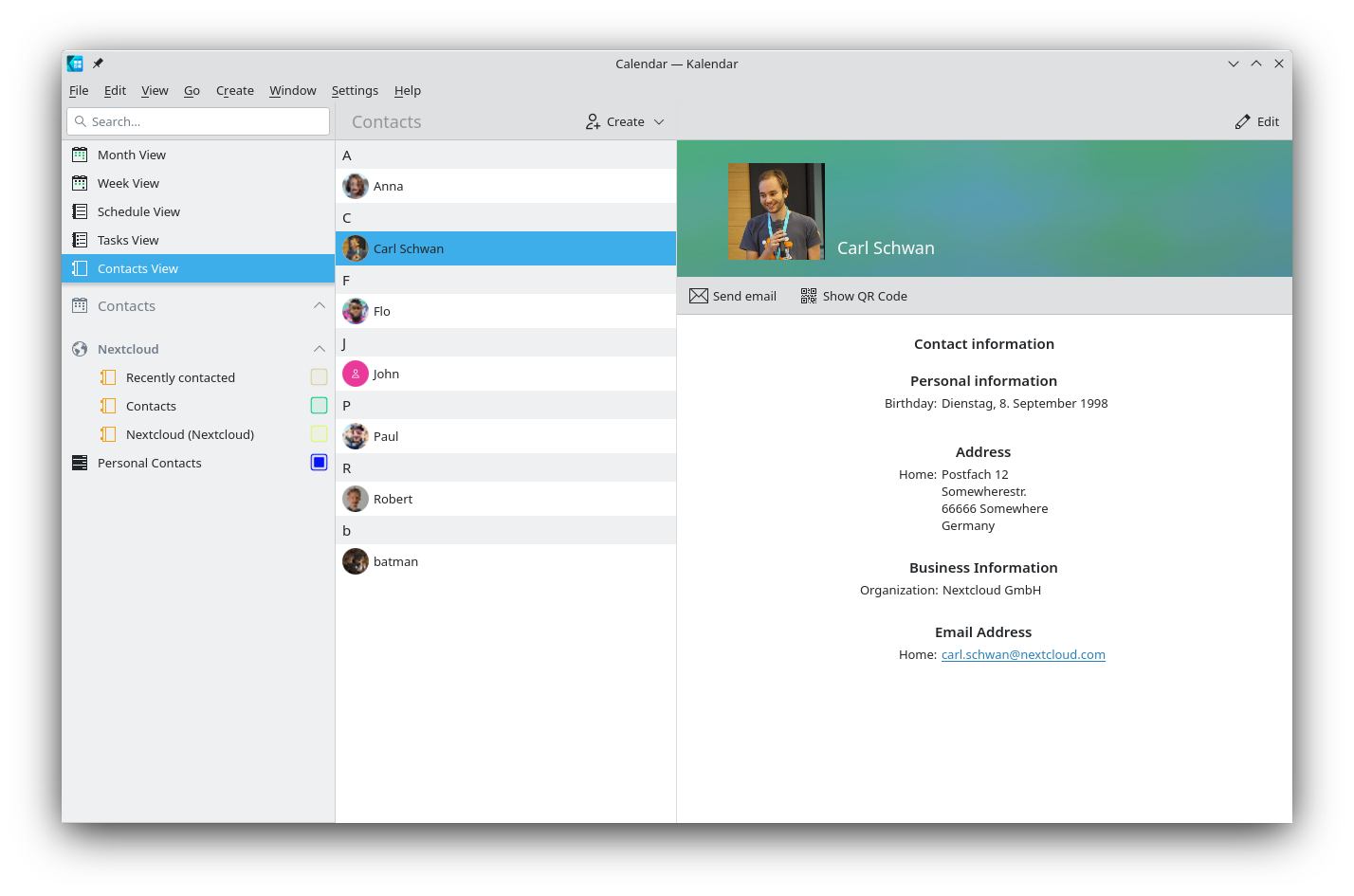
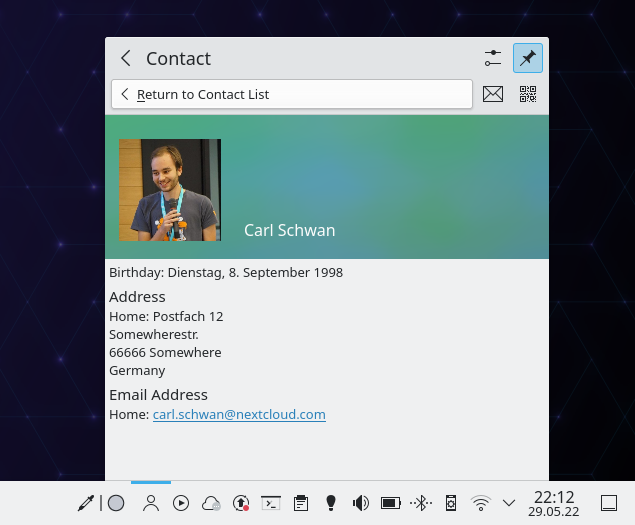
The Contact View
The contact view is the most immediate visual change that users will notice when starting Kalendar.
It’s a new view available in the sidebar and it will display all your contacts synchornized with
Kalendar. It’s also feature a search field, to easily find a contact very helpful when you have
many hundreds contats.
The contact view showing a few contacts
Currently not all the properties that an vcard can contains are displayed, but it is easy to add
more of them later on.
Internally, the contact view uses an
Akonadi::ItemMonitor
so that the changes to the contact are immediately reflected in the view, even if the changes
happened in KAddressBook or were synced in the background from an online service.
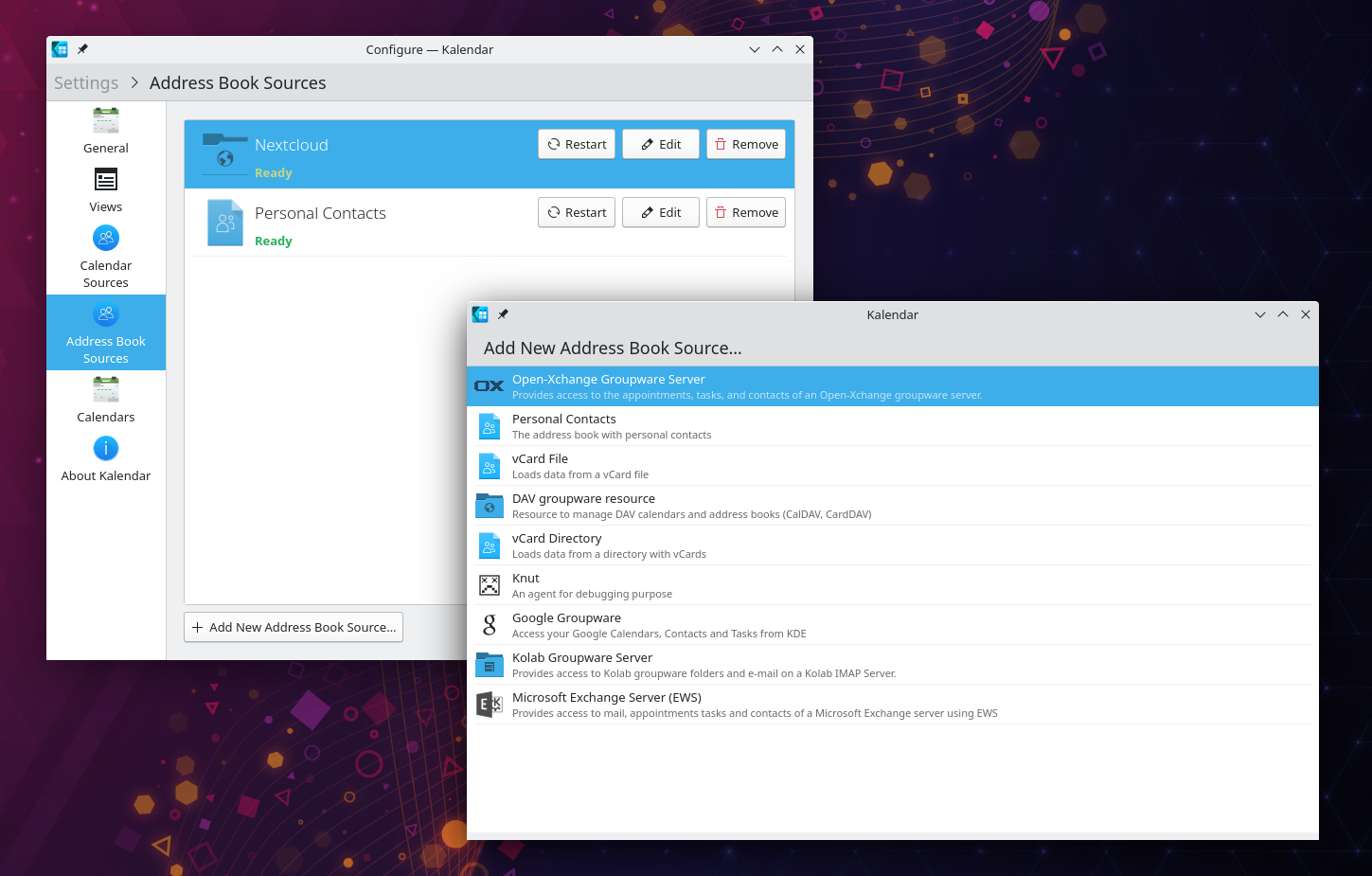
Contact Book Settings
Kalendar has access to the same sources as KAddressBook with for example WebDav (e.g. Nextcloud),
Etesync, Microsoft Exchange Server and local vCard files.
The Google contact provider is still broken due to a massive API change in Google API. It’s a
good reminder that open standards are better for the users and the developers
sanity.
Contact book source settings
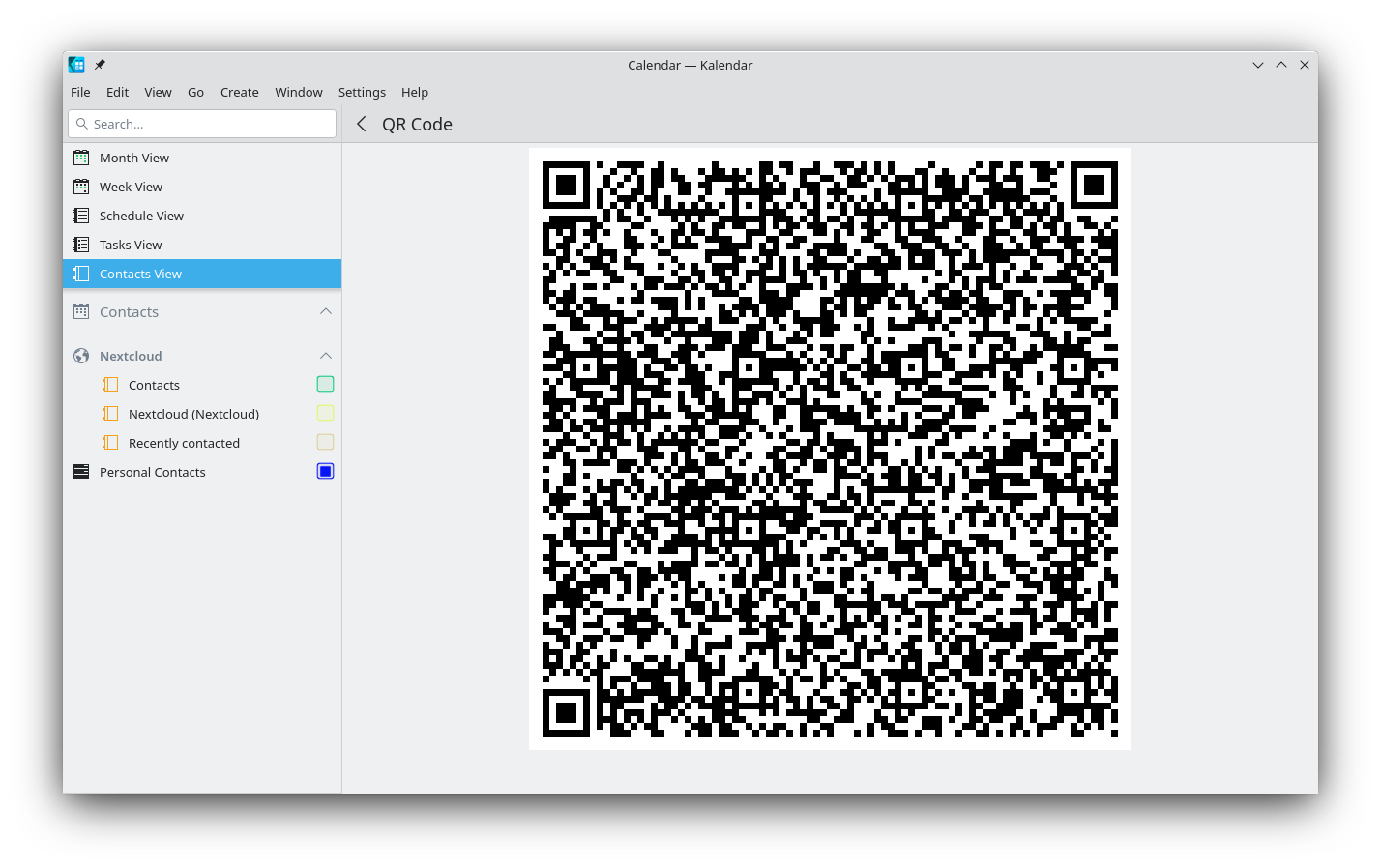
QR Code Sharing
From the contact view, it is also possible generate a QR code. This makes it easy to share one contact
to your phone. If you want to shares and synchronize multiples contacts, it’s better to use a
CardDav-based solution like Nextcloud.
QR code sharing
Plasma Applet
After implementing the contact view, with Claudio we decided to try to keep the codebase for the
calendar and contact support mostly seperated from each others. To to so we created a QML plugin
that contains all the contact utility and that can simply be imported with import org.kde.kalendar.contact 1.0.
This code seperation helped us develop a Plasma applet integrated inside the system try for the
contact book.
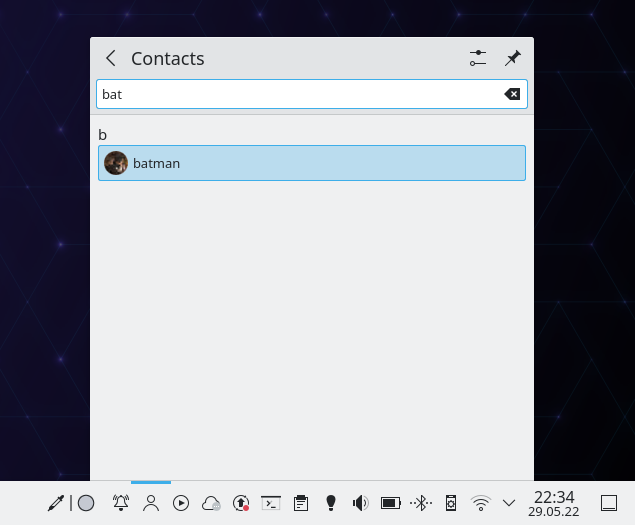
The applet provides an easy way to search for a contact and send them an email or start a call
using KDE Connect.
Searching in the Plasma applet
An contact book Plasma applet
It’s also possible to share with a QR code directly from the Plasma applet.
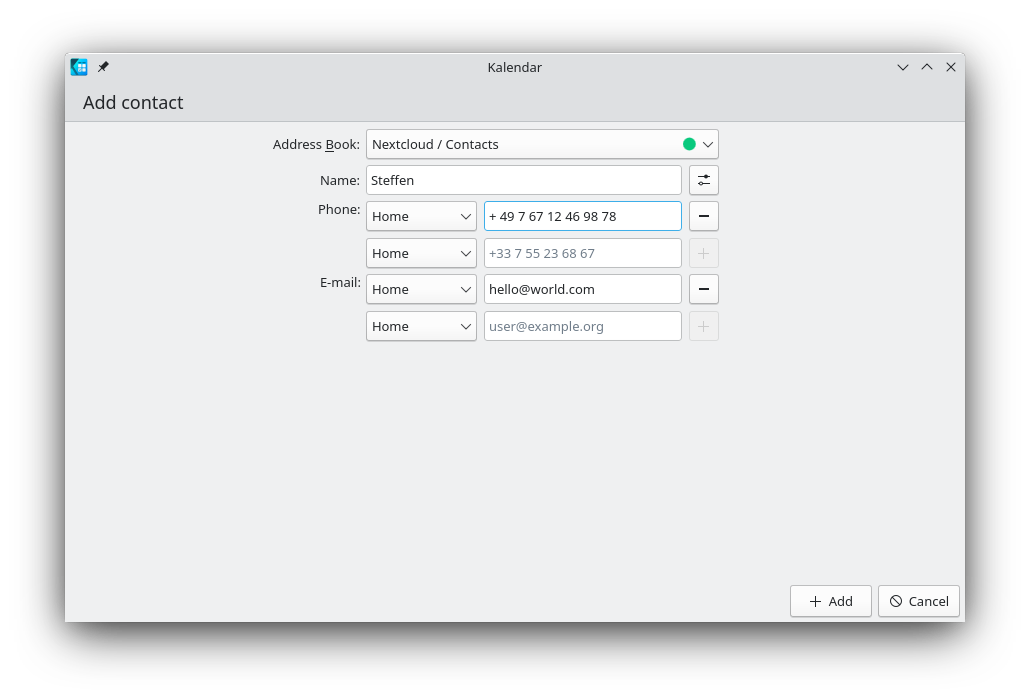
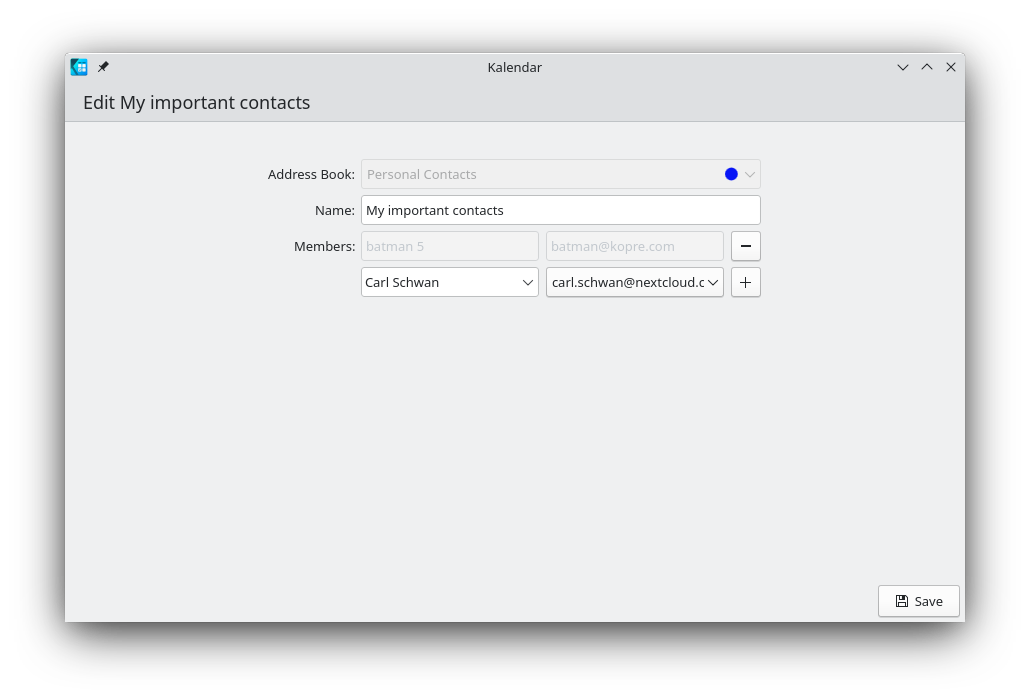
Contact Editor
The contact editor turned out more complicated than planned
and is still missing a lot of features.
The contact editor
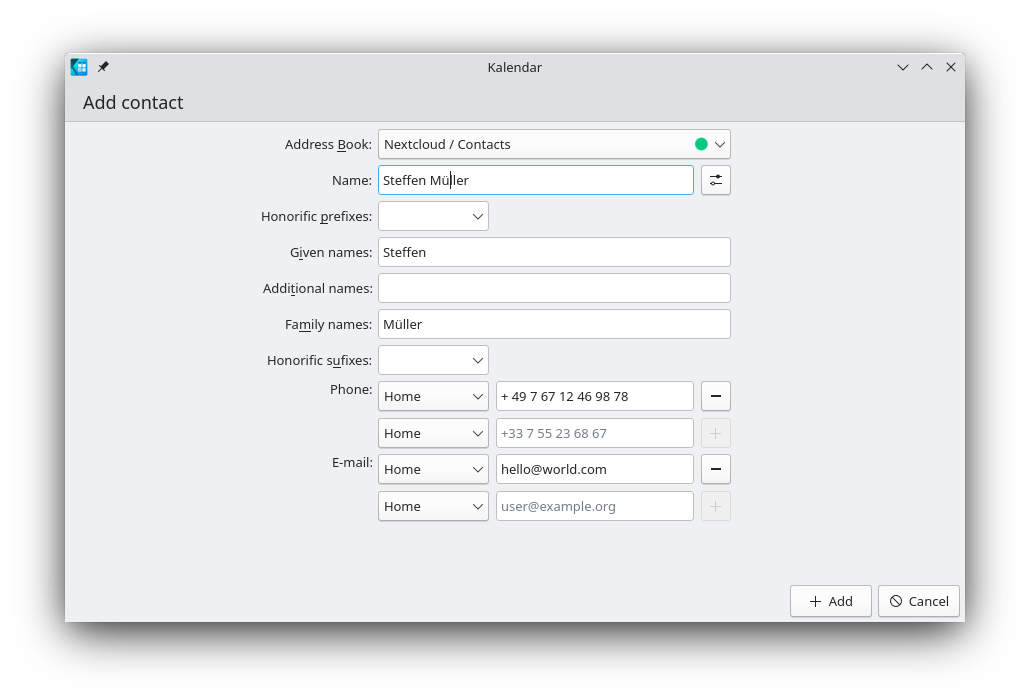
Currently, it only allows to edit the name, the phone numbers and emails of a contact. When editing the
name you also have the choice to set each components of the name separately.
Advanced name options
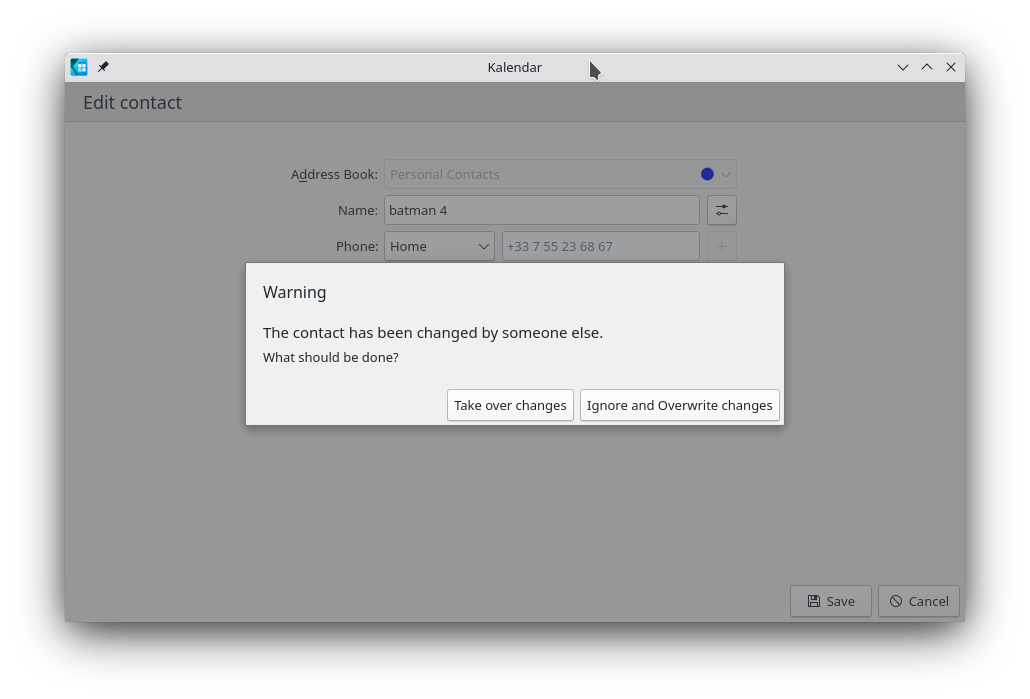
There is also handling for the case there the contact was edited in another Akonadi-powered
editor (like KAddressBook), asking the user what to do when detecting multiple concurrent
editing of the same contact.
Change detection
Contact Group
Kalendar also has support for contact groups. This allows to create a group of contacts with
an associated email address. It’s quite helpful when you want to often send mails to a
group of contact.
Contact Group
You can also edit them, add more contacts and concurrent editing detection is also built-in
the contact group editor.
Contact Group editing
Future
There is still a lot of features missings left to implement. For example, contact deletion,
moving/copying a contact to another contact book but also a lot of contact properties need
to be implemented in the contact book.
These features are relatively straigh forward to implement now that the base is here and if
you want to help with the implementation, join our Matrix room.
We would be happy to guide you.
Hopefully this will all be ready before the 22.08 release.
The Kalendar team is also working on another big component for Kalendar, stay tunned.
Hello, reader! I am Suhaas Joshi, a 20-year-old 3rd-year student at CHRIST University, India. I have been selected to GSoC 2022 as a mentee in KDE. This blog will track my KDE development work during, and after, GSoC coding period.
About the Project:
Flatpak and Snap applications run inside sandboxes, isolated from the rest of the system, and do not have access to many critical resources. As a result, they often cannot do much, and must seek permission to access the resources they require. Flatpaks access these permissions through “portals”, and Snaps do it via “interfaces”. At installation time, these permissions are usually granted by default. Presently, KDE lacks a home-grown mechanism to edit these permissions.
My SoK 2022 Project had two parts: the first was to display these permissions on Discover’s interface, and the second to develop a mechanism (through a KCM module, it was decided) to let users change these permissions. The first segment of the project was accomplished, but the second was leftover.
This GSoC project involves creating the KCM module for Flatpak, and also showing Snap permissions on Discover’s interface in the same way as Flatpaks, as well as creating KCM modules for Snaps.
So far, I have created the repository for Flatpak KCM here.
About Me:
I am a 20-year-old from India, currently pursuing a BTech at Computer Science and Engineering. I have been programming for about 2 years, chiefly in C++, C and Python. I use Fedora KDE as my daily driver, and have been a KDE user for a year. In my free time, I read books on history and politics, and have been getting into Chess lately.
Feel free to contact me if you have any suggestions!
“I can accept failure, everyone fails at something. But I can’t accept not trying.” ~Michael Jordan
Square One
There are so many things that we aspire to achieve in life, and when we do not get them, we are absolutely dejected. A person can take two paths as a consequence of failure; either to quit or, instead of getting disheartened, push harder.
When FOSS Overflow by IIT Bhilai, a nationwide open-source program in India, was about to end in January 2022, I was seeking new avenues in the world of Open Source just like a child mesmerized by some newly discovered activity. I googled “Open Source Programs” and the name of Season of KDE by KDE was amongst the top programs on Geeks for Geeks. I instantly tapped on the link, and the biggest glimmer of hope was that the applications for SOK 2022 were open.
It was not the first time that I was endeavoring to create a proposal and I was confident because the rookie that I was, did not realize that it is not just the content of the proposal but also community engagement and past contributions that the organizations seek in an ideal
candidate.
Discovering GCompris
In the meantime, I also discovered that all the projects under SOK were absolutely challenging for me to begin with at that moment, yet I mustered the strength to at least make a submission. It has been my typical nature to be pushy. It was an “aha” moment when I read the description under the title “GCompris”. This is where the story begins.
The process of first installing the application wised me up to believe that if I somehow learn how to develop these activities, I can definitely think of something interesting that can be incorporated into this product. It was like a whim, just as I mentioned, a childish fantasy, and it has been grooving me on since that day.
The obstacles
However, building the project on my IDE took me over two weeks. It was the first task, and I was already feeling a little jittery. It felt like a setback in the beginning, but I was still determined to just make a submission.
I always reaffirmed to myself that I can learn things here and that GCompris is worth the shot. I could build the project, but it took me so much time to just build the project that I was again doomed to self-doubt. Nonetheless, I continued.
I finally made a submission. suggested a few ideas and their chimerical implementation plans.
Fast forwarding the tidbit to the results day, I got a rejection mail from the community. It wasn’t very surprising to me, but it’s human nature to be crestfallen at such an edict.
My learning
I got detailed feedback from the mentors, which helped me to realise my weaknesses. The biggest mistakes were that I was too hesitant and I didn’t reach out to the community mentors. The next important lesson was that it is important to discuss the plan of action before the real engineering jobs.
Gloom before the glow
I decided to continue to learn to contribute to GCompris irrespective of any program because I was confident that I could learn and make a significant contribution. I started again in March, and proposed my first activity called “The Comparator Activity” and I was not even looking to apply for GSoC because it is one of the most prestigious open source programs, and I used to think it would be some great deal of time before I would be able to make a proposal for GSoC competent enough to make it through the application process. My motivation was to learn, not to participate in GSoC. It spontaneously became a part of my contribution journey with GCompris.
The Comparator Activity
The Community Support
After having done some parts of the activity with the help of my amazing mentors- Johnny, Allon, Harsh, and Deepak-I started enjoying contributing here. It impelled me to visualize my approach to implementation, the art of writing clean code, and the knack for writing modular code. One of the major reasons why I gravitated towards the GCompris community is that they support the contributors by helping us to build the intuition that helps us to become a good developer. I gradually started deriving inspiration from the mentors and emulating their approach in my actions.
Summer of 2022 with KDE and Google
When the proposal submission deadline was coming closer, I realized that my end-of-semester examinations was overlapping, which made things slightly strenuous for me. However, by God’s grace, I prepared a decent proposal in a few weeks’ time and it got accepted.
What follows
I will be completing my Comparator Activity by adding new modes to it and starting the Programming Tux and Guess 24 from scratch.
This journey has taught me so much and is going to be a once-in-a-lifetime experience that I’ll treasure forever. Thus, I am documenting my experience here. It may be still in its infancy, but it will grow and become something I will be proud of. I look forward to engaging with a global audience in the near future.
In the following blogs, I will provide an update on the design and implementation plans for the same. Stay tuned for more!
An excellent piece about the links between collapse and complexity. Obviously focuses more on socio-economics systems. Still some of it applies to other fields.
The current microservices obsession not only invite undue complexity in systems, it also bring unprepared developers into network related traps. This is a nice summary of the common misconceptions around this.
Old video. A bit preachy, especially in the beginning, but then covers well the arguments of why counting stories is likely better than estimating them. In my opinion there’s a catch that is not covered here though: the quality and granularity of the stories matter.
Welcome to the final instalment of the KDE Goals retrospective interviews.
Check out my interview with Aleix where we talk about the “KDE is All About the Apps” Goal and generally about the KDE Goals initiative. See it here:
Thank you Aleix for the interview, and also thank you Jonathan - the initial Goal Champion for the goal!
You can follow Aleix on his twitter, also his website.
If you haven’t seen them yet, the previous two interviews available: Consistency and Wayland.
Next week: the process of submitting the Goals begins! Be sure to check back to learn all about it!
This is my second post during Google Summer of Code 2022.
GSoC community bonding period ends tomorrow.
During this time, I have tried playing around with LibQuotient by writing simple C++ apps to show details from a user's account. (joined rooms, filtering out spaces etc)
On NeoChat, I tried adding UI element to show user's spaces, which certainly didn't go well. The ListView would not show a scroll bar, no matter what. I faced another setback when I realized the code didn't use setContext to control UI (thats the way I'm accustomed to doing it).
This week, Tobias helped me out with these technical things over a call. I'm trying to implement them.
With the actual coding period starting in 2 days, I hope to show up tangible work.



 ervin
ervin
 @flyingcakes:kde.org
@flyingcakes:kde.org GSoC
GSoC