A project that I had planned for quite some time came to fruition last year, now I finally found time to document the result. My livingroom sideboard looked messy and kind of boring while not blending in anymore with the updated style of my living room. I wanted to turn it into a striking centerpiece of the room. The plan was to install a sound-reactive lighting system. I wanted the light effects to be detailed and not disturbed by ambient sound in the living room, i.e. it sound not react to people’s voices, just the music playing.
My living room sideboard is an off-the-shelf product from IKEA that I bought many years ago. It didn’t have doors installed, but I was delighted that I could still buy matching doors with windows in them. To realize the light effects, I’ve installed frosted plexi glass inside the windows.
Getting technical…
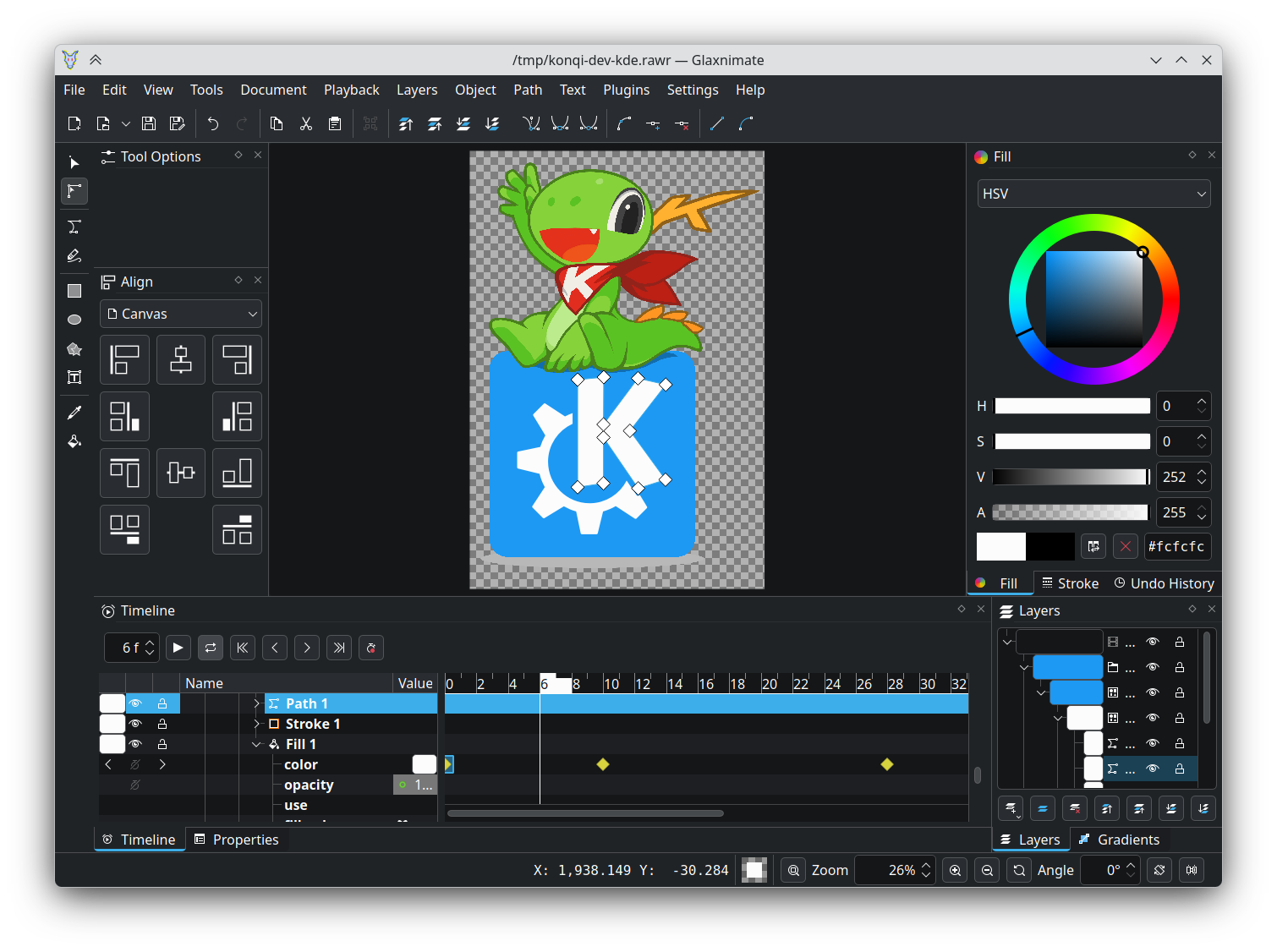
To control the LEDs, I’m using an ESP32-based LED controller with a line-in module and an ADC (analog-digital converter). After some experimenting, I’ve found this board to work well. I’ve connected 6 WS2812B LED strips to 3 pins and installed them with an aluminium profile into the doors. The frosted windows and profiles diffuse the light nicely so you can’t make out individual LEDs really. On the software side, I’m using a sound-reactive port of the WLED project. WLED is Free and Open Source software, of course. Though its user interface can be a little unwieldy, it’s also very powerful and integrates nicely with homeassistant, so it can be controlled automatically.
Inside view
The ESP32, being a rather powerful dual-core microcontroller, can process the incoming audio signal on one core (using fast-fourier transformation) and compute complex LED effects on the other core. Rendering up to 200 frames per second to 2 times 210 LEDs is no problem while power consumption of just the controller stays well under 1W. Pretty impressive! Depending on the LED effects (number of LEDs lit up at a given time and their colors), the whole thing hardly ever reaches 10W of power consumption.
ESP32-based LED controller
Another functional goal of this project was to solve cooling issues of my amplifier once and for all. The amp would run really hot and shut off after playing at higher volume for some time. I installed a bunch of 12cm fans which suck air through the amplifier and blow it out on the backside. Both amp and and fans are connected to smartplugs. I turned to my homeassistant and set up an automation which turns the fans on whenever the amp’s power consumption reaches a certain level. This works really nicely, since the fans never spin at lower volumes (when you could hear them through the music) and keep everything cool and running stable at higher volume when it’s necessary — without human interaction.
Cooling system
Walnut finish
The outer shell of the sideboard is made of walnut wooden panels with an oil and varnish finish, thanks to my friend Joris. The oil gives it a darker look and accentuates the grain, matching the speaker system. The matte varnish finish (Skylt, highly recommended for its durability and natural look) allows me to sleep well even if people put their drinks on it.
Done and dusted
I love it when a plan comes together!
I’m really happy with the result. While I had thought it out for a long time already, it’s always a lot more impressive when you see the final result in action. The WLED firmware allows me to create interesting light effects. I can run the 3 doors as one, but also easily split them up into segments so each door panel renders its own effect. WLED has ca. 200 different LED effects, many of them react to sound. Each effect can be combined with one of 50 color palettes, some of the palettes are sound-reactive in their own right leading to a very dynamic display. One cool feature is that the processed sound data can be broadcast across the network (over UDP) and received by other WLED controllers, so I can have multiple LED displays in the house, each rendering their own effect to the music, creating a more immersive experience.
I'm half-way through the Season of KDE 2026 and wanted to share the journey so far.
I had subscribed to the kde-soc mailing list after I returned from IndiaFOSS'25, where I met KDE contributors who really encouraged me to join the community and told me that one can always learn while building. The first step, always, is to start. Then I got carried away with life until I saw "call to action" in my mailbox in January. It was about SoK'26. I had then recently set up Kubuntu and was in awe about what people can build out of passion and by collaborating with others. I felt mentorship was the way to get started. I explored the projects and found Task-3 under Lokalize as something that I can contribute to while learning new skills- programming in CPP, debugging, and exploring an old repo.
Here's everything i did before the season officialy began.
Before Proposal
I installed ==Lokalize== and reproduced the bug.
Cloned the repo. Used grep to find “Approve and go next” in codebase. Turned out EditorTab::gotoNextFuzzyUntr() is the origin of bug. I thought about "Approve and go prev" and tried that. It was buggy too!
kde-builder failed due to missing libraries. So after lot of fixes, i did ubuntu update to 25.10(has qt6). *Created a test branch and added debug log in forementioned method.
Spent more time understanding the repo, the files,classes and methods which were involved in the bug using debug logs, grep and manual look-over.
Wrote a few comments to document better.
Had an introductory call, was nice to know the contributors.
Week 2
Researched past commit to understand the intent of navigational shortcuts.
Added SPDX license headers( did not know it was being actively developed in GSOC too). Aided Kumud by sending an email to the KDE i18n mailing list regarding the cyclic traversal on entries for keyboard shortcuts in the Translation Units View. Typically, KDE applications don't use that, as followed from the replies and was not needed.
Had a group call for understanding rebase but i still mess up sometimes.
Week 3
While Kumud's implementation addressed gotoNextFuzzyUntr(), analyzed their approach to generalise it to make it work for gotoPrevFuzzyyUntr() and added a parameter to move in either direction for which a new Enum was used instead of magic numbers(they have a name for it T-T). I could see magic numbers used previously in the code and do get it why it isn't preferred.
Week 4
Continued with the week-3's work
Week 5
Worked on fixing other navigational shortcuts in editortab.cpp which implied generalising the function furthermore to take another parameter for entry state. StackOverflow is a saviour(Of course, after my mentor). Throughtout this time, it felt as if things were unravelling themselves to me. New bugs were found and worked upon. Looking back, I mostly improvised upon Kumud's solution but still got to learn a lot on the way.
Week 6
Will work on other bugs identified on the way or scout for new ones! See if I make past this which was primarily the task for SoK.
Glaxnimate 0.6.0 is out! This is the first stable release with Glaxnimate as part of KDE.
The biggest benefit of joining KDE is that now Glaxnimate can use KDE's infrastructure
to build and deploy packages, greatly improving cross-platform support. This allows
us to have releases available on the Microsoft Store and macOS builds
for both Intel and Arm chips.
But there is much more...
KDE-specific features
Glaxnimate now uses the KDE file recovery system making it more reliable.
Settings and styles also go through the KDE systems, which, among other things,
lets you choose from more color themes for the interface.
Translations are also provided by KDE. This makes it easier to keep other languages
up to date as Glaxnimate evolves. In fact, the number of available languages has increased
from 8 to 26!
The script console has also been enhanced with basic autocompletion making scripting easier.
Timeline
The timeline dock now allows effortless scrolling and provides buttons that make moving
to different keyframes, and adding and removing them easier too. This contributes
to making the animation workflow much smoother.
Hiding and showing layers from the timeline now interacts with the undo/redo system.
You can also quickly toggle keyframe easing without having to navigate menus. Just
hold down the Alt key and click on the timeline.
Format Support
SVG import and export has been re-worked, and precompositions
are now properly exported and animations improved. You can even export
an animation as a sequence of SVG frames.
Editing
We have improved the bezier editing tools, and included the ability to Alt-click
on bezier points to cycle between tangent symmetry modes.
The Reverse path action is now implemented and works for all shapes. This is mostly useful
when adding the Trim path modifier.
Bug Fixes
Version 0.5.4 included a significant refactoring of internal logic that introduced
several bugs. These have now have been fixed.
Packager Section
The source code tarballs are available from the KDE servers:
Rocky Linux throws its support behind KDE,
becoming our latest patron.
Rocky Linux is a stable, community-driven, and production-ready Linux
distribution designed to be fully compatible with Red Hat Enterprise Linux.
Rocky Linux powers clouds, supercomputers, servers, and workstations around
the world.
"Sustainable Open Source depends on great open-source communities supporting
each other" said Brian Clemens, Co-founder and Vice President of the Rocky
Enterprise Software Foundation. "We do our best to support our upstreams, and
backing KDE was an easy choice for us given the popularity of the Rocky Linux
KDE spin."
"As a user-first community, KDE creates solutions to address real-world needs"
said Aleix Pol, President of KDE e.V.. "We are excited to welcome Rocky Linux
as a KDE Patron and see KDE's software shine on Rocky Linux,
their enterprise-ready operating system."
Rocky Linux joins KDE e.V.'s other patrons: Blue Systems, Canonical, g10 Code,
Google, Kubuntu Focus, Mbition, Slimbook, SUSE,
Techpaladin, The Qt Company and TUXEDO Computers, who generously support
FOSS and KDE's development through KDE e.V.
Hi Everyone ,I am Hrishikesh Gohain a third year undergraduate student in Computer Science & Engineering from India. For the past few weeks I have been working as a Season of KDE mentee with my mentors Joseph P. De Veaugh-Geiss ,Aakarsh MJ and Karanjot Singh.
This post summarizes the work I have done until Week 5.
KDE Eco is an ongoing initiative by the KDE Community that promotes the use and development of Free , Open Source and Sustainable Software. KEcoLab is a project that allows you to measure energy consumption of your software through ci/cd pipeline using a remote lab.It also generates a detailed report which can further be used to document and review the energy consumed when using one’s software and to obtain Blue Angel eco certification.
The Lab computer on which the software runs for testing was migrated to Fedora 43 recently, which comes with Wayland by default. Writing Standard Usage Scenario scripts, which are needed to emulate user behavior, was previously done with xdotool, but that will not work on Wayland. My work so far has been to port the existing test scripts to a Wayland-compatible tool. For those who want to contribute test scripts to measure their own software , the current scripts can be taken as a reference. My next tasks are to prepare new test scripts to measure energy usage of Plasma Desktop Environmen itself.
In the first week I studied the Lab architecture and how testing of software is done using KEcoLab. The work done by past mentees as part of SOK and GSoC was very helpful for my research which you can read here , here and here. I also set up access to the lab computers through SSH. RDP access had some issues which were solved with the help of my mentors. To replicate the lab environment locally, I set up a Fedora 43 Virtual Machine so that I can test scripts under the same Wayland environment as the lab PC.
I also documented and published a blog about the project and shared with my university community to promote the use of Free and Open Source Software and how it relates to sustainability.
I communicated with my mentors and other community members to decide the new wayland compatible tool. After evaluating different options, we decided to use:
ydotool: for key press, mouse clicks and movements (works using the uinput subsystem)
kdotool : for working with application windows (focusing, identifying window IDs, etc.)
A combination of tools was required to meet all our requirements. To help future contributors, I published my first blog on Planet KDE explaining how to set up and use ydotool and kdotool . I also imported the repositories into KDE Invent for long term compatibility and wrote setup scripts for easier installation and configuration. These tools did not work out of the box and I had to make some workarounds and setup before usage which i documented in the blog.
During these weeks, along with my mentors, I installed and set up the required tools on the Lab PC. I then ported the test scripts of Okular from xdotool to ydotool and kdotool and did testing on my local machine first. Currently, the CI/CD infrastructure through which these scripts run on the Lab PC is temporarily broken due to the migration to Fedora 43. Once these issues are fixed, we will test the new Wayland compatible scripts on the actual lab hardware and compare the results with previous measurements.
I will be working on measuring energy usage of Plasma Desktop Environment itself. It will be more challenging than measuring a normal software application because Plasma is not a single process. It is made up of multiple components such as KWin (compositor), plasmashell, background services, widgets, and system modules. All of these together form the desktop experience.
Unlike normal applications like Okular or Kate, Plasma is always running in the background. So we cannot simply “open” and “close” it like a normal app. Because of this, some changes may be required in the current way of testing using KEcoLab.
To properly design the Standard User Scenario (SUS) scripts for Plasma, I will discuss closely with my mentors and also seek feedback and suggestions from the Plasma community. Defining what should be considered a “standard” usage pattern will require careful discussion and community input.
It has been a very amazing journey till now. I learned how to make right choices of tools/software after properly understanding the requirements instead of directly starting implementation.
I’d like to take a moment to thank my mentors Aakarsh, Karanjot, and Joseph. I am also thankful to the KDE e.V. and the KDE community for supporting us new contributors in the incredible KDE project.
A lot happened in Marknote. We released version 1.4.0 of Marknote, which contains a large number of bug fixes. It also includes a few new features. Siddharth Chopra implemented undo and redo in the sketch editor office/marknote MR #91 and Valentyn Bondarenko made it possible to drag and drop images inside Marknote office/marknote MR #90. Valentyn has also been busy fixing many bugs and improving the stability of Marknote.
Drawy saw a massive wave of improvements and new features this month. Prayag delivered a major UI overhaul that includes a new hamburger menu graphics/drawy MR #295; improved zoom and undo/redo controls graphics/drawy MR #193; and a more uniform appearance across the app. He also improved the saving mechanism to correctly remember the last used file graphics/drawy MR #345.
Laurent Montel was busy expanding the app's core capabilities, implementing a brand-new plugin system to make adding new tools much easier graphics/drawy MR #352; Laurent also added a color scheme menu to switch themes graphics/drawy MR #372, and introduced the ability to customize keyboard shortcuts.
Nikolay Kochulin greatly enhanced how you interact with content, adding support for styluses with erasers and the ability to export your finished canvas to SVG graphics/drawy MR #258; Nikolay also made bringing media into Drawy a breeze by adding support for copying and pasting items, pasting images directly graphics/drawy MR #285, and dragging and dropping content straight onto the canvas graphics/drawy MR #322.
Finally, Abdelhadi Wael polished the visual experience by making the canvas background automatically detect and respect the system's current light or dark mode theme graphics/drawy MR #380.
We removed support for Kolab. If you are using Kolab with KMail, you will need to reconfigure your account with a normal IMAP/DAV account pim/kdepim-runtime MR #154.
We also switched the default database backend to SQLite for new installations pim/akonadi MR #311.
Merkuro Calendar Manage your tasks and events with speed and ease
Zhora Zmeikin fixed a crash when editing or creating a new incidence (25.12.3 - pim/merkuro MR #608).
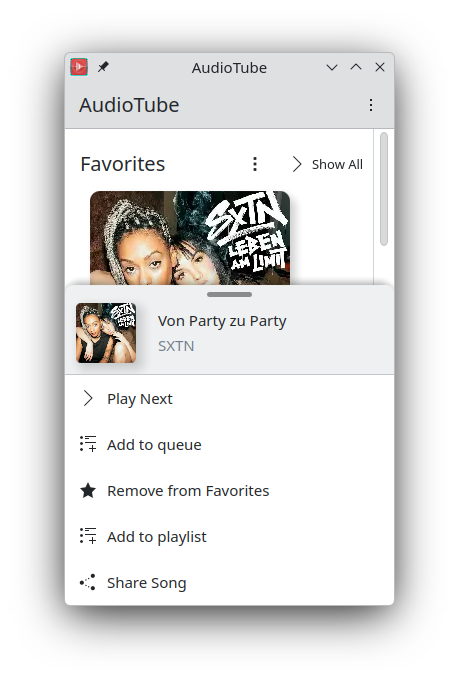
Carl Schwan added a home and explore pages to Audiotube (multimedia/audiotube MR #179) and ported the convergent context menu to the standardized one in Kirigami Addons.
Akseli Lahtinen released Komodo 1.6.0 utilities/komodo MR #72. This release adds Markdown-style inline links, fixes some parsing issues, and removes the monospace font from tasks.
James Graham rewrote the text editor of NeoChat to be a powerful rich text editor (network/neochat MR #2488). James also marked threading as ready, and this feature is no longer hidden behind a feature flag (network/neochat MR #2671); improved the avatar settings (network/neochat MR #2727); and, as always, delivered a lot of polishing all around the place.
Joshua Goins improved the messaging around various encryption key options (network/neochat MR #2687).
This blog only covers the tip of the iceberg! If you’re hungry for more, check out This Week in Plasma, which covers all the work being put into KDE's Plasma desktop environment every Saturday.
For a complete overview of what's going on, visit KDE's Planet, where you can find all KDE news unfiltered directly from our contributors.
Get Involved
The KDE organization has become important in the world, and your time and
contributions have helped us get there. As we grow, we're going to need
your support for KDE to become sustainable.
You can help KDE by becoming an active community member and getting involved.
Each contributor makes a huge difference in KDE — you are not a number or a cog
in a machine! You don’t have to be a programmer either. There are many things
you can do: you can help hunt and confirm bugs, even maybe solve them;
contribute designs for wallpapers, web pages, icons and app interfaces;
translate messages and menu items into your own language; promote KDE in your
local community; and a ton more things.
You can also help us by donating. Any monetary
contribution, however small, will help us cover operational costs, salaries,
travel expenses for contributors and, in general, keep KDE continue bringing Free
Software to the world.
To get your application mentioned here, please ping us in invent or in Matrix.
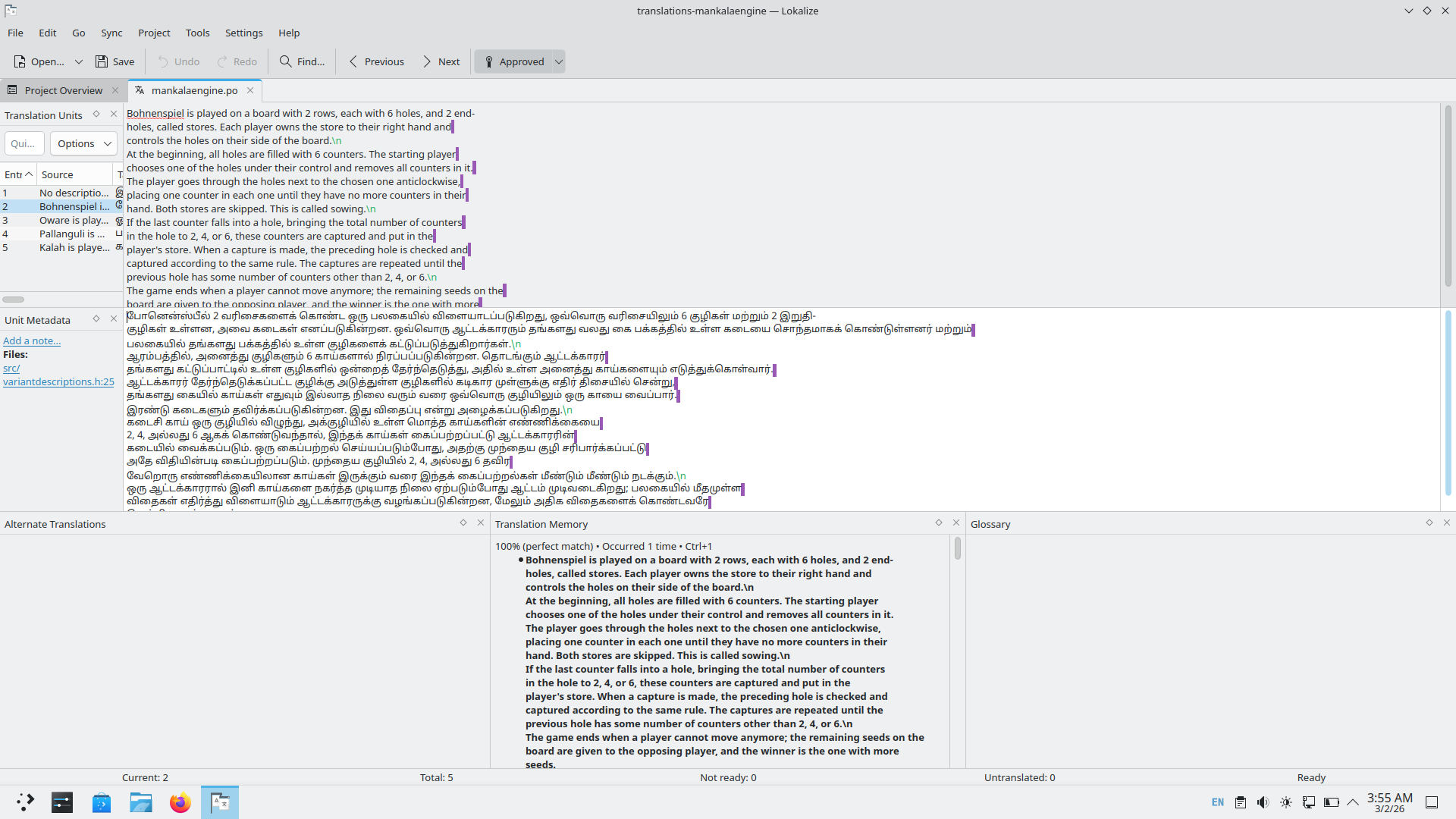
In my 5th week of Season of KDE, I have translated the Mankala Engine into Tamil. Things are a lot easier with KDE’s very own translation software called Lokalize.
Installing Lokalize
Here is a guide to get you started with translation in KDE.
I had installed KDE Lokalize in my Plasma desktop using:
$ sudo apt install localize
My project '''Mankala Engine''' already had translation files under the po folder; I had taken them as a reference for the strings that were to be translated. If the project being translated doesn’t have any prior translation, one can install the language template and start the translation from scratch.
svn co svn://anonsvn.kde.org/home/kde/branches/stable/l10n-kf5/{your-language}
svn co svn://anonsvn.kde.org/home/kde/branches/stable/l10n-kf5/templates
I copied the string from the previous translations of my project and changed the text to my intended language of Tamil. After this, we go to Lokalize and configure the settings.
Enter your name and email.
Find your language and also get their mailing list.
To setup your project, go to the project folder and select your po files and edit them in Lokalize.
Creating translation files
At the beginning of the files, we have some metadata giving the details about the files, their editor, the dates, and the version.
After that, we have the lines for translation, followed by the English strings and then the translated language.
English
#: src/variantdescriptions.h:25
#, kde-format
msgid ""
"Bohnenspiel is played on a board with 2 rows, each with 6 holes, and 2 end-"
"holes, called stores. Each player owns the store to their right hand and "
"controls the holes on their side of the board.\n"
Tamil
msgstr ""
"போனென்ஸ்பீல், 2 வரிசைகளைக் கொண்ட பலகையில் விளையாடப்படுகிறது. ஒவ்வொரு வரிசையிலும் 6 குழிகள் "
"மற்றும் 2 இறுதிக்குழிகள் இருக்கும். ஒவ்வொரு ஆட்டக்காரரும் தமது வலதுபுறமுள்ள இறுதிக்குழியைச் சொந்தமாகக் "
"கொண்டுள்ளனர். பலகையில் தமது பக்கத்திலுள்ள குழிகளை அவர்கள் கட்டுப்படுத்துவார்கள்.\n"
After all the files are created, we should send them to the language moderators or else contact the mailing list of that language and ask for guidance on how these translations can be uploaded.
To get involved and be updated with the team, one can join KDE Translation’s matrix channel:
I was asked a good question: What are these things? What are the
differences? I will try to explain what they are in this post, in bit less technical manner.
I will keep some of the parts bit short here, since I am not 100% knowledgeable
about everything, and I rather people read documentation about it instead of
relying my blogpost. :) But here's the basics of it.
QStyle is the class for making UI elements that follow the style given
for the application. Instead of hardcoding all the styles, we use
QStyle methods for writing things. This is what I was talking about
in my previous post.
Breeze is our current style/theme. It's what defines how things should look like.
Sometimes when we say "Breeze" in QtWidgets context, it means the QStyle of it,
since we do not have other name for it.
QtQuick is the modern way of writing Qt applications.
In QtQuick, we use QML which is a declarative language for writing the
UI components and such. Then we usually have C++ code running the backend
for the application, such as handling data.
Kirigami is a set of shared components and items we can utilize in our QtQuick applications.
Instead of rewriting similar items every time for new apps, we use Kirigami
for many things. We call them Kirigami applications since we rely on it quite a lot.
These two are a bit intermixed. For example, Kirigami provides convenient size units
we have agreed on together, such as Kirigami.Units.smallSpacing.
We then use these units in the qqc2-desktop-style, but in other applications as well:
Both for basic components that QtQuick provides us which are then styled by qqc2-desktop-style,
but also for any custom components one may need to write for an application, if Kirigami
does not provide such.
I wish the two weren't so tightly coupled but there's probably a reason for that, that has
been decided before my time. (Or it just happened as things tend to go.)
As you can see from the diagram, the styles must be kept in sync
by hand. We have to go over each change and somehow sync them.
Not all things have to be kept in sync. This whole thing is rather.. Primitive.
Some parts come from QStyle, some parts are handcrafted, some metrics and spacings can get
out of sync when changed.. But for purposes of "regular person reading this" they need to be
carefully modified by developers to make sure everything looks consistent.
Even bigger problem is that these two (QtWidgets and QtQuick) can behave
very differently, causing a lot of inconsistent look and behavior!
Union is our own "style engine" on top of these two. Instead of having
to keep two completely different stacks in sync, we feed Union
one single source of truth in form of CSS files, and it then chews the
data out to both QtQuick and QtWidgets apps, making sure the both look
as close to each other as possible!
I think it's entirely possible to create other outputs for it too, such as GTK style.
Our ideal goal with Union is to have it feed style information even across toolkits eventually,
but first we just aim for these two! :)
And yes the CSS style files are completely customizable by users!
But note that the CSS is not 1-to-1 something one would use to write for web platforms!
Plasma styles are their own thing, which are made entirely out of SVG files.
I do not know if Union will have an output for that as well, or do we just use the qqc2-desktop-style
directly in our Plasma stack (panels, widgets) so we can deprecate the SVG stack. Nothing has been
decided in this front yet as far as I know.
Yeah that's a lot of stuff. Over +20 years of KDE we have accumulated so many different
ways of doing things, so of course things will get out of sync.
Union will be a big step in resolving the inconsistencies and allowing users easily to
customize their desktop with CSS files, instead of having to edit two or three different styles
for different engines and then having to compile them all and load them over the defaults.
If you are running Plasma git master branch, you may have noticed that Breeze has
gotten various (small) changes to it.
Note that these changes are NOT in 6.6 branch, just in master branch. Current
target is Plasma 6.7 but that may change (6.8) if we still have some issues with it!
And to clarify, I do not know when Union releases to wider public yet. These changes will be
most likely before Union.
This all is happening for two reasons:
Bring Breeze on-par with the current QtQuick styling, which is our current vision for Breeze
Find out any discrepancies and fix them, to make moving to Union theming more seamless
In more technical terms, this means we have made QStyle::PE_PanelItemViewItem (docs) more round. This primitive is used in a lot of places.
For example, see the background of the places panel element here:
It looks much more like the items in our System Settings for example, since they're rounded too.
However this has not been easy: Due to how QStyle works, we have to add margins to the primitive itself,
otherwise it will be touching the edges of the view, making it look bad.
These changes have made us notice bunch of visual oddities since we have +20 years of cruft across our stack,
working on top of Breeze style without taking QStyle into account. People use completely custom
solutions instead of relying on QStyle, though the QStyle API is not easy to work with so I do understand
why it can be annoying.
This is all fine and good if we just decide to use Breeze always and forever. But we're not!
With Union style engine, people are going to do all kinds of cool things. First of course we just
are trying to make 1-to-1 Breeze "copy" with Union, since it's a good target to compare that
everything works.
But when people are going to make their cool new themes with Union, our QtWidgets stack will
not always follow that, due to all the custom things they're doing! So we need to minimize custom
styling within QtWidgets apps and frameworks, and make sure they use QStyle APIs, so that Union
can tell them properly what to do.
A more practical example:
KoolApp directly paints a rectangle with QPainter as a selection background.
It's a regular rectangle, 90 degree angles.
Union style engine is released to the public and everyone starts making their own themes
Someone makes a theme that makes all selection backgrounds a rounded rectangle
They then open KoolApp and notice nothing changes! Since KoolApp draws its on its own.
Everyone is unhappy. :(
However, when KoolApp is updated to use drawPrimitive like this:
// Remove the old background
//painter->setRenderHint(QPainter::Antialiasing);
//painter->setPen(Qt::NoPen);
//painter->setBrush(color);
//painter->drawRect(rect);
// Use style API instead
...
style()->drawPrimitive(QStyle::PE_PanelItemViewItem, &option, &painter, this);
...
// Then for text, add some spacing at start and end so it does not hug the edges of the primitive
const int margin = style()->pixelMetric(QStyle::PM_LayoutHorizontalSpacing);
// NOTE: you can use QStyle::SE_ItemViewItemText to get the subelement of the text
// NOTE: If you use HTML to draw rich text, you will have to do adjustments manually!
// Because nothing can be ever easy. :(
...
Now the background uses what the QStyle gives it,
which in turn is whatever Union has declared for it.
I understand there are cases where someone might want to draw their custom thing,
but if at all possible, please use QStyle API instead! It will make theming
much easier on the long run.
It's better to start catching this all now. It can be more tough to find
the bugs with Union styling later on, because it changes much more than
just one style: It changes the whole styling engine.
When we tinker with Breeze theme to find out these discrepancies, it's easier
to spot if the problem is in Breeze theme itself or the application/framework
drawing the items. With Union, we can also have a bug in Union too, so
it adds one more layer to the bughunt.
So when Breeze looks fine with apps, we can be sure that any changes Union brings,
it can be either a bug in Union or the style Union is using, instead of having to
also hunt down the bug from application/framework.
Read the tasks section, look over what others have shared, share information, etc.
Report everything in that issue!
Any help is appreciated, from spotting small errors to fixing them.
I doubt our QtWidgets and QtQuick styles can be 1-to-1 without Union, so
do not worry too much about that. At the moment goal is just to make sure
the Breeze QStyle is properly utilized. Perfect is the enemy of good and all that.
I hope this does not cause too much annoyance for our git master branch users, but
if you're using master branch, we hope you're helping us test too. :)
Let's make the movement from separate QtWidgets/QtQuick style engines to one unified Union style
engine as seamless as possible. And this will help other QtWidgets styles too, such as Fusion, Kvantum, Klassy,
etc..!
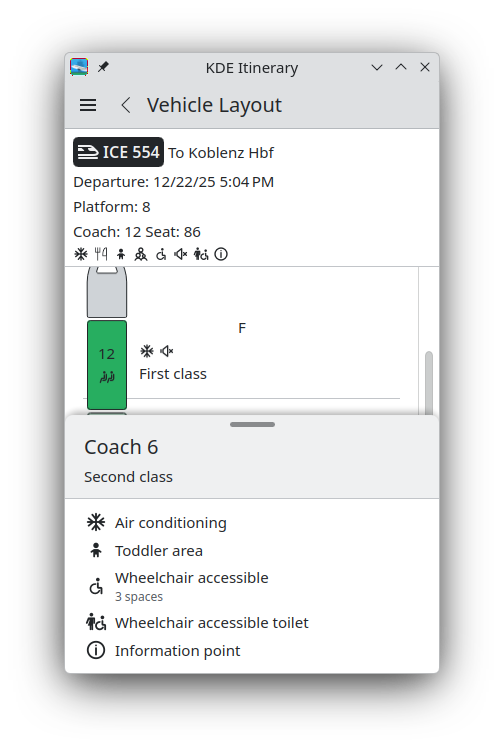
Better defaults when importing a full trip from a previous export.
Better defaults when adding an entrance time to an event that doesn’t have a start time yet, also preventing invisible seconds interfering with input validation.
Allowing to import shortened OSM element URLs as well.
A few changes in the infrastructure for querying public transport information aren’t reflected in the UI yet:
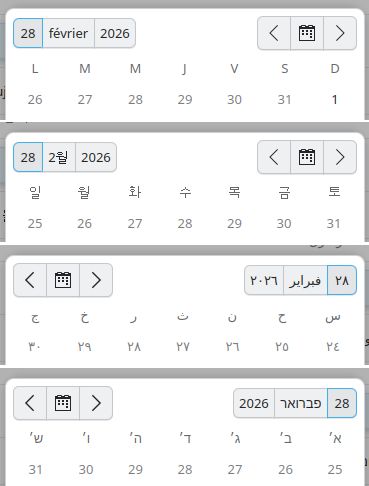
There were also a bunch of fixes in the date/time entry controls related to right-to-left layouts used by e.g. Arabic or Hebrew
(affects all KDE apps using Kirigami Addons).
Kirigami Addons date picker in French, Korean, Arabic and Hebrew.
Transitous
Ride Sharing
We investigated using Amarillo ride sharing data in Transitous,
which are available for example in Baden-Württemberg, Germany and South Tyrol, Italy.
As far as Transitous is concerned those are just GTFS/GTFS-RT feeds with a special route type.
Felix added a dedicated mode class
for ride sharing in MOTIS, so this can also be filtered out, as well as
support for passing through a booking deep-link.
So once the next MOTIS release is deployed for Transitous we can add Amarillo feeds as well.
A ride sharing connection in the MOTIS UI.
Meta Stations
For cities with multiple equally important main railway stations it can be useful to be able to specify
just the city as destination and let the router pick an appropriate station. When choosing your precise destination
(which usually isn’t the railway station) this already works correctly, but when only looking at the
long-distance part of a trip this would fail for places like Paris or London.
One approach to address this are so-called “meta stations”, a set of stations that the router considers
as equivalent destinations, even when being far apart.
MOTIS v2.8 added support for a custom GTFS extension to specify such meta stations, and we now have
infrastructure for Transitous to generate a suitable GTFS feed based on a manually maintained
map of corresponding Wikidata items, including translations into a hundred or so languages.
While this works we also identified issues in the current production deployment where the geocoder
would rank meta stations so low that they are practically unfindable. Fixes for this have been implemented
in MOTIS.
SIRI-FM Elevator Data
Holger and Felix implemented
the missing bits for finally consuming the DB OpenStation SIRI-FM feed,
which provides realtime status information of elevators, something particularly important
for wheelchair routing.
The main challenge here is that the SIRI-FM feed only references elevators by an identifiers which is
described in the DB OpenStation NeTEx dataset, but without being geo-referenced there. So this
data had to be mapped to OSM elements first, which is what the router ultimately
uses as input.
This also provides some of the foundation to eventually also consume elevator status data from the
Swiss SIRI-SX feed.
You can help!
Getting people to work together in the same room for a few days is immensely valuable and productive,
there’s a great deal of knowledge transfer happening, and it provides a big motivational boost.
However, physical meetings incur costs, and that’s where your donations help! KDE e.V.
and local OSM chapters like the FOSSGIS e.V.
support these activities.

 sebas
sebas





 @navya1817:matrix.org
@navya1817:matrix.org