Sunday, 31 May 2026

 tomaz
tomazBack in March at FOSSASIA in Bangkok, I got invited to visit the OpenKylin team in Shanghai. I mentioned it briefly at the end of that report, and here we are — the follow-up post.
Back in March at FOSSASIA in Bangkok, I got invited to visit the OpenKylin team in Shanghai. I mentioned it briefly at the end of that report, and here we are — the follow-up post.
So... progress continues on Oxygen 
Over the last few weeks me and Pravin Kumar have been filling in some of the gaps in the icon set. There are still quite a few missing icons around the place, but slowly Oxygen is becoming a bit more complete again.
Its fun revisiting this old project after all these years. Sometimes I find myself looking at old icons wondering what younger me was thinking. Sometimes the answer is "not much"or, the answer is "way too much"..
Either way, Oxygen continues to grow.
Talking about fun...
I've also been spending some time investigating QML styling and themeing. And in this case not because i have immediate plans do this, but mostly because i am curious about what is possible and where the limitations actually are.
One thing I learned over the years is that there is often a large gap between what a toolkit "officially" allows and what a sufficiently stubborn designer can get away with 
Some of the ideas are probably completely unreasonable. Some not so much
Which usually means they are worth exploring.
I've been experimenting with possible directions for O² and thinking about how a future visual language could work. And this that im doing now is more of an exploration on the range rgther than what it actualy look slike
Nothing concrete yet.
Mostly experiments.
Questions.
Terrible ideas.
Possibly a few good ones hidden among them.
If things continue to move forward we (via KDAB) probably make a video showing some of these investigations, experiments and concepts. Sometimes its easier to explain visual ideas by showing them instead of writing walls of text about them.
So stay tuned
And as always... if you are using Oxygen, thank you.
Its nice seeing that this old project still has a few new stories to tell.
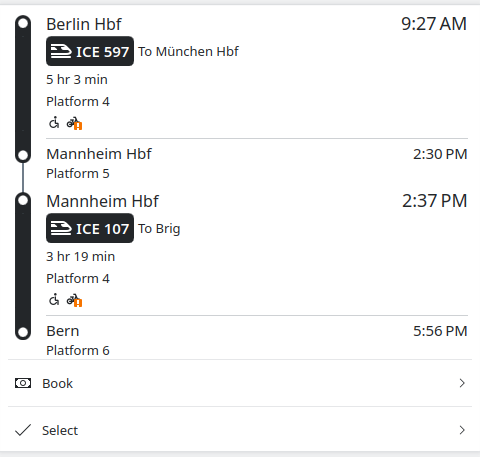
Since the previous report two month ago, Itinerary got support for booking URLs, a newer foundation for its Android packages, and more detailed shared vehicle information.
Some public transport services provide booking deep links together with their journey search results. That is, you can directly book the journey you have just searched in Itinerary or KTrip on the provider website, without having to search for the same journey again there. Both apps provide that option when available now.
The handling of shared vehicles in KPublicTransport recevied a rework to properly support the much more detailed modelling of vehicle types in newer GBFS versions. Since the early versions of GBFS this has evolved from a simple enum to a complex type describing all kinds of properties of the available vehicles.
As practically all systems supporting rental vehicles for first/last mile routing (OpenTripPlanner, MOTIS, etc) are based on the GBFS datamodel, being limited to an oversimplified set of fixed types was increasingly getting into the way and prevented using newer features of those backends.
There has been a long overdue update of the Qt version used for KDE’s Android apps. As noted previously this unfortunately means losing support for Android versions 8 and below. ARM32 builds have been discontinued in the process as well, assuming that devices capable of running Android 9 or higher would also be able to run ARM64 code.
There have also been various other fixes related to the Android platform integration:
All of this also benefits all of KDE’s Android apps.
Air France/KLM published their current flight schedule as open data, in IATA SSIM format. A newly built tool allows to convert that into a GTFS feed that Transitous can then consume, using Wikidata to provide translated airport and airline information.
Flight data isn’t new in Transitous, but this dataset is particularly interesting given its size. It’s not limited to Air France/KLM themselves, but also includes all (?) flights from their partner airlines. In total it’s nearly 400.000 flight patterns to almost 1.000 different airports. That essentially connects all currently disconnected public transport “islands” we have in Transitous.
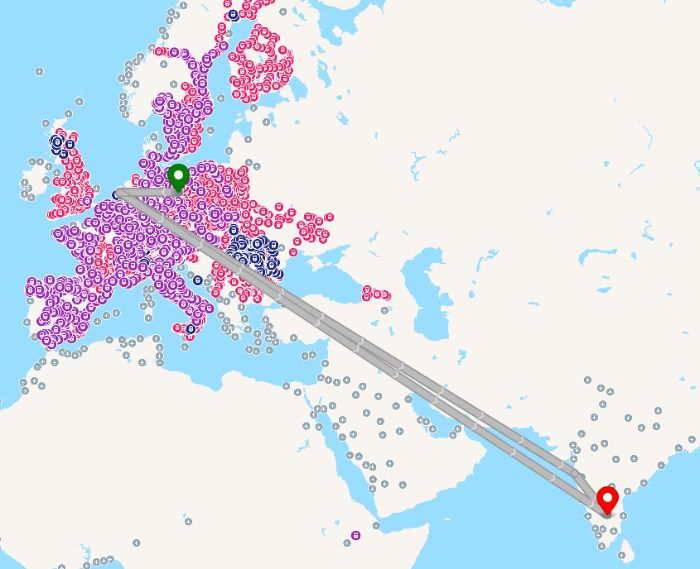
The good news is that it’s holding up to that without a loss in performance, and door-to-door routing from e.g. Berlin to Tokyo actually works.
However, there’s a couple of reasons this isn’t rolled out yet and only available on the test instance:
For more details see also the discussion in PR 2090.
Registration for this year’s Open Transport Community Conference in October in Bern, Switzerland, opened a few days ago. That’s as close as it gets to an Itinerary conference. If you are interested in attending better sign up quickly, many tickets were already gone after the first day.
This has been made possible thanks to your travel document donations!
All of this also directly benefits KTrip.
Feedback and travel document samples are very much welcome, as are all other forms of contributions. Feel free to join us in the KDE Itinerary Matrix channel.
Welcome to a new issue of This Week in Plasma!
This week the team continued getting Plasma 6.7 in great shape for release. So there was lots of focus on bug-fixing and UI polishing.
We’ve released the second beta of Plasma 6.7, jam-packed with the latest fixes. If you can, please install it and test everything! There are many options for doing so.
Made it impossible to accidentally drag a window so far off a screen edge that it couldn’t be moved back. (Vlad Zahorodnii, KDE Bugzilla #495635)
Uninstalling an application now removes it from the history section of all the various launcher widgets. (Christoph Wolk, KDE Bugzilla #437303)
Made auto-hide panels compatible with the “Switch desktop on edge > Always enabled” setting. (Francesco Panarese, KDE Bugzilla #370964)
The Application Launcher’s “All Applications” view now groups apps case-insensitively, so apps whose first letter is lowercase no longer get pushed into their own group. (Christoph Wolk, KDE Bugzilla #501788)
Clarified how the option to create a virtual screen works in the screen chooser dialog. (David Redondo, KDE Bugzilla #517296)
The lock screen now fully respects the timeout value set by PAM on the underlying system, instead of adding its own mandatory delay on top of it. This means on systems with the delay set to 0, you can re-type your password immediately after getting it wrong. (Tobias Fella, plasma-desktop MR #3702 and plasma-workspace MR #322)
The lock screen now notifies you when the “Slow Keys” accessibility feature is turned on, just in case you’re failing to type your password and don’t know why. (Martin Riethmayer, plasma-desktop #3726 and plasma-workspace MR #6626)
Discover’s dialog about a Flatpak app being replaced by another one now reassures you that your data will be automatically transferred, and also warns you that favorites/shortcuts/etc. to the old app will have to be re-made manually. (Nate Graham, discover MR #1342 and discover MR #1343)
Reduced the amount of visual flickering when Discover checks for updates. (Aleix Pol Gonzalez, KDE Bugzilla #513220)
Fixed a case where KWin could crash when a monitor was rapidly power-cycled or some of its settings were rapidly changed. (Vlad Zahorodnii, KDE Bugzilla #520145)
Fixed a case where the kactivitymanagerd service could crash in the background. (Marco Martin, KDE Bugzilla #520595)
Fixed a clipboard-related issue that could make XWayland-using apps lag or freeze right after locking the screen. (Vlad Zahorodnii, KDE Bugzilla #520674)
Fixed an issue that could make the large text of the digital clock displayed on the lock and login screens look kind of jagged with certain specific fonts. (Filip Fila, KDE Bugzilla #516314)
Worked around an oddly-specific issue in Qt that could make widgets break when enabled in the System Tray after having previously disabled them and then restarted the computer. (Tobias Fella, KDE Bugzilla #520144)
Worked around an issue with the hardware or firmware on specific laptops that could trigger an infinite stream of keyboard brightness OSDs after closing the lid. (Vitaly Repin, powerdevil MR #632)
Fixed an issue that could make a renamed file on the desktop visually disappear (it still existed, and could be accessed through Dolphin) while multiple Activities were in use, or move to another location when there was only one Activity. (Akseli Lahtinen, KDE Bugzilla #520633 and KDE Bugzilla #511920)
Fixed an issue that made it impossible to use a hardware key to authenticate to an 802.1x-protected network. (Katharina Bogad, KDE Bugzilla #520449)
Fixed an issue that made the Networks widget show the wrong icon for an OVS bridge network. (Ivan Perevalov, KDE Bugzilla #517384)
Fixed an issue that could make Plasma’s built-in remote desktop server lag or freeze when copying certain specific things in certain specific apps. (Paul Hoskinson, KDE Bugzilla #520175)
Fixed an issue that made it impossible to focus the Network Widget’s search field using Ctrl+F. (Akseli Lahtinen, KDE Bugzilla #515280)
Fixed an issue that made the buttons on the fingerprint enrollment dialog get misplaced. (Harald Sitter, KDE Bugzilla #515824)
Fixed an issue with the Breeze theming of GTK apps that made sidebar separator lines turn bright white with dark color schemes. (Levi Leal, KDE Bugzilla #484383)
Fixed two issues that could make KWin crash or fail to evaluate mathematical calculations from the Overview effect. (Alexander Lohnau, KDE Bugzilla #519923 and KDE Bugzilla #483147)
Fixed an issue that made it impossible to open the panel context menu while already in edit mode. (Tobias Fella, libplasma MR #1468)
KDE has become important in the world, and your time and contributions have helped us get there. As we grow, we need your support to keep KDE sustainable.
Would you like to help put together this weekly report? Introduce yourself in the Matrix room and join the team!
Beyond that, you can help KDE by directly getting involved in any other projects. Donating time is actually more impactful than donating money. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine! You don’t have to be a programmer, either; many other opportunities exist.
You can also help out by making a donation! This helps cover operational costs, salaries, travel expenses for contributors, and in general just keeps KDE bringing Free Software to the world.
Push a commit to the relevant merge request on invent.kde.org.
After a few months of development, Marknote 1.6.0 is out!
This release is packed with new features. First of all, sub-folders are finally supported. This allows you to better organize your notes. This feature is still very new and at the moment, we don’t support creating these sub-folders in Marknote and you will need to create them in Dolphin or your preferred file manager. But we are planning to improve this further in future releases. Each notebook now also displays how many notes are stored inside.
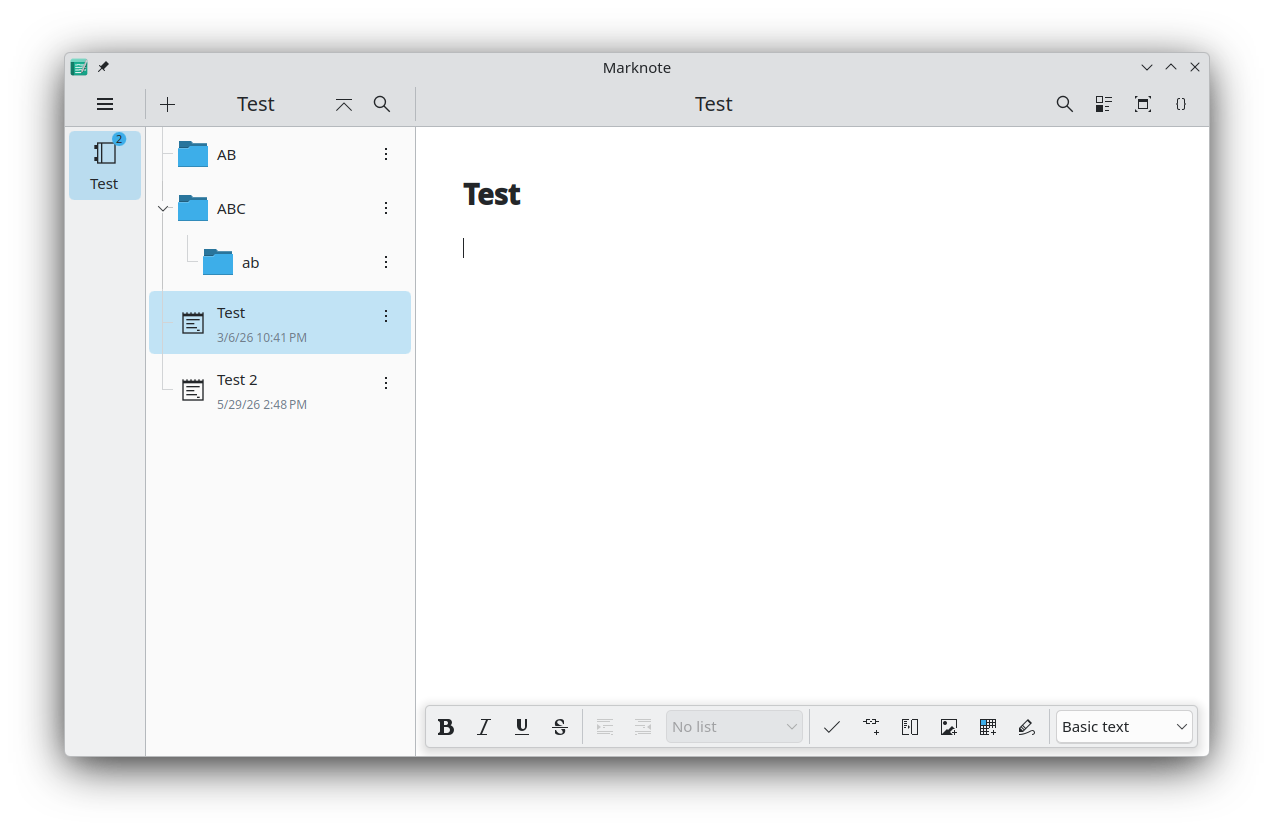
Another big new change is that the command bar exposed by Marknote, now allows you to search for notes across all your notebooks.
If you feel fancy, we also added an optional background blur effect for the editor similar to what is also available in other KDE apps like NeoChat.
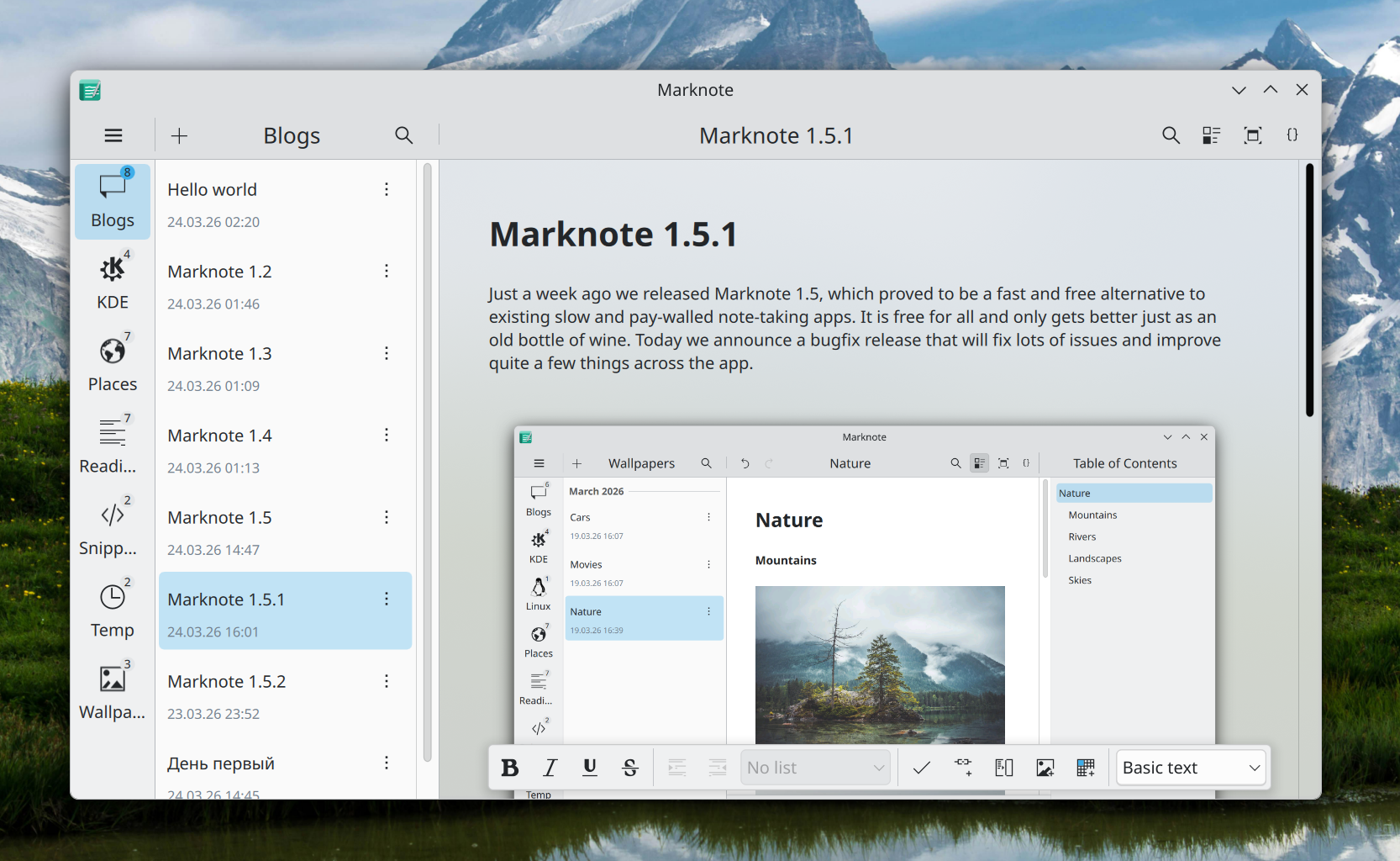
Finally, we made it easier to add emojis to your notes by adding emoji completions to the text editor.
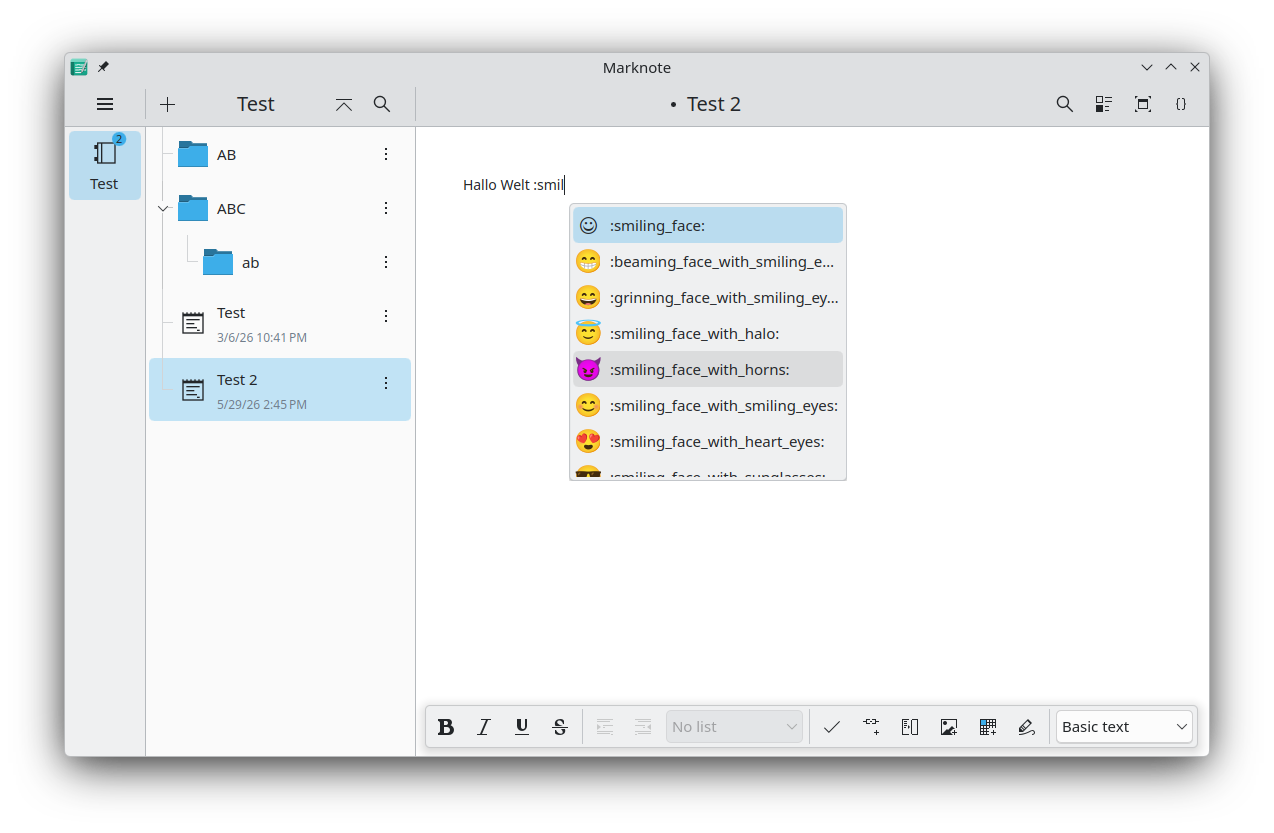
This release also fixes various minor bugs; contains small refactoring and improves the state of the translations.
You can find the package on download.kde.org (kirigami addons) and it has been signed with my GPG key.
The community bonding period is over, and coding started, so this feels like the right moment for a first blog post. I'm contributing to KeepSecret this summer as part of GSoC 2026, working on single-wallet UX and page navigation architecture.
What I did during community bonding:
->Close/dismiss button for entry detail panel
Before the Community Bonding Period:
Resolving three issues:
Week 1 plan:
This week, I'm working on Import/export: study existing wallet data structures in KeepSecret. Define file format and design the export flow.
Port KeepSecret's actions to the new org.kde.kirigami.actioncollection API from kirigami-app-components. This wasn't in the original proposal but it's a good addition, suggested by my mentor, notmart (Marco Martin) — it means users will be able to configure keyboard shortcuts for actions like "New Wallet" and "New Entry" through a standard KDE dialog.
More updates next week. The code is at invent.kde.org/utilities/keepsecret
GSoC 2026 KDE KeepSecret Kirigami Qt / QML
Today we're releasing Krita 5.3.2 and 6.0.2. This release fixes a number of issues with the text tool, and improves the Selection Action Panel significantly. Furthermore, Android now handles resource copying in the background, preventing a common crash on startup. In addition to that, many more bugfixes were made, including some by new contributors!
Check out the release notes for a full overview of all the new features in Krita 5.3 and 6.0.
⚠️ Warning
A particularly annoying set of bugs with the layer docker crept in. We're releasing a fix as soon as possible. We recommend waiting for the fix.
⚠️ Warning
One again, we consider Krita 5.3.2 suitable for productive work; 6.0.2 is, because of the many changes from Qt5 to Qt6 more experimental.
If you're using the portable zip files, just open the zip file in Explorer and drag the folder somewhere convenient, then double-click on the Krita icon in the folder. This will not impact an installed version of Krita, though it will share your settings and custom resources with your regular installed version of Krita. For reporting crashes, also get the debug symbols folder.
ⓘ Note
We are no longer making 32-bit Windows builds.
64 bits Windows Installer: krita-x64-5.3.2-setup.exe
Portable 64 bits Windows: krita-x64-5.3.2.zip
Note: starting with recent releases, the minimum supported distro versions may change.
⚠️ Warning
Starting with recent AppImage runtime updates, some AppImageLauncher versions may be incompatible. See AppImage runtime docs for troubleshooting.
Note: minimum supported MacOS may change between releases.
Krita on Android is still beta; tablets only.
For source archives, please download one of the 6.0.2 archives and build with Qt5.
If you're using the portable zip files, just open the zip file in Explorer and drag the folder somewhere convenient, then double-click on the Krita icon in the folder. This will not impact an installed version of Krita, though it will share your settings and custom resources with your regular installed version of Krita. For reporting crashes, also get the debug symbols folder.
ⓘ Note
We are no longer making 32-bit Windows builds.
64 bits Windows Installer: krita-x64-6.0.2-setup.exe
Portable 64 bits Windows: krita-x64-6.0.2.zip
Note: starting with recent releases, the minimum supported distro versions may change.
⚠️ Warning
Starting with recent AppImage runtime updates, some AppImageLauncher versions may be incompatible. See AppImage runtime docs for troubleshooting.
Note: minimum supported MacOS may change between releases.
Krita 6.0.2 is not yet functional on Android, so we are not making APK's available for sideloading.
For all downloads, visit https://download.kde.org/stable/krita/6.0.2/ and click on "Details" to get the hashes.
The Linux AppImage and the source tarballs are signed. You can retrieve the public key here. The signatures are here (filenames ending in .sig).
Krita 5.3.2/6.0.2 is here. Read on for a look at development news and the Krita-Artists forum's featured artwork from last month.
Krita 5.3.2/6.0.2 was released, containing various bugfixes and improvements from the nearly two months since 5.3.1/6.0.1.
In the Text Properties docker there are now buttons to toggle Bold and Italic next to the Font Style chooser, toggling italics with Ctrl+I works properly the first time, and an issue where some fonts wouldn't allow choosing Regular style was fixed (bug; CCbug; change).
A freeze on opening a high PPI image with a vector layer was fixed, as well as the image progress bar getting stuck (bug; change 1, change 2).
In Krita Next, the Selection Tools now have a tool option to Move Selected Content by dragging the inside of a selection. (wishbug; change by Ricky Ringler)
Wolthera has made some improvements to the Wide Gamut Color Selector. L*a*b* and YCbCr are converted to LCh (lightness, chroma, hue) instead of directly using their channels, meaning they are now able to map properly to the HSV-based selector layouts (change). Additionally, the static hue edge option is now implemented for when hue is shown in a bar instead of a ring (change).
The winner of the "Microadventure" challenge is…

For May's theme, last month's winner has chosen "Animals and Patterns"
This month's featured forum artwork, as voted in the Best of Krita-Artists - March/April 2026:





Participate in next month's nominations and voting to voice your opinion on the Best of Krita-Artists - April/May 2026.
Krita is free to use and modify, but it can only exist with the contributions of the community. A small sponsored team alongside volunteer programmers, artists, writers, testers, translators, and more from across the world keep development going.
If this software has value to you, consider donating to the Krita Development Fund. Or Get Involved and put your skills to use making Krita and its community better!

These pre-release versions of Krita are built every day.
Note that there are currently no Qt6 builds for Android.
Get the latest bugfixes in Stable Krita Plus (5.3.3/6.0.3 prealpha): Linux Qt6 Qt5 — Windows Qt6 Qt5 — macOS Qt6 Qt5 — Android arm64 Qt5 – Android arm32 Qt5 – Android x86_64 Qt5
Or test out the latest Experimental features in Krita Next (5.4.0/6.1.0-prealpha). Feedback and bug reports are appreciated!: Linux Qt6 Qt5 — Windows Qt6 Qt5 — macOS Qt6 Qt5 — Android arm64 Qt5 – Android arm32 Qt5 – Android x86_64 Qt5
I have been tinkering with Helix editor lately since I quite like it.
It's a fun little editor. Can recommend for those who like modal editing. I do not know if it'll ever replace Kate editor for me, but I'm challenging myself to try new tools, just for the fun of it.
With Helix, I've used this git tool called gitu that is rather quick and easy to work with. Though I still use lazygit for more complex tasks.
Main pain point for me has been how to use some of these tools like gitu within Helix. Lazygit could be done with some magic, but I was never really satisfied with it.
I also tried Zellij for terminal multiplexing and running commands between two splits and so on. It was a bit cumbersome to get it to work as I wanted, since Zellij has tons of features I'll never need. This also caused my fingers to get entangled since I had to remember all sorts of shortcuts. Just not for me.
In Konsole terminal, there is a shortcut for splitting views easily and automatically to a fitting size. I use it a bunch. But because I'm lazy, I would have to press the shortcut, go to the other splitview, type the command for other tool, do things and then close commands. I wanted something a bit more automated.
I found that Konsole can be set to allow scripting over dbus commands: Scripting Konsole.
So I made myself a little shell script that I placed in my path: konsole-split.sh!
Here's what it does:
#!/usr/bin/env bash
# In konsole settings, make sure
# - run all konsole windows in single process is disabled
# - enable the security sensitive parts is enabled
if [ $# -eq 0 ]; then
echo "Command is missing!"
exit
fi
# Split the view automagically. We can use MainWindow_1 since we have only one process
qdbus6 "$KONSOLE_DBUS_SERVICE" /konsole/MainWindow_1 org.kde.KMainWindow.activateAction split-view-auto >/dev/tty
# Get the session of the current terminal window
CURRENTSESSION=$(qdbus6 "$KONSOLE_DBUS_SERVICE" "$KONSOLE_DBUS_WINDOW" org.kde.konsole.Window.currentSession) >/dev/tty
# Run the given arguments as a command in that session
qdbus6 "$KONSOLE_DBUS_SERVICE" /Sessions/"${CURRENTSESSION}" org.kde.konsole.Session.runCommand "$@" >/dev/tty
It's really simple, but now I can use this in my helix config like this:
[keys.normal."+"]
b = ":sh git log -L %{cursor_line},+1:%{buffer_name}" #This is git log for a line, also useful, kinda like git blame
s = ":sh konsole-split.sh 'exec scooter'" # Scooter is a search and replace in multiple files tool, very handy
g = ":sh konsole-split.sh 'exec gitu'"
In practice, what happens is:
In helix, i press +
Then I select the command, in this case gitu, so g
Konsole splits itself automatically to a comfortable size
It then gets the session of that new split
And runs the gitu command with exec
This works really well for my needs, and I was surprised to see how simple it was to create something like this. I think the error handling when command does not work could be better, but oh well, works for me for now.
Let me know if you do anything similar or have any improvement ideas! :)


 @vkrause:kde.org
@vkrause:kde.org


 GSoC
GSoC