Akademy 2026 will be a hybrid event held simultaneously in Graz, Austria,
and Online.
Hundreds of participants from the global KDE community, the wider free and
open source software community, local organisations and software companies
will gather at this year's Akademy 2026 conference. The event will take
place in Graz and Online from Saturday, 19 September to Thursday, 24 September.
KDE developers, artists, designers, translators, users, writers, sponsors and
supporters worldwide will meet face-to-face to discuss key technology issues,
explore new ideas and strengthen KDE's innovative and dynamic culture.
Register now and join us for engaging talks,
workshops, BoFs and coding sessions. Collaborate with your fellow KDE
contributors to fix bugs, pioneer new features and immerse yourself in the
world of open source.
For more information about the conference, visit the
Akademy 2026 website.
Qt 6.11 brings a set of meaningful improvements to the Qt GRPC library, focusing on stability, safety, performance, and new capabilities that make building gRPC™ based applications in Qt more powerful and productive.
Krita 5.3.1.1 is an Android-only fix for 5.3.1. It is exactly the same as Krita 5.3.1, but with two fixes:
fixed a crash on Android 12 and older when trying to access any text controls
fix stylus workarounds for Xiaomi and OnePlus to work properly
Check out the release notes for a full overview of all the new features in Krita 5.3 and 6.0.
Note: this release is only relevant for Android, so only Android APK's and source archives are available. You only need the source archive when building for Android yourself.
[!WARNING]
One again, we consider Krita 5.3.1 suitable for productive work; 6.0.1 is, because of the many changes from Qt5 to Qt6 more experimental.
5.3.1.1 Download
Android
Krita on Android is still beta; and is meant to run on chromebooks and tablets only.
Evaluating and starting to develop professional, production-grade GUIs on embedded Linux should be frictionless. Based on this statement, we are always working with our partners to improve the Qt developer experience. Together with Toradex we recently made major improvements to the Torizon Qt VS Code template, making it easier for you as a developer to use Qt Device Creation Enterprise workflows inside the same template that you might already have been using with the Device Creation Community Edition. On top of that, there is a brand-new Qt demo in the Torizon Demo Gallery which you can try right away.
Torizon is a production-ready, container-based embedded Linux platform that simplifies how Qt applications are deployed and maintained. Qt developers may already be familiar with Boot2Qt, which is a useful tool to get a Qt prototype running quickly. However, scaling that prototype into a secure, maintainable, and updatable product usually requires building and managing your own Yocto stack. Torizon removes this burden, providing a pre-integrated OS, hardware-optimized Qt runtime, OTA automated updates, CVE tracking and a consistent containerized workflow, letting you focus entirely on your Qt application instead of maintaining the underlying Linux distribution.Below you’ll find what’s new, why it helps Qt developers, and exactly how to try it.
Explore how SWHID is applied in real-world scenarios to improve SBOMs, support Cyber Resilience Act compliance, and enable software traceability. Discover practical use cases across telecom and automotive industries, based on insights from recent industry talks.
At the first start of an application, user can be a bit confused in front of all of these features, buttons and data.
In response to that, we often have a short presentation of each element on the screen.
This also presents a typical workflow with the application.
First, You need to create a project or document.
Then, define the name, the type…
Then add content using this or that.
This feature is often called UI walk through, or UI tour.
UI Walker
I made this library to provide an easy way to do a walkthrough in any QML application.
Using cmake it is really easy. You can define the library to be a git submodule and then
Prepare you qml code
The whole concept is based on attached property.
To highlight a item, you must define two properties:
WalkerItem.description: the text that will be displayed when this element is highlighted
WalkerItem.weight: Numeric value to define the order (ascending order).
ToolButton {
WalkerItem.description: qsTr("Description of the element")
WalkerItem.weight: 104
}
Add the UI walker
Currently, you have to add one item. It should have the size of the whole window.
This item provides several properties in order to help you manage the output.
Highlighted items get notified through two signals: enter and exit.
Defining signal handlers allow you to react. So you can show the full workflow to add new data.
In order, to start the UI tour, you simply have to call the function: start() of the Item.
Of course, it is up to you to trigger it automatically when it’s the first start of the application or if the user asked for the tour.
I have a CPP controller with property UiTour which gives the current status of the tour.
Here, I call directly the walker function. But it may be safer to call a function to reset the state of the window.
Navigation
The walker provides two important function next() and previous() to navigate.
Basically on the walker, you can add buttons in the available Rect to manage the navigation.
Other option, you can define an interval in milliseconds which will call the next() function.
You have to make sure the item is visible while the walker highlight it. It could be tricky to make the path from the end to be beginning. In some case, it is easier to never use the previous function.
Finish it!
Calling the function skip(), close the walker. Then the application is displayed normally.
It can be called at any time.
Cheat code
Function
description
start()
The walker becomes visible, and the first item is highligthed
next()
Highlight the next item, trigger appropriated signals
previous()
Highlight the previous item, trigger appropriated signals
skip()
Hide the walker
How it works ?
The attached properties
In order to harvest all data from the QML, I had to define attached property.
This is the definition of QObject which will be attached, each time a QML item has defined any Walker property.
In the WalkerItem.h, I have to create this static function.
// …
Q_OBJECT
QML_ATTACHED(WalkerAttachedType)
// …
static WalkerAttachedType* qmlAttachedProperties(QObject* object)
{
QQuickItem* item= qobject_cast<QQuickItem*>(object);
if(!item)
qDebug() << "Walker must be attached to an Item";
s_items.append(item);
return new WalkerAttachedType(object);
}
QSceneGraph and Nodes
WalkreItem defines a QML item, written in cpp to be light-weighted.
I used QSGNode to draw it on screen. The item code manages the logic of the walkthrough and the update of the geometry.
To make it short, the SceneGraph is the rendering engine of QML. QSGNode defines an API to communicate with it directly.
First, I create the QML item in cpp, using QSGNode to be rendered.
//walkeritem.h
class WalkerItem : public QQuickItem
{
Q_OBJECT
QML_ATTACHED(WalkerAttachedType)
QML_ELEMENT
Q_PROPERTY(QString currentDesc READ currentDesc NOTIFY currentChanged FINAL)
Q_PROPERTY(QColor dimColor READ dimColor WRITE setDimColor NOTIFY dimColorChanged FINAL)
Q_PROPERTY(qreal dimOpacity READ dimOpacity WRITE setDimOpacity NOTIFY dimOpacityChanged FINAL)
Q_PROPERTY(QRectF availableRect READ availableRect NOTIFY availableRectChanged FINAL)
Q_PROPERTY(QRectF borderRect READ borderRect NOTIFY borderRectChanged FINAL)
Q_PROPERTY(int interval READ interval WRITE setInterval NOTIFY intervalChanged FINAL)
Q_PROPERTY(bool active READ active NOTIFY activeChanged FINAL)
public:
WalkerItem();
// accessors, signals, slots…
protected:
QSGNode* updatePaintNode(QSGNode*, UpdatePaintNodeData*) override;// update scenegraph
};
//walkeritem.cpp
WalkerItem::WalkerItem()// in the constructor
{
setFlag(QQuickItem::ItemHasContents);// must be called
connect(child, &QQuickItem::widthChanged, this, &WalkerItem::updateComputation);
connect(child, &QQuickItem::heightChanged, this, &WalkerItem::updateComputation);
}
void WalkerItem::updateComputation()
{
// compute geometry and list any changes that must be sync with the SceneGraph.
m_change|= WalkerItem::ChangeType::GeometryChanged;
update();// call to paint the item
}
QSGNode* WalkerItem::updatePaintNode(QSGNode* node, UpdatePaintNodeData*)
{
auto wNode= static_cast<WalkerNode*>(node);
if(!wNode)
{
wNode= new WalkerNode();//first time
}
if(m_change & WalkerItem::ChangeType::ColorChanged)
wNode->updateColor(m_dimColor);
if(m_change & WalkerItem::ChangeType::GeometryChanged)
wNode->update(boundingRect(), m_targetRect);
if(m_change & WalkerItem::ChangeType::OpacityChanged)
wNode->updateOpacity(m_dimOpacity);
m_change= WalkerItem::ChangeType::NoChanges;
return wNode;
}
We have here an item with a geometry like any other item (x,y,width, height), we also have a dimColor and dimOpacity.
Any time one of these properties change. I have to sync with the QSceneGraph to update either the geometry, the dimColor or the dimOpacity.
Each time, one property changes, I stored the type of change in the m_change member and I call update().
The render engine will call my item with the QSGNode reprenting it on the SceneGraph side.
Then I can call function on my SGNode. When sync is finished I reset the change to NoChange and return the node.
The updatePaintNode can be called with a null node. In this case, you have to create it. It will be the case, the first time. And it could happen later in some cases for optimalization reason.
Now, let see the code of the QSGNode. You have to see the QSGNode as the root item of a tree. Where each node is in charge of representing one aspect of the item: its geometry, its color and its opacity.
void WalkerNode::update(const QRectF& out, const QRectF& in)
{
// out is the geometry of the window
// in is the geometry of the highlighted item
const auto a= out.topLeft();
const auto b= in.topLeft();
const auto c= in.topRight();
const auto d= out.topRight();
const auto e= in.bottomRight();
const auto f= out.bottomRight();
const auto g= in.bottomLeft();
const auto h= out.bottomLeft();
{
auto gem= m_dim.geometry();
auto vertices= gem->vertexDataAsPoint2D();
QList<std::array<QPointF, 3>> triangles{{a, b, d}, {b, d, c}, {d, c, f}, {c, f, e},
{f, e, h}, {e, g, h}, {h, g, a}, {g, a, b}};
int i= 0;
for(auto t : triangles)
{
vertices[i + 0].set(t[0].x(), t[0].y());
vertices[i + 1].set(t[1].x(), t[1].y());
vertices[i + 2].set(t[2].x(), t[2].y());
i+= 3;
}
m_dim.markDirty(QSGNode::DirtyGeometry | QSGNode::DirtyMaterial);
}
markDirty(QSGNode::DirtyGeometry | QSGNode::DirtyMaterial);
}
We split the surface we have to cover in triangles.
Todo
Animations: Smooth animation while transiting from one item to another.
Test on bigger apps
Find a logic to allow previous
Use shader effect to make it better.
Other…
Conclusion:
UiWalker is already in production. It works like a charm. I hope to use it elsewhere. Then, I will add some new features. Contributions and comments are welcomed.
Tuesday, 7 April 2026. Today KDE releases a bugfix update to KDE Plasma 6, versioned 6.6.4.
Plasma 6.6 was released in February 2026 with many feature refinements and new modules to complete the desktop experience.
This release adds three weeks’ worth of new translations and fixes from KDE’s contributors. The bugfixes are typically small but important and include:
The last post regarding work on fixing Oxygen was a month and a half ago. With all that's happened in between, it feels like so much more time has actually passed. With this post, I'd like to do a sort of mid-term update summing up all of the improvements done so far. These improvements are...... Continue Reading →

 smankowski
smankowski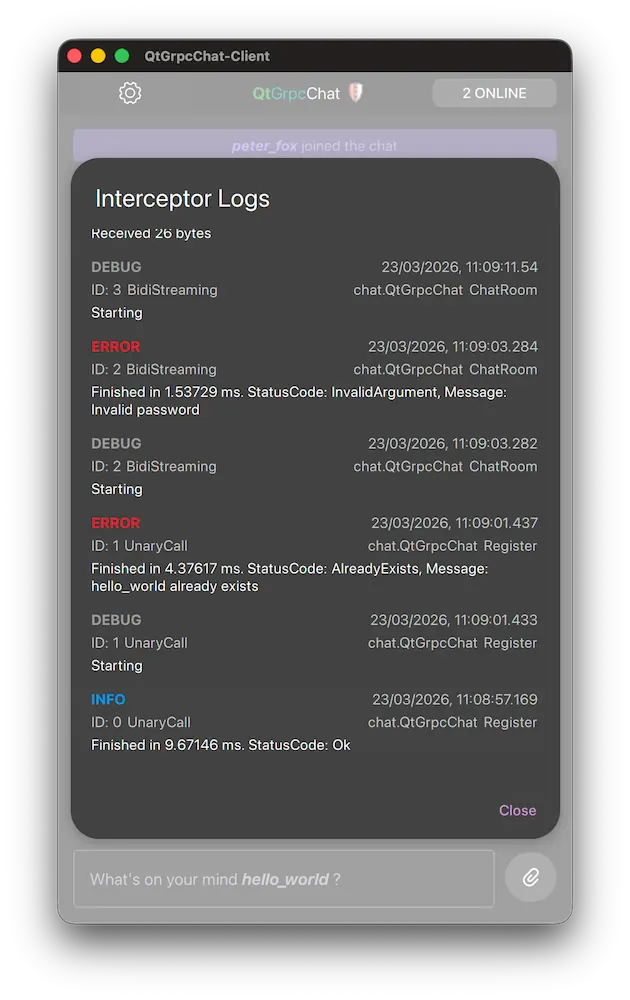



 obiwan_kennedy
obiwan_kennedy



 @shibe_13:matrix.org
@shibe_13:matrix.org