Plasma Settings gained the ability to show all settings modules (for all platforms, such as desktop) under a toggle. It now supports the ability to show an "Apply" button for settings modules that do not want settings to save automatically. The header being misaligned on category pages is now fixed.
Please note: most Plasma Mobile software is now shipped under the Plasma or KDE Gearrelease cycles.
Merge requests (MR) are a useful feature in version control systems to propose changes to large codebases. This helps keep track of major changes and organize individual contributions. This week I created a draft MR to keep track of my progress and to gain constructive feedback.
Draft MR
Why use draft MRs instead of just a separate development branch? I'm glad you asked! Compared to a development branch, a draft MR includes commits from your development branch, reviewers can create threads (such as TODO tasks or add comments), and major changes can be tracked so a reviewer has more context behind your changes. On a project with hundreds or thousands of contributors, development branches can be difficult to manage.
Progress
In my draft MR I received valuable feedback and made improvements. So far, I added licensing information, removed placeholder comments (following best practices), and implemented the rendering of the floating bar on Selection Tool activation. I wouldn’t have been able to make these important changes or get one step closer to building out the feature without the feedback. On top of this, by getting feedback through a draft MR, I am able to look back at old threads or comments easily compared to reading IRC or chat through Matrix, which can have multiple active conversations at once.
Conclusion
Getting feedback can be tough if you cannot convey your question properly, cannot provide an example, or you cannot find the appropriate time to ask. Through a draft MR, I was able to get constructive feedback that led to small improvements I could make immediately, instead of creating an MR later down the road and making large changes. This also provides me an opportunity to check in with the community outside of IRC.
I learned that certain modes of communication can be more beneficial than others given the circumstances and keeping track of progress in a transparent manner helps you grow as a developer.
Contact
To anyone reading this, please feel free to reach out to me. I’m always open to suggestions and thoughts on how to improve as a developer and as a person. Email: ross.erosales@gmail.com Matrix: @rossr:matrix.org
Today, I am announcing a new release of Plasma Camera, a camera application for Plasma Mobile (though it can also be used on desktop!). This release ports the application to use libcamera as the backend for interfacing with cameras, finally allowing for it to be used on Linux mobile devices (such as the OnePlus 6).
The main porting work was done by my friend Andrew (koitu) a couple of months ago. It remained stalled on some issues, so I picked it up in the past week to complete the port and finish the application. Here is a link, which has more technical details!
Cameras have been a long neglected area in Plasma Mobile, ever since the focus shifted from halium to mainline devices. With mainline devices, libcamera drivers have been developed for them, allowing for cameras to be used in applications over Pipewire (ex. GNOME Snapshot, Firefox, Chromium).
Plasma Camera was originally created in 2019 with halium devices in mind, using the official Qt Camera library as a backend for interfacing with cameras. This library allows for the app to work on Android and on desktop with USB webcams. Unfortunately, Qt Camera does not currently have support for using Pipewire or libcamera directly as a backend, and so is unable to interface with the cameras on the OnePlus 6 and Pixel 3a.
Qt Camera is a fairly high-level API designed to abstract over many different platforms, beyond Linux. Since our focus is on Linux, we decided to take this chance to port Plasma Camera to use libcamera directly for best control over the camera pipeline and features. Note that this approach differs from some other camera applications that use Pipewire, which has a backend to communicate with libcamera.
In order to implement the viewfinder (camera preview), we create a worker thread that is responsible for polling the camera for frames. A series of “requests” with a framebuffers allocated to each were created, which we cycle through when polling for frames. Libcamera then gives us a frame for each poll request, in which we send to our application thread to display.
For simplicity, Qt Multimedia was used for media processing. Frames from libcamera are wrapped in QImages and sent to a QVideoSink to be displayed in the UI. Any transformations needed (such as rotation correction due to how sensors are mounted on phones, or mirroring for front-facing cameras) are done before the frame is added to the sink. For taking photos and videos, we reuse the viewfinder’s frames.
For photos, we simply write the QImage to the disk.
Videos are much more tricky. Using Qt Multimedia we can build a video processing pipeline. We create a QMediaCaptureSession to facilitate all of the inputs and outputs needed. We then attach a media recorder QMediaRecorder for writing the video, an audio input (QAudioInput) and a video input (QVideoFrameInput). We have a separate polling timer that polls at the framerate of the video (which can differ from the framerate of the viewfinder), copying frames one-by-one into the QVideoFrameInput instance (more on this later) to be encoded by QMediaRecorder.
In the future, it may make sense to investigate whether we could benefit from porting to using GStreamer directly for media processing. We currently use Qt Multimedia with its ffmpeg backend. While Qt Multimedia does have an gstreamer backend, it has some limitations and was thus removed from being the default backend as a result.
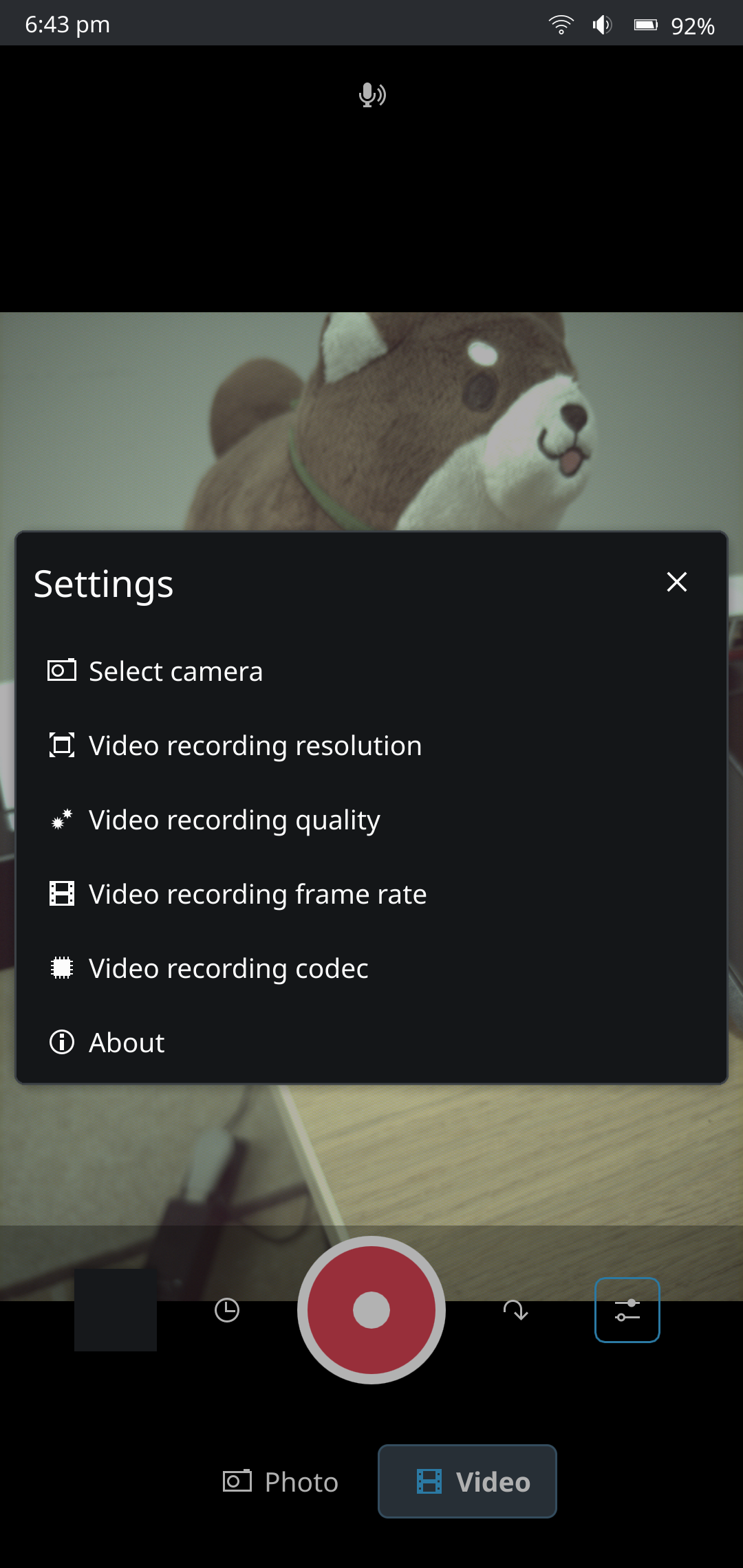
I also took the liberty of doing some substantial refactoring and reworking of the UI code. We dropped some camera settings for the initial port of the application, to be restored later. However some other features were introduced.
The application has these features:
Photo capture
Video capture
Audio recording toggle for video capture
EV setting (exposure value)
Captured photo/video preview
Video recording settings (codec, resolution, FPS, quality)
Timer before taking a photo
Warnings for when the encoder is detected to not be keeping up with the video stream
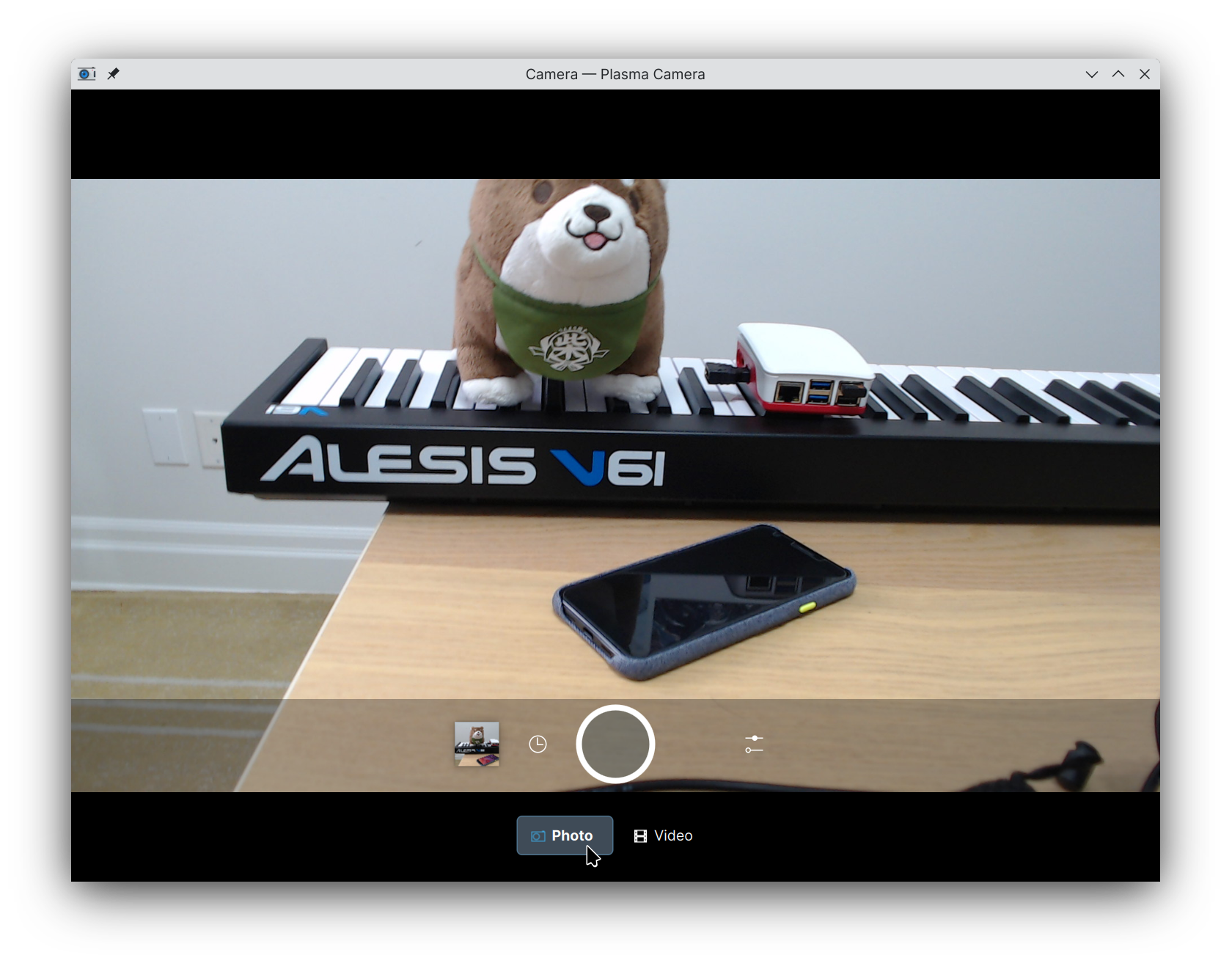
With USB webcams, both photo capture and video recording work.
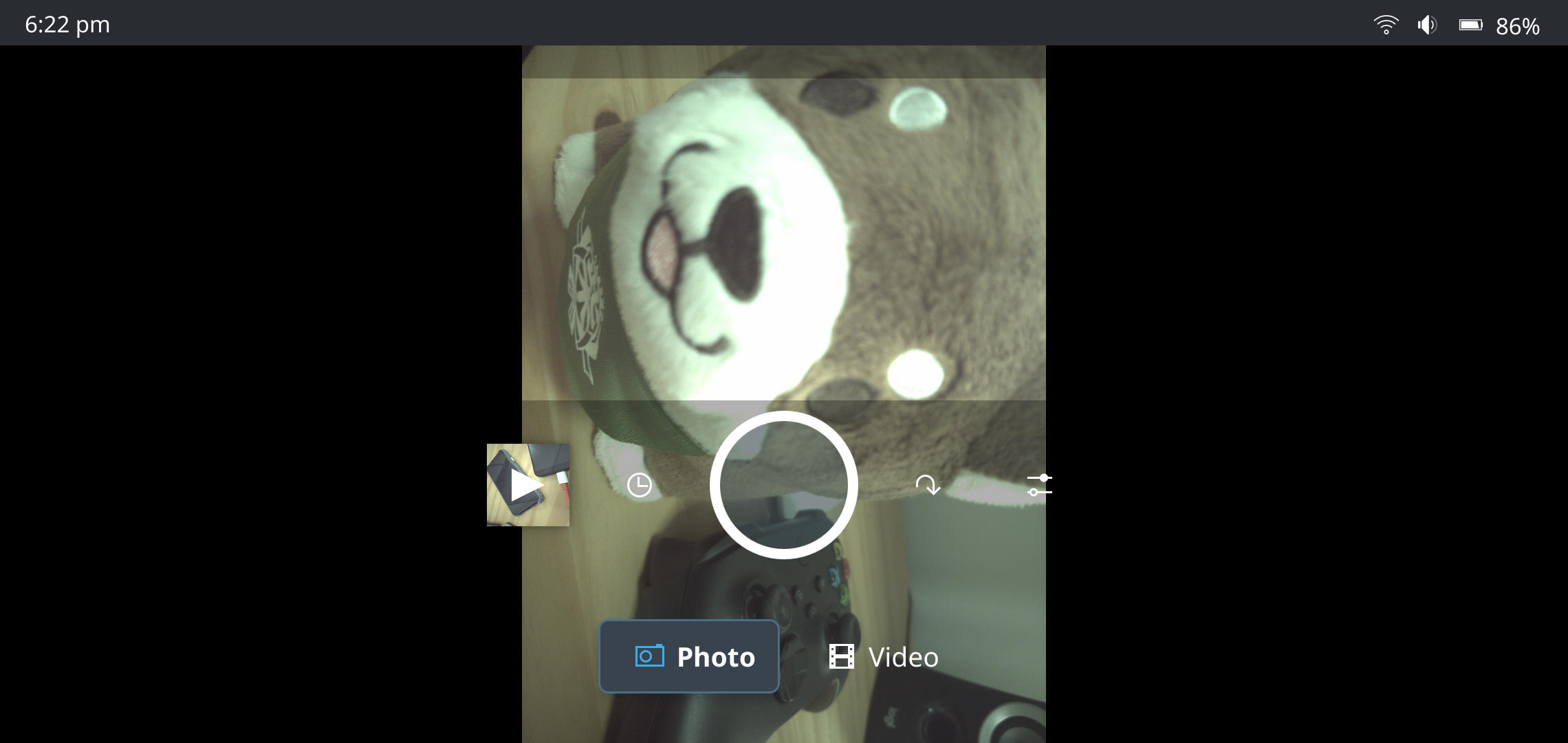
It also sort of works on phones. I tested on the OnePlus 6 and Pixel 3a. I suspect that most of the issues are simply due to the camera driver not yet being mature enough, as I can replicate most of the issues on other camera applications. The photo quality and colours are not optimal, and there appears to be a fixed focal length, and so far away things look blurry.
The viewfinder stream is fine on my OnePlus 6 and looks smooth. However, for my Pixel 3a, the frames start flashing light and dark colours when I point the camera at any bright light source. I suspect it is due to the camera driver overcompensating for exposure perhaps? Not sure 😅
Photo capture works on both devices, outputting the frame from the viewfinder at full resolution to the disk almost instantly. Though the quality of the pictures is reminiscent of early 2000s phone photography.
The video recording experience however isn’t quite usable unfortunately, the video encoder does not appear to be able to keep up.
The main barrier to video recording seems to be the performance of the video encoder. I’ve noticed on both phones that many frame calls to QVideoFrameInput fail because QMediaRecorder’s queue is simply full and cannot keep up with the amount of frames coming in. This can be mitigated somewhat by playing with the video recording settings. I’ve generally found the MPEG2 codec to be substantially faster for devices, though it gives very ugly artifacting at low quality, and sometimes gives an error. Of course, lowering the resolution and FPS also can help too.
For each frame given to QVideoFrameInput, I also set its timestamp to ensure that the encoder places it at the correct place. However, when we start dropping frames due to the encoder being full, we end up with gaps in the video without a frame, which I suspect is what is causing the pixelated “corrupt video” effect (though it only happens with H264, and not MPEG2 encoding?). We cannot really queue frames for the encoder, because we would very quickly run out of memory. I have an open issue about this since I am not really sure how to address it yet.
Device rotation can be a bit of a problem with the application right now. We already account for the screen orientation in comparison to the camera orientation, which is reported as a property by libcamera.
The viewfinder however can be a problem when the display rotation is different from the screen’s orientation (ex. rotated 90, 180, 270 degrees). This is done by the compositor (ex. KWin), the application only sees that the window size has changed. However, that means the viewfinder is rotated as well! We are able to adjust for this in taken photos and video by reading the rotation sensor data (with QOrientationSensor/iio-sensor-proxy), however we cannot do the same for the viewfinder because we don’t know which orientation the compositor has the application in, which could be different from the sensor due to rotation-lock and manual settings.
I recommend keeping an orientation lock on “portrait” mode when using the application on a phone until we find a fix, that way the viewfinder does not get mismatched from what you see. We are tracking this issue here: https://invent.kde.org/plasma-mobile/plasma-camera/-/issues/14
The drivers for the OnePlus 6 and Pixel 3a seem to be missing almost all of the libcamera controls. At least, calling camera->controls() (doc) gives only the Contrast control from libcamera. There are other controls that I would like to implement once they become available, such as focus windows.
Once these are implemented in the driver (or if it’s fixed as an issue on our side) and support is added in the application, we will have a lot more camera features to play with!
We finally have a base on to use for the camera stack on Linux mobile. I hope the application continues to improve as drivers and camera support get better over time on these devices.
Kirigami Addons is a collection of supplementary components for Kirigami
applications. Version 1.9.0 is a relatively minor release, introducing two new
form delegates along with various quality-of-life enhancements.
New Features
I took over the work from Tomasz Bojczuk and finished the addition of the file and folder form delegate.
These two components wrap a FileDialog and FolderDialog respectively and like KUrlRequester in KIO provide a text field with autocompletion on desktop. Currently the autocompletion is a bit basic and is based on a Controls.TextField with a Controls.Popup, but hopefully with Qt 6.10 we can use Controls.SearchField.
Bug fixes
Outside of these two new components, this release includes minor fixes and improvements from Antonio Rojas, Nicolas Fella Soumyadeep Ghosh, Thiago Sueto, Volker Krause and Yuki Joou.
This week, I revisited the KUiServerJobTracker issue in the PIM Migration Agent. After last week’s D-Bus debugging and architectural cleanup, it became clear that replacing it entirely was more complex than initially expected.
After discussing with my mentor Carl, he summarized the situation in an email to the KDE PIM mailing list. In it, he outlined the limitations we were facing:
“The agent relies on KUiServerJobTracker, which aside from requiring a port to KUiServerV2JobTracker, also has the issue that it links to QtWidgets while not using QWidget itself.”
The email resulted in feedback from Volker Krause. In his response he agreed with one of Carl’s suggestion that I ultimately pursued: rather than remove the job tracker altogether or build an entirely new progress infrastructure, I created a local copy of KUiServerV2JobTracker inside the kdepim-runtime repository and carefully stripped out its QtWidgets linkage.
This forked version is temporary and self-contained, with a clear path to removal once the upstream KDE Frameworks address the QtWidgets dependency—likely by KF7. It allowed me to retain proper system tray integration for job tracking (which AgentBase’s built-in D-Bus support cannot currently provide), while still meeting the goal of removing QtWidgets from the Migration Agent’s core.
Shedding the Final Dependencies
With the tracker replaced, I focused on removing the last traces of QtWidgets from the Migration Agent. This included cleaning up the custom D-Bus interface and eliminating now-redundant methods. The final dependencies were located in individual subcomponent CMakeLists.txt files, which were still linking against QtWidgets.
After updating those, the result is a fully decoupled agent:
The PIM Migration Agent’s core logic is now completely free of QtWidgets.
In addition, I integrated the manual migration tasks into the job executor, allowing them to report progress using the same job tracking mechanisms as the automated tasks.
A New Akonadi Capability: SingleShot Agents
The mailing list discussion also highlighted another inefficiency: the Migration Agent doesn’t need to run persistently. As Volker suggested:
“Keep it as an agent but give it a special ‘SingleShot’ flag… with Akonadi shutting it down again automatically once done.”
Building on this idea, I introduced a new Akonadi capability: SingleShot agents. This lets agents perform their work once and automatically exit afterward, conserving system resources.
The mechanism works as follows:
An agent declares X-Akonadi-Capabilities=SingleShot in its .desktop file.
When launched, the agent does its work.
Once finished, it emits a new finished() D-Bus signal.
The Akonadi manager listens for this signal and terminates the agent process.
This pattern fits well with agents like the Migration Agent that don’t need to remain active beyond their immediate tasks.
Current Status and What’s Next
Draft merge requests for both akonadi and kdepim-runtime are already open to gather feedback on the SingleShot capability and the updated job tracking approach.
The only remaining issue is that the finished() signal doesn’t seem to shut down the agent as expected when testing through akonadiconsole. Debugging this signal propagation is my focus for the upcoming week. Once resolved, the agent will fully behave as a lightweight, on-demand component.
This week’s changes not only complete the agent’s QtWidgets decoupling but also introduce a meaningful architectural improvement to Akonadi itself—one that may benefit other agents in the future.
After my initial status blog, I was really surprised to see so much support and excitement about Karton, and I’m grateful for it!
A few weeks have gone by since the official coding period for Google Summer of Code began. I wanted to share what I’ve been working on with the project!
VM Installer
Earlier last month, I was finishing up addressing feedback (big thanks again to Harald) on the VM installer-related MR. I had made some improvements to memory management, bug fixes related to detecting ISO disks, as well as refactoring of the class structures. I also ported it over to using QML modules, which is much more commonly used in KDE apps, instead of exposing objects at runtime.
After a bit more review, this has now been merged into the master branch! This was what was featured in the previous demo video and you can find a list of the full changes on the commit.
SPICE Client
Two weeks ago, I started to get back to work on my SPICE viewer branch. This is the main component I had planned for this summer.
It took a few days to clean up my code that connects to the SPICE display and inputs channel.
However, a lot of my time was spent trying to get a properly working frame buffer that grabs the VM display from SPICE (spice-client-glib) and renders it to a native KDE window. The approach I originally took was rendering the pixel array I received to a QImage which could be drawn onto a QQuickItem to be displayed on the window. It listens to SPICE callbacks to know when to update, and was pretty exciting to see it rendering for the first time!
One of the most confusing issues I encountered was when I was encountering weird colour and transparency artifacts in my rendering. I initially thought it was a problem due to the QImage 32-bit RGB format I was labelling the data as, so I ended up going through a bunch of formats on the Qt documentation. The results were very inconsistent and 24-bit formats were somehow looking better, despite SPICE giving me it in 32-bit. Turns out (unrelatedly), there was some race condition with how I was reading the array while SPICE was writing to it, so manually copying the pixels over to a separate array did the trick.
Here are nice pictures from my adventures!
my first time properly seeing the display… (also in the wrong format) ( •͈ ૦ •͈ )
I have also set up forwarding controls which listens to Qt user input (mouse clicks, hover, keyboard presses) and maps coordinates and events to SPICE messages in the inputs channel. Unfortunately, Qt key event scancodes seem to be in evdev format while SPICE expects PC XT. Currently, I have been manually mapping each scancode, but I might see if I can switch to use some library eventually.
Once I polish this up, I hoping to merge this into master soon. It’ll likely be very slow and barebones, but I’m hoping I can make more improvements later on!
still very lagging scrolling, but now we can read Pepper & Carrot!
What’s Next?
While relatively simple, I noticed my approach is quite inefficient, as it has to convert every received frame to a QImage, and suffers from tearing when it has to update quickly (ex: scrolling, videos).
SPICE has a gl-scanout property which is likely much more optimized for rendering frames and I plan on looking into switching over to that in the long-term.
I also need to implement audio forwarding, sending proper mouse drag events, and resizing the viewing window.
On a side note, I also helped review a nice QoL feature from Vishal to list the OS variants in the installation dialog. I’ve just been memorizing them up until now… :')
Hopefully, once I get the SPICE viewer to a reasonable state, I can get back to improving the installation experience further like adding a page to download ISOs from.
As I mentioned a bit previously, I also want to rework the UI eventually. This means spending time to redevelop the components to include a sidebar, which is inspired by UTM and DistroShelf.
Lastly,
I also wanted to make a bit of a note on my plans and hopes throughout the GSoC period. After working on developing these different components of the app, I started to realize how much time goes into polishing, so I believe that I need to prioritse some of the most important features and making them work well.
Overall, it’s been super busy (since I’m also balancing school work), but it has been quite exciting!
Over the past couple of weeks, Timothée Giet has been working on a mock-up tablet and phone friendly UX for Krita. This is a PROTOTYPE, it’s not a working version of Krita. You can’t paint, for instance, or load an image. But you can play with the way the user interface works, and changes depending on orientation and screen size.
The amazing thing, for me, is that unlike our old Krita Sketch, this really looks and feels like Krita, only for mobile touch screens. It’s like this user interface speaks the same language as the desktop interface, krita-ese, I guess you can call it.
Just compare the difference:
Krita Sketch, from 2012The main interface Timothee imagined for Krita.
There’s also a welcome screen:
It works really well and feels really good and logical. Now keep in mind that this is a prototype, and integrating Krita’s canvas with this prototype is going to be quite tough for really complicated technical reasons — and the prototype doesn’t connect to any of Krita’s code at all. So don’t go expecting this to show in the Play Store any time soon!
But I am still really excited!!! Timothée Giet is doing a great job here!
Hi, I'm thrilled to be part of Google Summer of Code 2025 with KDE Community, working under the mentorship of Carl Schwan, Claudio Cambra, and Aakarsh MJ. My project, "Modernize Account Management with QML," aims to enhance the account management system in Merkuro, by transitioning its resource configuration dialogs to QML. This blog post introduces my project and shares the progress I've made in the recent weeks.
About the Project -
Merkuro currently relies on QWidget-based dialogs for managing account resources, which, while functional, are not optimized for modern platform usability, especially on touch devices or diverse platforms. My project addresses this by porting resource configuration dialogs to QML, a modern, flexible, and responsive UI framework, while maintaining compatibility with existing QWidget-based systems. The goal is to create a shared infrastructure that supports both QWidget and QML-based configurations, enabling a seamless transition to modern UI development without disrupting existing functionality.
The project has two main components:
Building a Shared Infrastructure: Creating a foundation that supports both QWidget and QML-based configuration dialogs for Akonadi agents, ensuring backward compatibility and scalability.
Porting SingleFileResource-Based Configurations: Migrating singlefileresource based configurations, such as the ical, vcard, etc to QML to provide a modern, responsive user experience.
Benefits to KDE Community -
Porting Merkuro's account management to QML offers significant benefits:
For Users: QML-based dialogs provide a smoother, more intuitive, and visually engaging experience. QML's flexibility supports dynamic and touch-friendly interfaces, making account management more accessible on various devices, from desktops to mobile platforms.
For Developers: The shared infrastructure improves modularity and maintainability, allowing developers to adopt QML at their own pace without breaking legacy systems. This sets the stage for future QML-based UI development in Akonadi and beyond.
Progress So Far -
1. Implemented Shared Infrastructure for Akonadi
To support both QWidget and QML-based configurations in Akonadi, I developed a new infrastructure in following way:
AbstractAgentConfiguration: A new base class defining standard methods (load(), save(), etc.) for consistent configuration handling.
AgentConfigurationBase: Updated to inherit from AbstractAgentConfiguration, ensuring compatibility with existing QWidget-based dialogs.
QuickAgentConfigurationBase: A new class inherited from AbstractAgentConfiguration, enabling QML-based configurations via shared QML engine for dynamic UIs.
QuickAgentConfigurationFactoryBase: A factory for QML-based configuration instances, complementing the QWidget factory.
This infrastructure, inspired by KCMUtils, enables Akonadi to handle both legacy and modern UI paradigms seamlessly.
2. Ported Knut Configuration Dialog to QML
I removed QWidget based code and then implemented Knut configuration dialog in QML.
And currently working on porting singlefileresource based dialogs....
Challenges Faced -
The progress came with several challenges that shaped my learning:
Testing the QML Infrastructure: Validating the new QML infrastructure during development was difficult, as it required a functional QML-based dialog to test fully. I could only verify the infrastructure’s correctness after porting the Knut configuration to QML, which delayed feedback and required iterative adjustments.
Navigating KDE’s Modular Ecosystem: KDE's ecosystem is vast and modular so understanding each of them is very important. Recently, I spent around hour looking for the Knut configuration dialog in Merkuro only to find out (thanks to Carl) that it actually lives in KOrganizer’s test suite! I was actually unaware of this.
And of course, compiling errors and warnings were always there to keep me company :)
Thank you and stay tuned for the next part, where I’ll share more updates and learnings from my GSoC journey!


 @rossr:matrix.org
@rossr:matrix.org





 CarlSchwan
CarlSchwan