Hi, I'm thrilled to be part of Google Summer of Code 2025 with KDE Community, working under the mentorship of Carl Schwan, Claudio Cambra, and Aakarsh MJ. My project, "Modernize Account Management with QML," aims to enhance the account management system in Merkuro, by transitioning its resource configuration dialogs to QML. This blog post introduces my project and shares the progress I've made in the recent weeks.
About the Project -
Merkuro currently relies on QWidget-based dialogs for managing account resources, which, while functional, are not optimized for modern platform usability, especially on touch devices or diverse platforms. My project addresses this by porting resource configuration dialogs to QML, a modern, flexible, and responsive UI framework, while maintaining compatibility with existing QWidget-based systems. The goal is to create a shared infrastructure that supports both QWidget and QML-based configurations, enabling a seamless transition to modern UI development without disrupting existing functionality.
The project has two main components:
Building a Shared Infrastructure: Creating a foundation that supports both QWidget and QML-based configuration dialogs for Akonadi agents, ensuring backward compatibility and scalability.
Porting SingleFileResource-Based Configurations: Migrating singlefileresource based configurations, such as the ical, vcard, etc to QML to provide a modern, responsive user experience.
Benefits to KDE Community -
Porting Merkuro's account management to QML offers significant benefits:
For Users: QML-based dialogs provide a smoother, more intuitive, and visually engaging experience. QML's flexibility supports dynamic and touch-friendly interfaces, making account management more accessible on various devices, from desktops to mobile platforms.
For Developers: The shared infrastructure improves modularity and maintainability, allowing developers to adopt QML at their own pace without breaking legacy systems. This sets the stage for future QML-based UI development in Akonadi and beyond.
Progress So Far -
1. Implemented Shared Infrastructure for Akonadi
To support both QWidget and QML-based configurations in Akonadi, I developed a new infrastructure in following way:
AbstractAgentConfiguration: A new base class defining standard methods (load(), save(), etc.) for consistent configuration handling.
AgentConfigurationBase: Updated to inherit from AbstractAgentConfiguration, ensuring compatibility with existing QWidget-based dialogs.
QuickAgentConfigurationBase: A new class inherited from AbstractAgentConfiguration, enabling QML-based configurations via shared QML engine for dynamic UIs.
QuickAgentConfigurationFactoryBase: A factory for QML-based configuration instances, complementing the QWidget factory.
This infrastructure, inspired by KCMUtils, enables Akonadi to handle both legacy and modern UI paradigms seamlessly.
2. Ported Knut Configuration Dialog to QML
I removed QWidget based code and then implemented Knut configuration dialog in QML.
And currently working on porting singlefileresource based dialogs....
Challenges Faced -
The progress came with several challenges that shaped my learning:
Testing the QML Infrastructure: Validating the new QML infrastructure during development was difficult, as it required a functional QML-based dialog to test fully. I could only verify the infrastructure’s correctness after porting the Knut configuration to QML, which delayed feedback and required iterative adjustments.
Navigating KDE’s Modular Ecosystem: KDE's ecosystem is vast and modular so understanding each of them is very important. Recently, I spent around hour looking for the Knut configuration dialog in Merkuro only to find out (thanks to Carl) that it actually lives in KOrganizer’s test suite! I was actually unaware of this.
And of course, compiling errors and warnings were always there to keep me company :)
Thank you and stay tuned for the next part, where I’ll share more updates and learnings from my GSoC journey!
This week I learned how to tweak the UI using Qt modules, specifically Qt GUI classes. As someone new to C++ and Qt, I’ve found that official documentation for any new technology is always helpful in understanding the basic concepts and framework. Reading official documentation is like using an encyclopedia—you may not read it cover to cover, but you can search for key concepts to help navigate what you’re trying to do.
Before and After
QPainter
After researching how the Assistant Tool is drawn on the canvas, I thought I could use that same logic to draw on the floating bar. In the process, I found that the Assistant Tool has a lot of nested logic, inheriting different widget classes, and referencing various Kis objects that need to be built. After debugging countless times to find where this tool is drawn, I found the QPainter class. To keep it simple, this class draws lines and shapes in different colors. For now my goal is to display a floating bar.
Files and Implementation
/krita/libs/ui/ kis_painting_assistants_decoration.h kis_painting_assistants_decoration.cpp _ new kis_selection_assistants_decoration.h kis_selection_assistants_decoration.cpp
The files I focused on are in the path above. For organization, I made new files in the same directory. In kis_selection_assistants_decoration, the QPainterPath class is used to build the floating bar. This is slightly different from QPainter, as a QPainterPath object only needs to be created once for complex shapes.
To display and test the floating bar I used kis_painting_assistants_decoration::drawDecoration() method call to call kis_selection_assistants_decoration::drawDecoration().
Conclusion
This week I took a deeper dive into how Krita's UI is structured in Qt. By exploring how the Assistant Tool is created, I learned, I learned how core classes like QPainterPath interact with the canvas. Through this experience, I gained a solid starting point for UI-related work in Krita. There’s still much more to learn and improve on, but seeing a visual element I wrote appear on the canvas was a big milestone!
Contact
To anyone reading this, please feel free to reach out to me. I’m always open to suggestions and thoughts on how to improve as a developer and as a person. Email: ross.erosales@gmail.com Matrix: @rossr:matrix.org
After four months of active maintenance and many weeks triaging bugs, the digiKam team is proud to present version 8.7.0 of its open source digital photo manager.
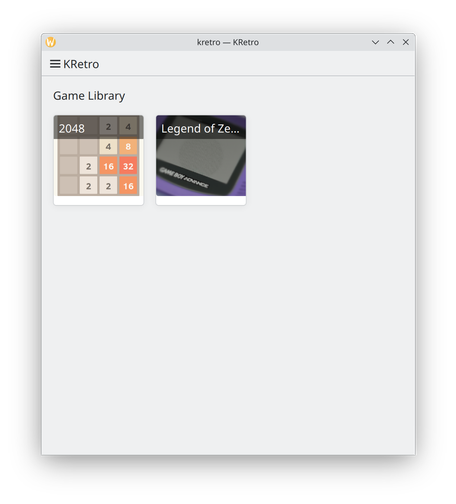
Improvements in Photos, KRetro and better keyboard navigation
Welcome to a new issue of "This Week in KDE Apps"! Every week (or so) we cover as much as possible of what's happening in the world of KDE apps.
As you might have noticed, the frequency of "This Week in KDE Apps" has not been very consistent lately. Particularly during the summer season, I (Carl) have a lot of social obligations and can't ensure regular updates with the small amount of time I have available. If you are a KDE developer, you can help by contributing your updates to the GitLab merge request on invent. In that respect, a huge thanks to Felix Ernst for doing that already for Dolphin.
Getting back to all that's new in the KDE App scene, let's dig in!
Akseli Lahtinen increased the click area of files and folders in the main view and overhauled their styling. It's (subjectively speaking) a lot prettier now! We are trying to make Dolphin more consistent with other list styles in KDE long-term (25.08.0 - link).
Méven Car added a colorful folder icon chooser to the context menu of folders (25.08.0 - link). The Dolphin context menu can be edited in Dolphin's settings window.
Aleksandr Borodetckii lowered the default scroll speed to follow the globally-configured scroll distance more closely. Scrolling one "tick" with the mouse wheel should now move the view by a similar distance in Dolphin as it does in KWrite. In details view mode we made sure that scrolling moves by full item height (25.08.0 - link).
Gleb Kasachou added a setting to optionally elide long file names at the end instead of in the middle, so when the Dolphin window is too narrow to display “a very long file name.txt”, you can now switch between showing “a very…file name.txt” or “a very long file….txt”. Both of these behaviors have been respectfully criticized in the past, so now everyone can set it to their liking (25.08.0 - link).
Bojidar Marinov fixed a visual bug in the default icons view mode in a livestream, as sometimes the file name would have one row of text outside and below the actual file geometry (25.08.0 - link).
Akseli Lahtinen fixed a long-standing issue that could cause Dolphin to crash while interacting with Samba shares (Frameworks 6.16 - link).
Kai Uwe Broulik fixed another long-standing issue where a random "Examining" popup would appear when connecting to a busy Samba share (25.04.3 - link).
Sune Vuorela made the list of certificates used to sign a PDF update when switching the active backend (GnuPG or NSS) (25.08.0 - link). If Kleopatra is installed and the GPG backend is selected, Okular will now propose to view the certificate details in Kleopatra (25.08.0 - link).
Abdus Sami made the number of items in the recent history configurable (25.08.0 - link).
Pablo Ariño ported the Etesync resource away from directly depending on QtWidgets. This decreases the RAM consumption by around 10MiB for each running Etesync instance (25.08.0 - link). Carl then ported the resource away from KWallet to the more multiplatform alternative QtKeychain (25.08.0 - link).
Merkuro Manage your tasks, events and contacts with speed and ease
Oliver Beard fixed various bugs in Photos. Sharing now works again (25.08.0 - link) and the bookmark functionality is now consistently called "bookmark" in the UI (25.08.0 - link). He also ported the thumbnailbar to a standard toolbar (link).
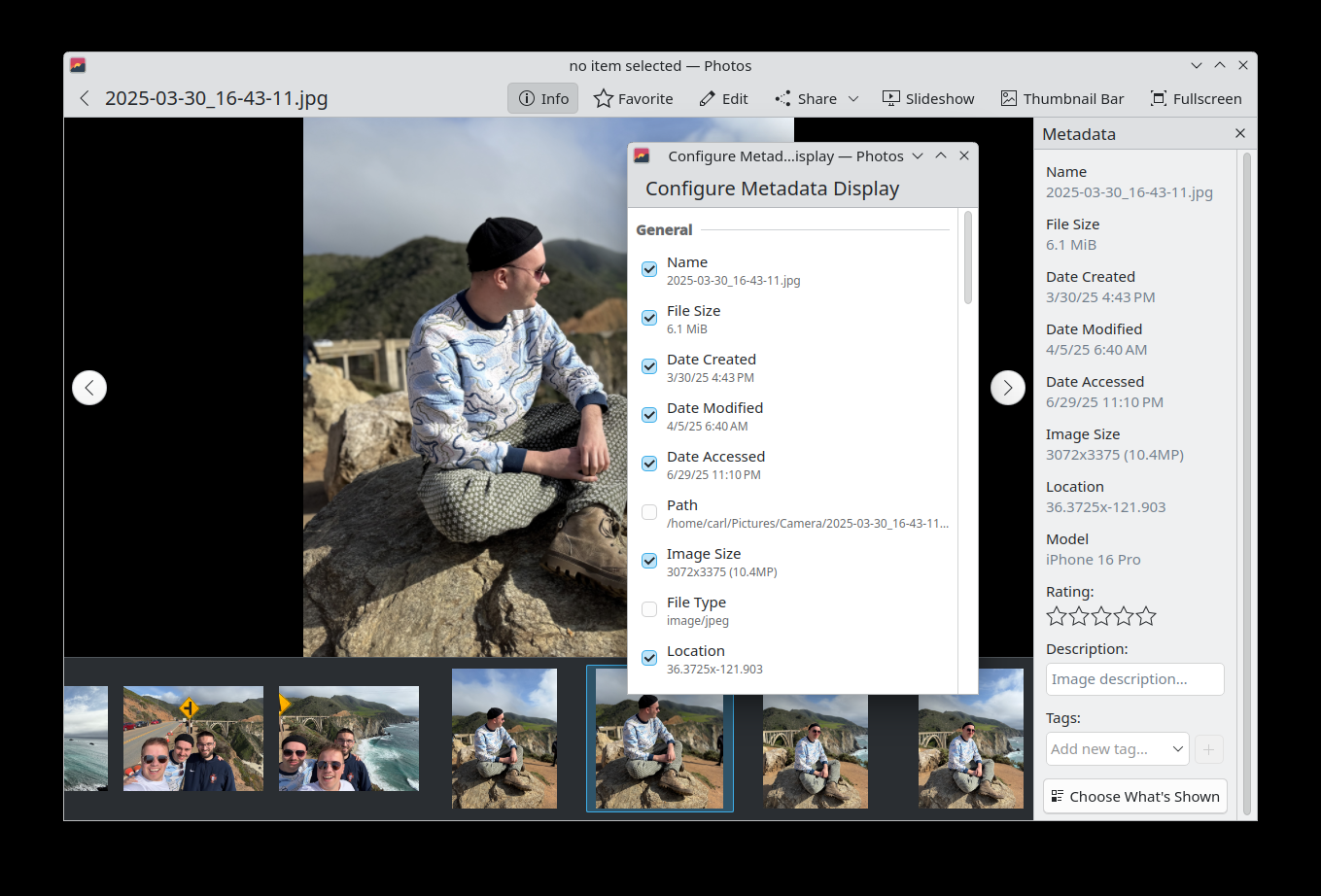
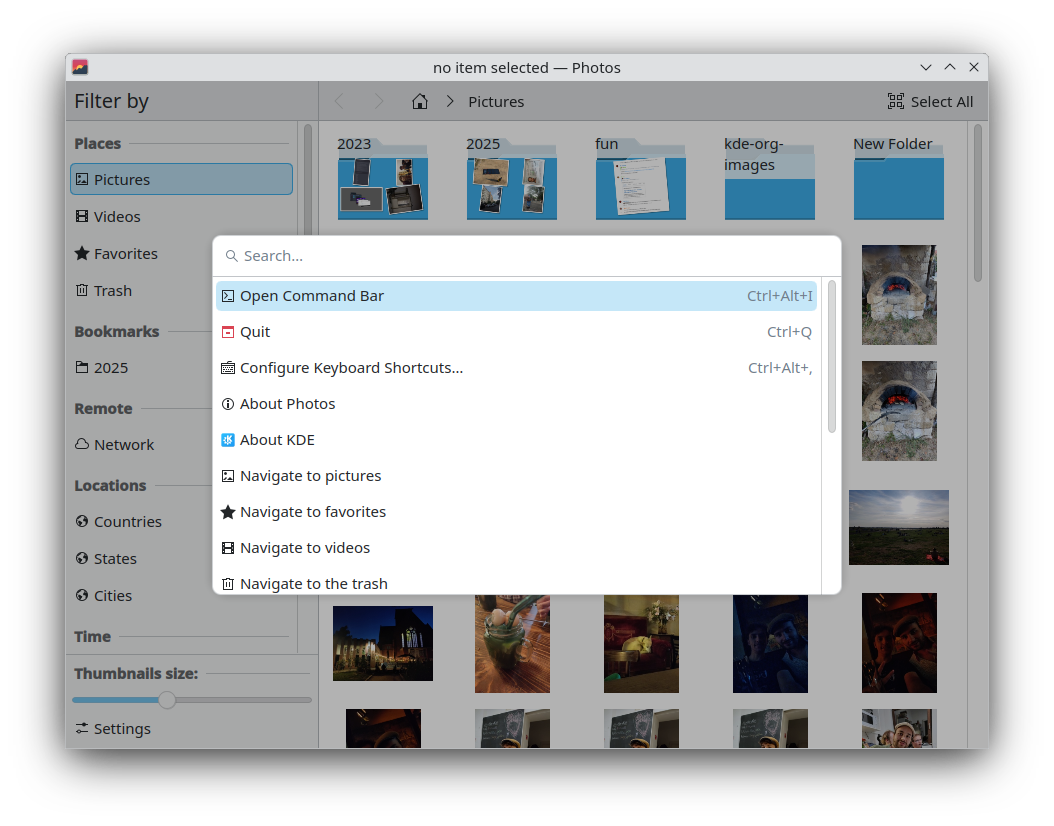
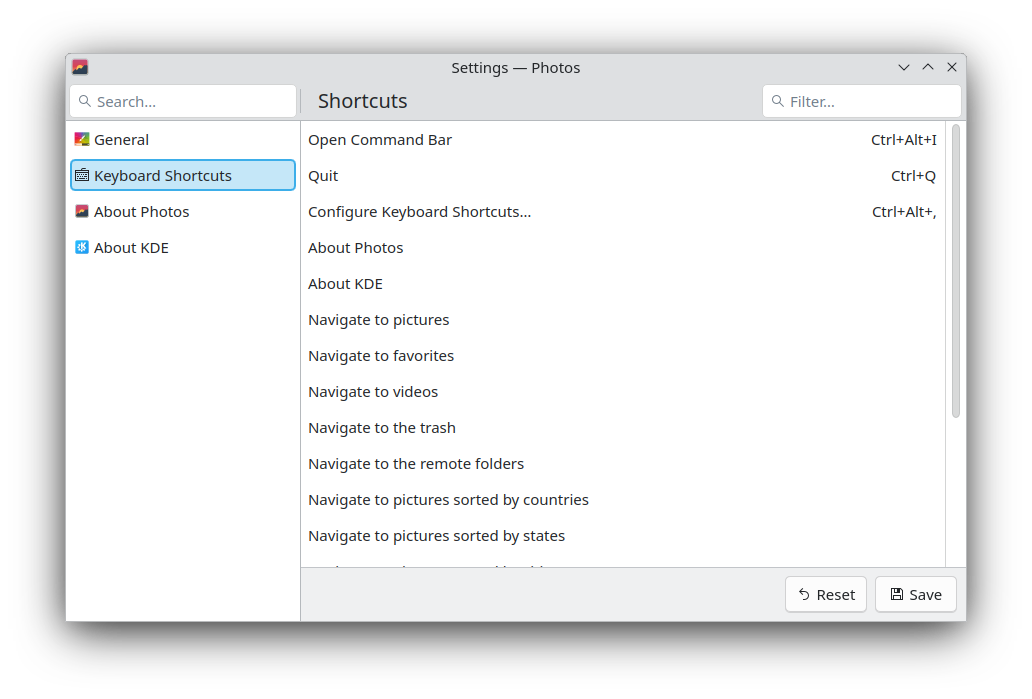
Carl Schwan made it possible to configure some shortcuts in Photos and added a command bar (25.08.0 - link). Additionally, he made it possible to configure which metadata details are available in the sidebar (25.08.0 - link).
Carl also optimized the main view a bit (25.08.0 - link 1, link 2 and link 3), unified the breakpoint at which desktop and mobile mode are switched (25.08.0 - link), fixed the video player which was not completely ported away from Qt5 (25.08.0 - link), and made a large number of small cleanups and code modernizations (link).
Jean-Baptiste Mardelle added an action to extend and collapse items in the effects and folders view. This allows navigating these views with the keyboard (25.08.0 - link).
Carl Schwan added support for Deutsches Jugendherbergswerk (DJH) email confirmations (25.04.03 - link).
Stephan Olbrich added support for Deutscher Alpenverein (DAV) membership cards (25.04.03 - link).
David Pilarčík added support for extracting multiple tickets from one PDF for Leo Express (25.04.03 - link) and improved the extraction of the luma extractor (25.04.03 - link).
Joshua Goins overhauled the server information page (25.08.0 - link). You can now view your server's extended description, terms of service and privacy policy (when applicable).
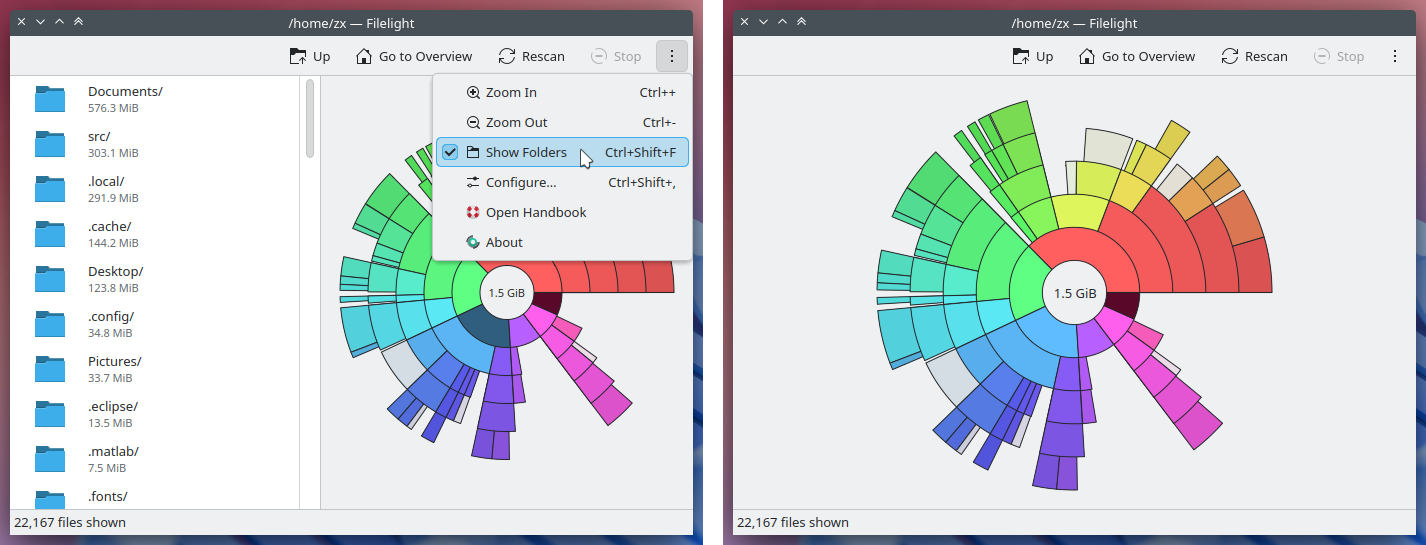
Efe Çiftci added a "Show Folders" action to Filelight that allows toggling the visibility of the folder list on the left-hand side of the window (25.08.0 - link).
For a complete overview of what's going on, visit KDE's Planet, where you can find all KDE news unfiltered directly from our contributors.
Get Involved
The KDE organization has become important in the world, and your time and
contributions have helped us get there. As we grow, we're going to need
your support for KDE to become sustainable.
You can help KDE by becoming an active community member and getting involved.
Each contributor makes a huge difference in KDE — you are not a number or a cog
in a machine! You don’t have to be a programmer either. There are many things
you can do: you can help hunt and confirm bugs, even maybe solve them;
contribute designs for wallpapers, web pages, icons and app interfaces;
translate messages and menu items into your own language; promote KDE in your
local community; and a ton more things.
You can also help us by donating. Any monetary
contribution, however small, will help us cover operational costs, salaries,
travel expenses for contributors and in general just keep KDE bringing Free
Software to the world.
To get your application mentioned here, please ping us in invent or in Matrix.
This week, the merge request for the EteSync resource has been reviewed and successfully merged! This marks a key milestone in the project: EteSync is the first resource to be fully refactored, with its UI logic cleanly separated into a standalone configuration plugin.
Based on feedback from my mentors, I made a few final revisions before the merge. One important addition was a .notifyrc file for the EteSync resource. This allows the headless EteSync resource to make use of KNotification for reporting errors or status updates, integrating with the user notification system in a way that doesn’t depend on a UI.
With the resource no longer depending on QtWidgets, and its configuration interface now dynamically loaded, this change contributes to our broader goal of making the Merkuro suite lighter and more adaptable for mobile environments.
After the merge, my mentor Carl checked the memory usage using System Monitor. The improvements were measurable: the EteSync resource now uses approximately 9.5 MiB of RAM, compared to the 22 MiB used prior to the refactor.
The Job Tracker and a D-Bus Debugging
With Etesync out of the way, I turned my full attention back to the PIM Migration Agent. The next logical step was to resolve the KUiServerJobTracker problem I identified last week. My initial plan was to replace it entirely with the progress-reporting tools built directly into Akonadi’s AgentBase. But, while inspecting the Akonadi code, I realized this approach wouldn’t be viable for my use case.
Although AgentBase does provide D-Bus signals for job progress and status updates, these are low-level and do not integrate directly with the system tray or display persistent visual feedback to the user. In contrast, KUiServerV2JobTracker automatically presents progress as desktop notifications or tray-based UI elements.
Still, I implemented the changes, compiled the code, and launched akonadiconsole to test. The good news: the refactored agent started and the configuration plugin loaded. The bad news: they weren’t talking to each other. The D-Bus communication I had set up last week was failing.
This sent me down a debugging rabbit hole. My first hypothesis was that the agent needed its own .service file to properly register on the D-Bus session bus. I spent a good chunk of time creating and tweaking one, but the D-Bus connection simply refused to work as intended. The plugin and the agent remained strangers.
After much investigation I discovered the root cause, and it was a typical environment problem.
akonadiconsole was using the system D-Bus, while my development build of the agent was trying to register on the user session D-Bus managed by my Plasma desktop.
They were on two completely different communication networks! This immediately explained why my custom dbus interface had no effect—akonadiconsole was never even looking for it in the user session. To solve this I ran:
kde-builder - -run akonadictl restart
After this I ran the akonadiconsole once again and this time the D-Bus connection worked as intended.
What’s Next?
For next week, the priorities are:
Re-evaluate the job tracking solution for the Migration Agent, now with a proper understanding of the D-Bus context.
Push forward with removing the final QtWidgets dependencies.
Finalize the plugin-agent communication pathway with reliable, real-time interaction.
The refactor of EteSync and the progress made with D-Bus integration in the Migration Agent continue to move the project toward a more modular and future-proof codebase.
Dear fans of music & open source music players, in preparation of the upcoming Amarok 3.3 release, a second beta release (3.2.82) has been prepared.
This time, the most important change is the new GStreamer-based audio backend. This enables a number of features that weren't available on Qt6 Phonon
backends, and likely also provides a more reliable audio experience in general.
In addition to audio system work, e.g. more safeguards have been set up around collection scanning code to prevent some potential database issues.
More details on changes are listed in the ChangeLog.
These come in addition to the previous beta 1 changes (Qt6 only, database update).
Please note that due to the database update in beta 1, downgrading from 3.3 betas is not directly possible, and returning to pre-3.3 versions
requires the database (at ~/.local/share/amarok/mysqle/) to be manually backed up beforehand.
The Amarok 3.3 beta 2 source tarball is available on
download.kde.org
and it has been signed with Tuomas Nurmi's GPG key.
In addition to the source code, it is likely that some distributions will provide beta packages.
The various nightly git builds provided by various splendid packagers should also provide a way of using the beta changes
and participating in the testing.
Plasma's upcoming first-run experience is coming along nicely.
After a bunch of research and discussions we settled on continuing / fixing up
the KISS project (KDE Initial System
Setup) for the new First Run Experience (FRE) / Out-Of-Box Experience (OOBE). It
was in a sort of half finished state.
Since then has been a bunch of work on it such as:
Getting it to compile and run
Whole bunch of fixes, cleanup, and polish to the UI, UX, and code/developer
experience
Implemented the ability to actually create the new user (you could enter a
name and password, but it was all basically placeholder GUI previously)
Added language selection front/back ends
Added basic build / run instructions to the README
Added ECM logging
Cleaned up the debug output which made changes more difficult
Added basic CI (thanks Nico!)
Added keyboard layout selection front/back ends
That last one was more difficult than expected.. turns out keyboard layouts can
be quite complex!
First came some refactoring of the keyboard layouts KCM from plasma-desktop so
we could reuse some of the existing, complex functionality. Then adapting a
UI/UX appropriate for the FRE. Investigating things like keyboard models,
detecting defaults, mapping language to keyboard layout, etc..
Then taking the results of the user choice and figuring out how to apply that
both to the system as a default (systemd-localed dbus call) as well as to the
running Plasma session (setting the value manually in the kxkbrc keyboard
settings file).
As is often the case with software development, that succinct summary belies
the massive amount of work it took to get there! 😅 💪
With that work completed, we have most of what is needed for a minimum viable
product!
Next up:
Granting authentication without a user prompt
Plan: special user with sysusers.d and a polkit rule
Running automatically on first boot & in live sessions
Plan: systemd unit seems promising, but more research is needed
Improve documentation
Especially related to building & running without kde-builder
Think about the name
I am not thrilled with the KISS acronym personally 🤷♀️
There is also obviously a lot of improvements and polish that can be made, but
for now here is a preview of the FRE:
These past few week’s my focus was on exploring input device detection and event handling mechanisms in Linux, with a particular emphasis on game controllers and their potential integration into KWin.
I also spent time reading through KWin’s input-related source code to understand how it currently manages devices, and began reviewing documentation for various Linux input subsystems—including evdev, HID, and /dev/input/jsX in order to evaluate which layer would provide the most reliable and straight forward support for integrating controller recognition.
The time was mostly spent learning how to use different libraries, tools and creating virtual controller prototype.
Tools, Libraries, and Concepts Used
libevdev
libevdev is a library for handling evdev devices.
It provides a higher-level interface over /dev/input/event* and abstracts much of the complexity of input event parsing.
evdev is the generic input event interface. This is the preferred interface for userspace to consume user input, and all clients are encouraged to use it.
-The kernel development community.
libevdev can be used to:
Detect physical game controllers.
Read input events (e.g., joystick, buttons).
Create virtual input device and write/forward events to it from physical game controller.
Useful functions:
libevdev_new(), libevdev_set_fd(int fd, struct libevdev **dev): for opening physical devices.
libevdev_next_event(struct libevdev *dev, unsigned int flags, struct input_event *ev): for polling events.
libevdev_get_id_*(const struct libevdev *dev): to query device meta data.
uinput (User Input Subsystem)
I used the Linux uinput subsystem to create a virtual input device that mirrors a physical controller input.
uinput is what allows us to make a virtual controller out of any evdev device by:
Opening a file discriptor for the input device that will be emulate (i.e. have it input event forwarded).
Forwarding the inputs from a evdev interface device to /dev/uinput (or /dev/input/uinput).
uinput then creates a new node to expose the virtual device as a evdev interface device in /dev/input/event*
From here the idea is that KWin or any other system component can treat the virtual controller as if it were an ordinary HID device.
uinput is a kernel module that makes it possible to emulate input devices from userspace.
By writing to /dev/uinput (or /dev/input/uinput) device, a process can create a virtual input device with specific capabilities.
Once this virtual device is created, the process can send events through it, that will be delivered to userspace and in-kernel consumers.
-The kernel development community.
Useful functions:
libevdev_uinput_create_from_device(const struct libevdev *dev, int uinput_fd, struct libevdev_uinput **uinput_dev): For creating a uinput device based on the given libevdev device.
libevdev_uinput_get_devnode (struct libevdev_uinput *uinput_dev): Return the device node representing this uinput device.
libevdev_uinput_write_event (const struct libevdev_uinput *uinput_dev, unsigned int type, unsigned int code, int value):
Post an event through the uinput device.
Tools used:
libevdev-uinput.h for management of uinput devices via libevdev.
/dev/uinput opened with correct permissions.
Ensuring the current user is in the input group.
Verifying that the uinput kernel module is loaded (using modprobe uinput). Some distros (Ubuntu/Kubuntu) have it built in, not loaded as module, thus modprobe uinput command won't log anything.
Opening /dev/uinput with O_WRONLY | O_NONBLOCK flags using open(), and ensuring no EPERM or EACCES errors were returned.
Optional: Run program as sudo user.
force feedback detection/support
Using ioctl(fd, EVIOCGBIT(EV_FF, ...)) and tools like fftest, I examined:
How to query a device’s force feedback (FF) capabilities to figure out which effects are supported (e.g., rumble, sine wave).
How to upload ff effects to physical game controller and test rumble motors.
This was key to understanding haptic capability support on physical devices.
To enable force feedback, you have to:
have your kernel configured with evdev and a driver that supports your device.
make sure evdev module is loaded and /dev/input/event* device files are created.
Testing & Validation
Used evtest and fftestto test evdev devices and understand their capabilities -
sudo evtest /dev/input/eventX.
Used those same tools to test virtual devices creating using uinput - sudo fftest dev/input/eventX. uinput creates a node device in dev/input/eventX for the virtual input.
Prototype logs validate that a virtual device can be created and events can properly be written to a that virtual device using libevdev.
Takeaways
Using libevdev and libevdev-uinput we can access physical controllers, create virtual controller and read/write low-level input events.
Understanding of the permission requirements to open /dev/input/* and /dev/uinput (use udev rules or run as root).
Tools to test:
evtest and fftest (from input-utils)
udevadm info --name=/dev/input/eventX --attribute-walk
Shows the device hierarchy - how the device is connected to PC and any parent device it connects to.
Built a minimal proof-of-concept C++ program that routes an evdev devices input 1:1 to a virtual controller (via uinput).
Not all controllers support all force feedback types; some failed with EINVAL during upload.
libevdev does not handle FF upload directly — this remains kernel-level and typically involves ioctl().
You might have noticed that Plasma keyboard shortcuts have been
changing recently with the aim to have everything KWin/Plasma be
Meta+Something.
Now, I tend to redefine most of the default shortcuts, so this didn’t
affect my workspace directly, but I liked the idea to have different
modifiers used depending on the category of /thing/ for which I’m
creating a shortcut.
An additional aim I had is to have a common shortcut ‘body’ for
equivalent actions in different categories, in order to more easily
build muscle memory with my new shortcuts.
Categories that I have are:
system (Plasma and such)
terminal application (Konsole, Kitty)
terminal multiplexer (TMux)
specific application (Firefox, Vim, …)
And these are the modifiers I’m trying out:
system: Meta+Anything and
Alt+Special keys
terminal application: Ctrl+Shift+Anything
terminal multiplexer: nothing special yet, just the
Ctrl+d as the leader
specific application:
working with tabs: Ctrl+Anything
other shortcuts: Alt+Normal keys
So, for example, the ; and ' as the shared
shortcut /bodies/ mean the following in different categories:
Meta+; and Meta+' – switch to next and
previous window (I’m using Krohnkite for tiling, so this is not like
Alt+Tab, but moving through the visible tiled windows);
Ctrl+Shift+; and Ctrl+Shift+' – would mean
switch to next and previous panes in the terminal application (I’m not
using this yet, as I don’t tend to use split views in terminal except in
TMux);
Ctrl+d ; and Ctrl+d ' – move to next and
previous panes in TMux;
Alt+; and Alt+' – move to next and
previous panes in an application (currently only in Vim and
Neovim).
So far, the approach seems to work Ok. I’ve quickly got accustomed to
the new window/pane navigation shortcuts.
The main problem are the programs that don’t allow changing shortcuts
(Firefox for example) or don’t allow creating shortcuts with some key
combinations (using Ctrl+; in Vim or Neovim does not work,
while it works with Alt).
Because of those limitations, the modifiers are not as clear cut as
they ideally would be. Ideally, each category would have its own single
modifier, instead of, for example, having a mix of Alt and
Ctrl in the /specific application/ category, and using a
modifier combination like Ctrl+Shift for the /terminal
application/.
I’ve also redefined all my Plasma and KWin shortcuts to be
location-on-keyboard-based, but more on that later.



 @rossr:matrix.org
@rossr:matrix.org

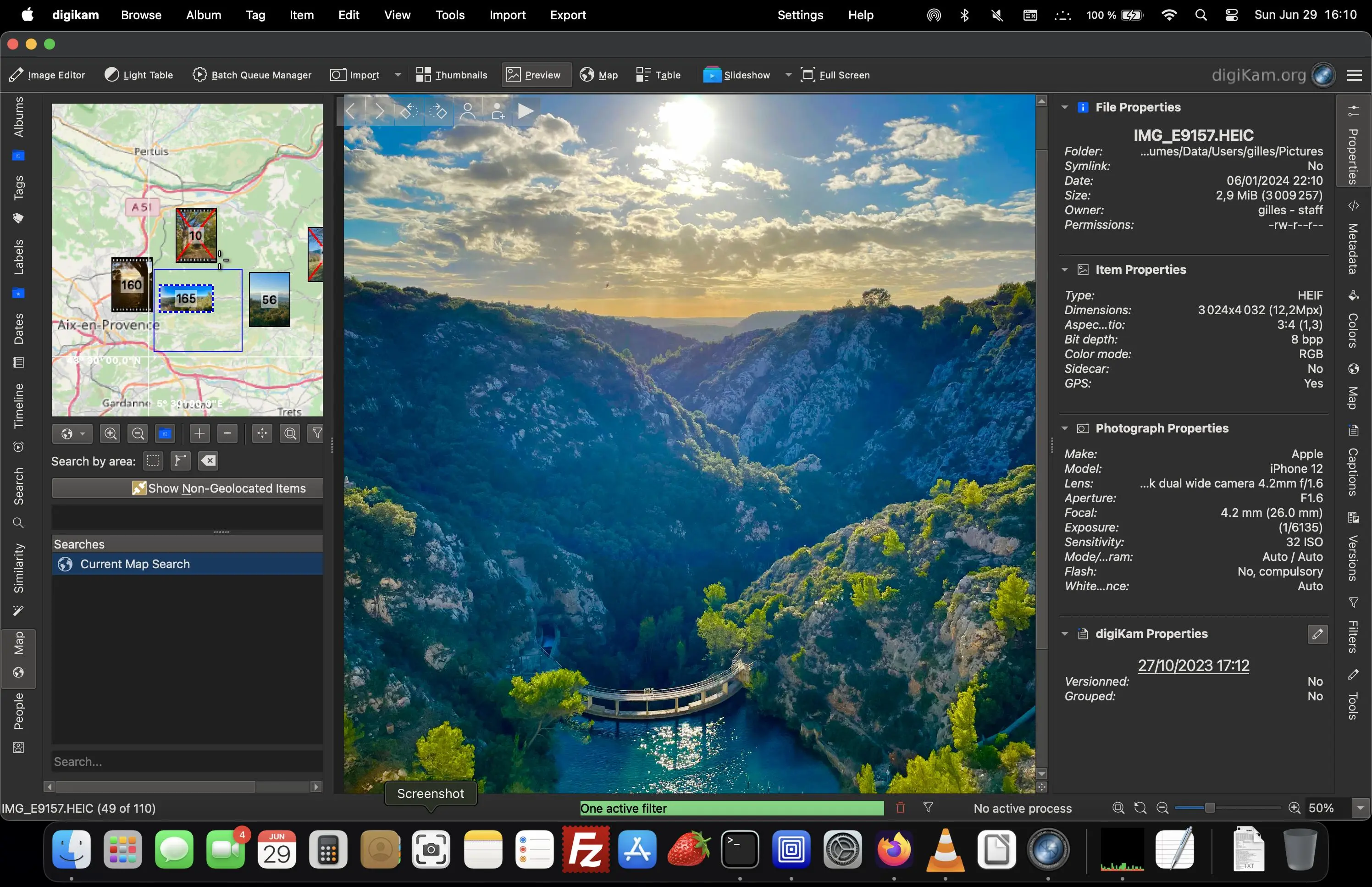 Dear digiKam fans and users,
Dear digiKam fans and users,
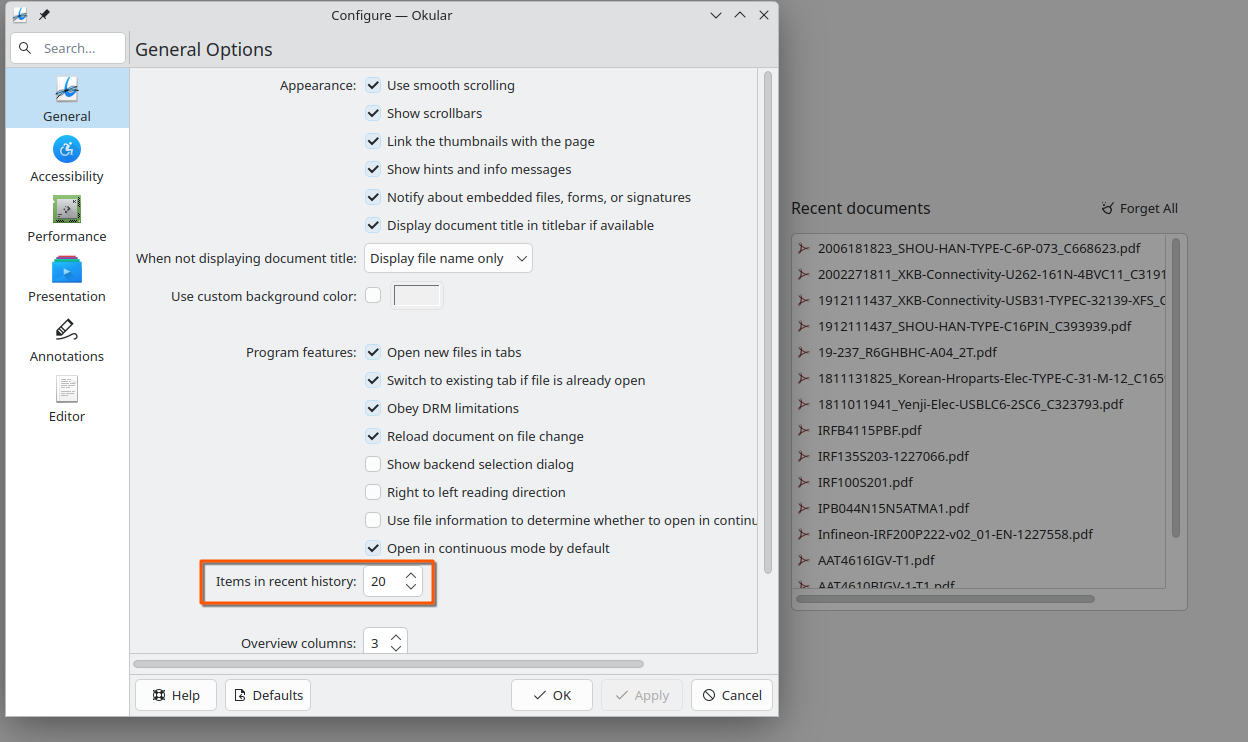


 TSDgeos
TSDgeos


