Many people are, understandably, confused about brightness levels in content creation and consumption - both for SDR and for HDR content. Even people that do content creation as their job sometimes get it really wrong.
Before jumping into the actual topic, I want to emphasize that most people that have gaps in their knowledge about HDR and SDR are not to blame for it. The standards that define colorspaces are usually confusingly written, many don’t paint the full picture, finding the one you actually need can be difficult, some you need to pay for to even read, and generally there is not a lot of well organized and free information about this out there.
When you have basically no information, you just go with what you do know - you see how Microsoft Windows does HDR for example, maybe you take a look at a draft for the sRGB specification or simply the Wikipedia pages, and do the best with what you have. The result is often less than ideal.
Having worked on this stuff for a while now, and having read lots about it from people that actually know what they’re doing, I think I know the topic well enough to clear up some misconceptions, but do keep in mind that my knowledge is limited too, and I may still make mistakes. If you’re sure I got anything wrong, tell me about it!
If you want an entry point for way more information than this blog post provides, check out color-and-hdr.
How brightness works with sRGB
sRGB is the colorspace most content uses today. Despite that, very annoyingly, its specification is not openly available… but there’s a draft version that you can download freely here, which is good enough for this topic.
The (draft) specification defines two things that are important when it comes to brightness:
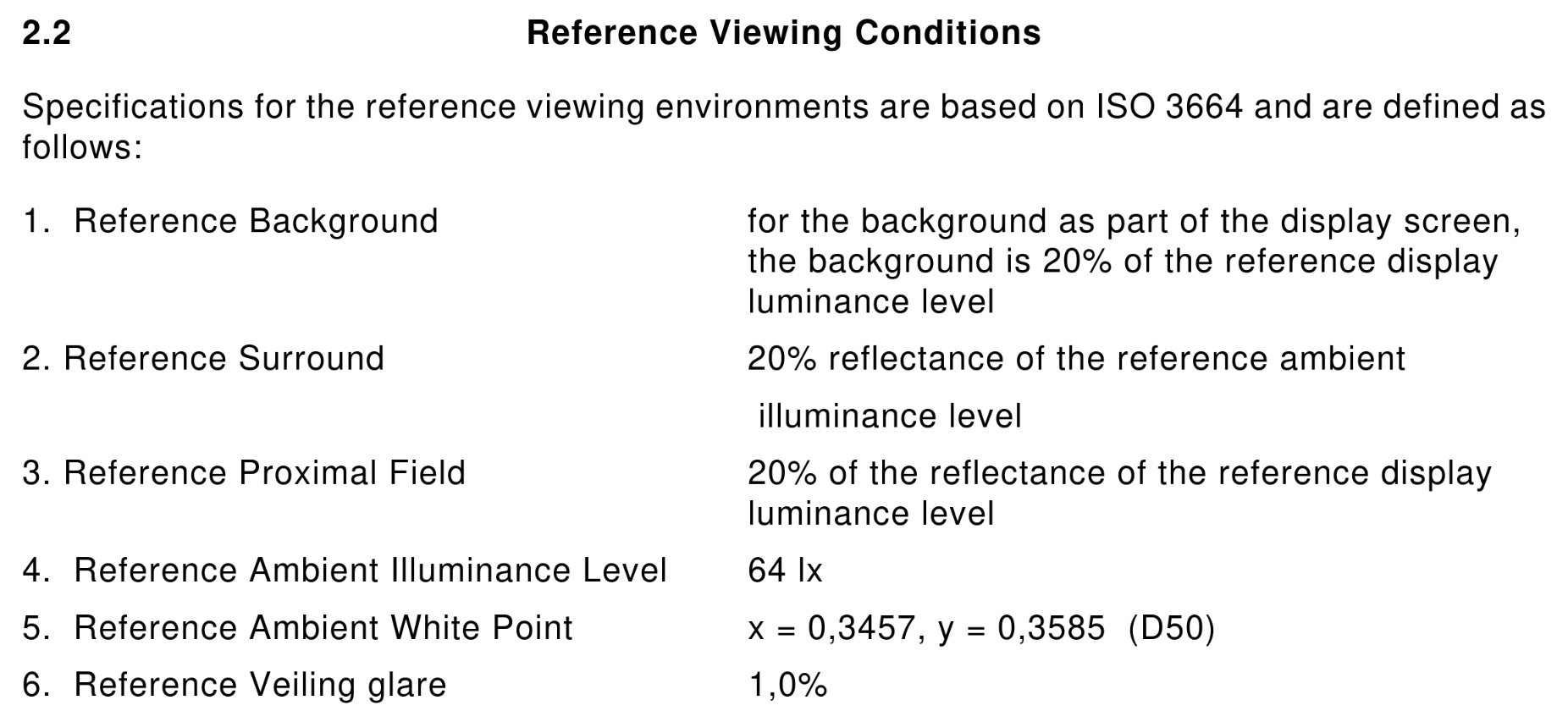
- a set of reference display conditions
- a set of reference viewing conditions (I’ll call that “viewing environment” from here on)
The reference display conditions are seemingly quite straight forward. The display luminance is 80cd/m², we have a whitepoint of D65, and a transfer function. Transfer functions describe how to calculate the output luminance from the encoded values of an image, and with sRGB that’s
where Y is the relative luminance on the display, and X is the relative luminance on the input.
The viewing environment has a few more parameters, but it’s conceptually not difficult to understand: It describes how bright your environment is, what color temperature the lights in your room have, and how much your display reflects the environment at you.
How to create sRGB content “correctly”?
The assumption that many people take from the specification is that you should calibrate your display to 80cd/m². On its own, that information is completely wrong!
It’s obvious when you think about how end users actually view content: They set the brightness level of the display to what they’re comfortable with in the current environment. You make the display really bright when you’re outside, less bright when in a normally lit room, and even darker than that when the lights are off.
The part that’s missing with just calibrating the display to some luminance level is that you must take the viewing environment into account. Either you set up the sRGB reference viewing environment (with measurements!)… or you just don’t. When you create content, in most cases you should do exactly the same thing as the person that will consume the content does: Just set the brightness to what’s comfortable in the environment you’re in. It still helps to keep your viewing environment mostly fixed of course, lots of brightness changes mean you’re constantly readjusting and that’s not good.
There’s another big thing to take into account for sRGB, which is its confusing transfer function.
The sRGB transfer function
The sRGB specification doesn’t just define a transfer function for the display, but it also defines a second transfer function. This sRGB piece-wise transfer function is
if X < 0.04045: Y = X / 12.92
else: Y = ((X + 0.055) / 1.055)^2.4
and it’s slightly different from gamma 2.2 in that it has that linear bit for the very dark area.
The purpose of this transfer function is to optimize encoding of dark parts of the image - with 8 bits per color, gamma 2.2 becomes really small in the lowest few values. 1/255 for example results in roughly 0.0000051 with gamma 2.2, and 0.0003035 with the sRGB piece-wise transfer function.
This difference might sound insignificant, but it is noticeable. The most well known place of where the wrong transfer function is used is Microsoft Windows: When you enable HDR in Windows, it uses the piece-wise transfer function for sRGB content, instead of the gamma 2.2 transfer function that which your display uses in SDR mode. The result is that dark areas of SDR games and videos are brighter than they should be, and look “washed out”.
So when should you use the sRGB piece-wise transfer function? So far, I don’t know of any case where you should, outside of working around that Windows problem in your application… I’m also only concerned with displaying images though, and not editing or creating them, so take that with a grain of salt.
How brightness works with HDR
Most HDR content uses the SMPTE ST 2084 transfer function. The specification for this is freely available here.
SMPTE ST 2084 is a bit different from the sRGB spec, in that it only defines a transfer function but no complete colorspace or viewing environment. That transfer function is the Perceptual Quantizer (PQ): It tries to compress luminance levels in a way that matches how sensitive human eyes are in specific luminance ranges, and it’s defined in absolute luminance - a PQ value of 0.0 means <= 0.005cd/m², and 1.0 maps to 10000 cd/m².
The missing parts are defined by different specifications, rec.2100 and BT.2408. More specifically, rec.2100 uses the BT.2020 primaries with the PQ transfer function (or the HLG transfer function, but we’ll ignore that here) and a recommended viewing environment for such HDR content:
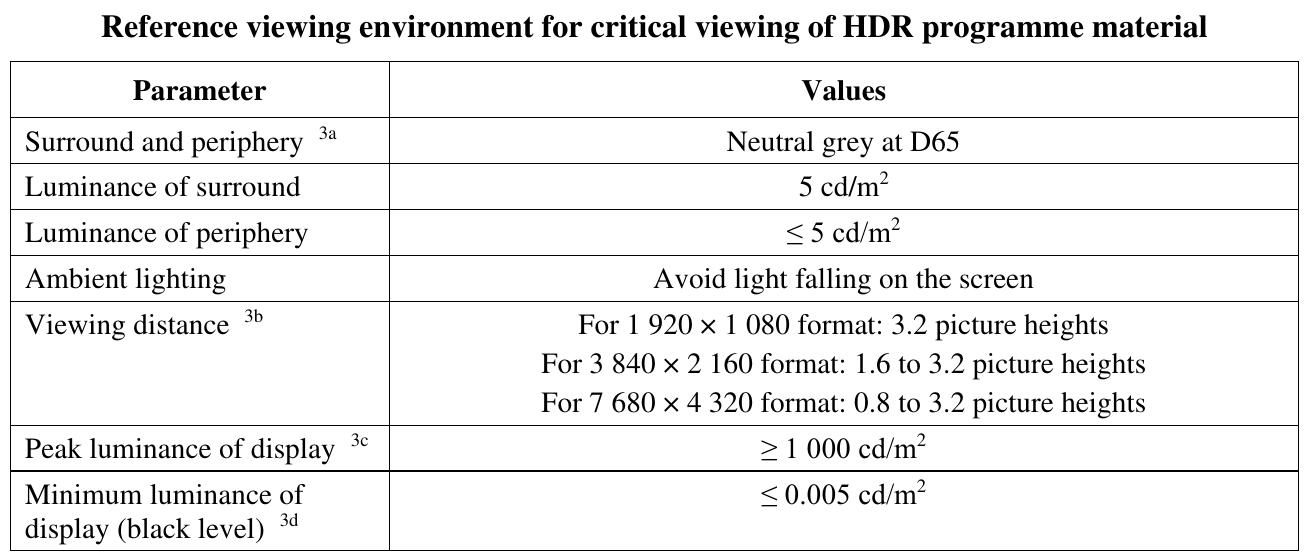
BT.2408 expands on that with an HDR reference white and graphics white, at 203cd/m². This is mostly meant for the context of broadcasts, referring with “graphics” to logos or subtitles in the video stream.
Despite the transfer function being “absolute”, just like with sRGB, the luminance numbers don’t mean anything in isolation. When displaying HDR content, just like with SDR, we need to take the viewing environment into account, and adjust luminance levels accordingly.
How is this handled in Wayland?
Every transfer function in the color management protocol has reference display conditions and a viewing environment attached to it, defined by a few parameters. Most relevant for this topic are
- a reference luminance, also known as HDR reference white, graphics white or SDR white
- minimum and maximum mastering luminances, basically how dark and bright the display the content was made for can go
When content is displayed on the screen, the compositor translates between the viewing environment of the content, and the viewing environment of the user. While we don’t usually have full knowledge of what exactly that viewing environment is like, the brightness slider in KDE Plasma provides a very good approximation by configuring the reference luminance to be used for content on the display. The calculation for this brightness adjustment is rather simple, in linear space you just do
output = input * output_reference / input_reference
You can configure the maximum reference luminance (brightness slider at 100%) with the “Maximum SDR Brightness” in the display settings of Plasma 6.3. The minimum and maximum luminance your display can achieve can only be configured with the kscreen-doctor command line tool right now, but an easy to use calibration utility for this is nearly finished (and the default values are usually fine too).
In general, this system is working really well… with one rather big exception.
HDR in Windows games
As mentioned before, Windows in HDR mode does sRGB wrong, but the story with HDR content is kind of worse.
When you use Windows 11 on a desktop monitor and enable HDR, you get an “SDR content brightness” slider in the settings - treating HDR content as something completely separate that’s somehow independent of the viewing environment, and that you cannot adjust the brightness of. With laptop displays however, you get a normal brightness slider, which applies to both SDR and HDR content.
The vast majority of Windows games expect the desktop monitor case: Static, never changing luminance levels, which are displayed on the screen without any adjustments whatsoever. Windows also didn’t have a built-in HDR calibration tool until Windows 11, so nearly every Windows game ships with its own HDR calibration settings and completely ignores system settings. This doesn’t just cause issues for Windows 11 laptops of course, but also for playing these same games with HDR on Linux.
Until Plasma 6.2, we worked around that, also mostly not doing brightness adjustments, and the result was that those HDR calibration settings in games worked basically like on Windows. However, these workarounds broke Linux native applications that want to mix HDR and SDR in their own windows, made tone mapping worse, and blocked features like HDR on “SDR” laptop displays, so in Plasma 6.3 we had to drop them.
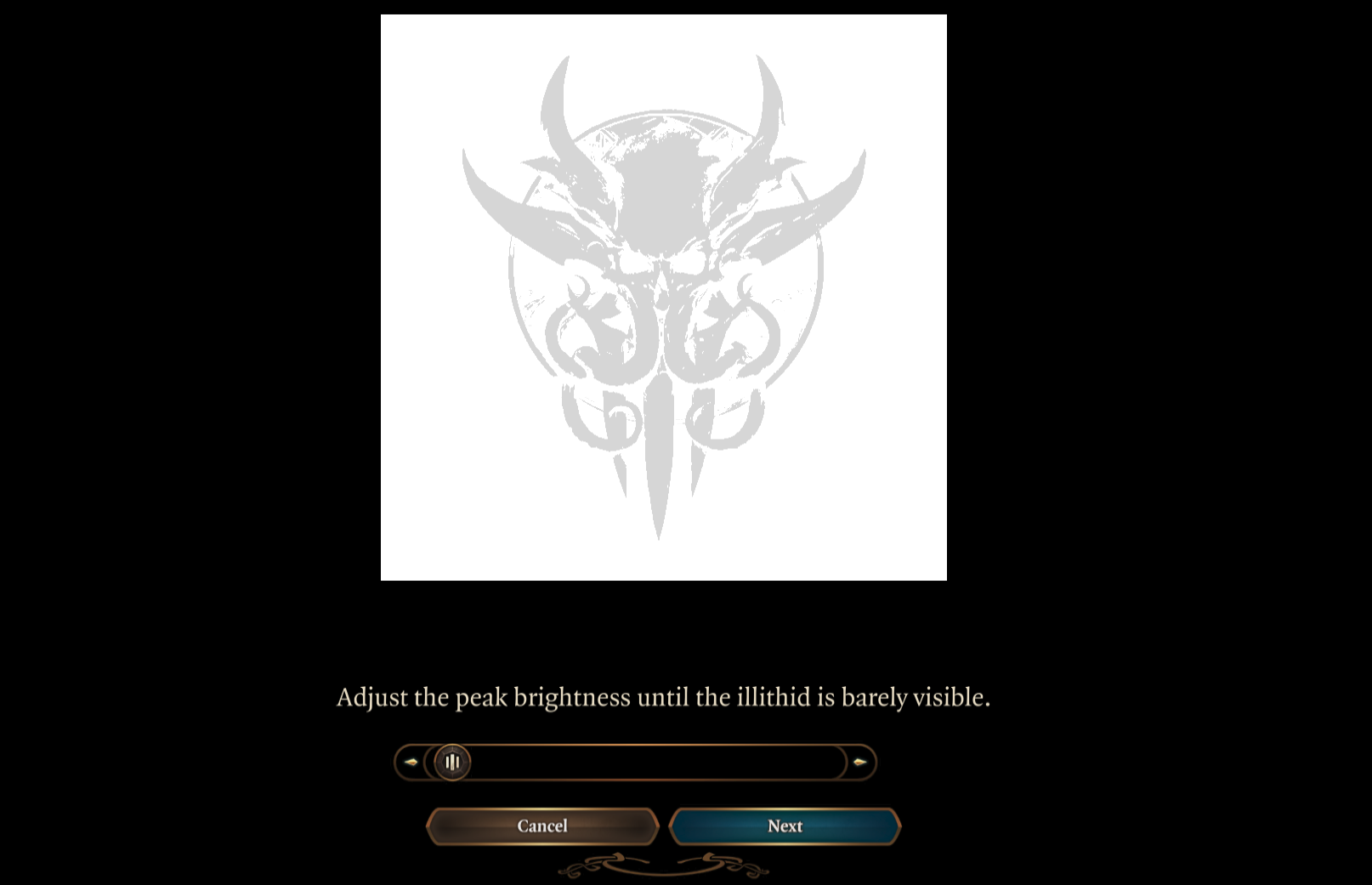
This doesn’t mean you can’t play Windows games with HDR in 6.3 anymore, you just have to adjust their configuration to match the changed brightness levels. In most cases, this means you set the HDR paper white in games to 203cd/m², and then set the maximum luminance with the game’s configuration screen, like this one from Baldur’s Gate 3:
How to implement good HDR
After ranting about how Windows games do it wrong, I should end this blog post by also explaining how to do it right. I will skip most of the implementation details, but on a high level if you’re implementing HDR in a Wayland native application or toolkit, you should
- use the Wayland color management protocol
- get the capabilities of the compositor and/or graphics driver, specifically the transfer functions they support
- get the preferred image description from the compositor, and the luminances you’re supposed to target from that. When using these luminance values, keep in mind that reference luminance adjustment the compositor will do!
- every time the preferred image description changes, get the new one and adjust your application to it
- now render for these parameters, and set the image description you actually ended up targeting on the surface, either through Vulkan or with the Wayland protocol (not both at the same time!)
- SDR things, like user interfaces in games, should use the reference luminance too
- if your application has some need to differentiate between “SDR” and “HDR” displays (to change the buffer format for example), you can do so by checking if the maximum mastering luminance is greater than the reference luminance
- now you can, and really should drop all HDR settings from your application. If HDR has a performance penalty in your application, a toggle to limit the app to SDR could still be useful, but everything else should be completely automatic and the user should not be bothered with calibration screens or similar annoyances

 @nidhish07:matrix.org
@nidhish07:matrix.org




 KNRO
KNRO








