Hi all! My name is Ross Rosales. I am a self-taught Software Engineer and former Registered Nurse with a background in the Emergency Deparment. Through the great community of KDE and Open Source I gained so much valuable experience that I apply in my everyday career and life. As I continue learning everyday, I want to share what I'll be working on over the next 12 weeks.
About Krita
Krita is an amazing open source and free painting program with countless growing features. Although I may not paint or draw very well myself, I've always admired how artists are able to create anything they can put their mind to with the tools at their disposal. My goal is to contribute to Krita and support all artists by helping their ideas become reality.
Proposal
To make artists' workflow easier, this GSoC I plan to create a floating toolbar that will contain common selection actions artists frequently switch between. The idea is to improve accessibility to tools that may not be intuitive to new or experienced users. Link to my proposal
Plans
In addition to sharing my progress on the Selection Action Bar for GSoC, I also plan to write about how new contributors can join the KDE community and reduce the barrier to entry for Krita. I’ll do this through personal walkthroughs covering environment setup, writing code for the first time, engaging with the community, and providing quick links to helpful resources—all in one place.
Special Thanks
Thank you to the KDE and Krita communities for giving me the opportunity to join such an amazing group of individuals. Special thanks to Dmitry, Emmet, Halla, Tiar, Wolthera, and everyone I interact with in Krita Chat!
Contact
To anyone reading this, please feel free to reach out to me. I’m always open to suggestions and thoughts on how to improve as a developer and as a person. Email: ross.erosales@gmail.com Matrix: @rossr:matrix.org
I’ve written a small Neovim plugin which might be useful to people
who often work on several projects in parallel.
It activates a specific theme based on the project you are working on
(the current directory you start Neovim from).
It allows you to define which themes should be used for which
projects. The configuration is simple and allows specifying patterns for
matching project names (not full regex, but what Lua supports).
My configuration looks something like this (this is in Fennel, for
the Lua version, check out the readme):
Since that time you can install it easily from here and the store will allow you to keep our application updated.
Kate is not the only KDE application there, other stuff uploaded under the KDE e.V. umbrella can be found here, this includes KDE Connect and Okular.
We have now better documentation and tooling for store submissions, the last update of Kate to 25.04 was, beside the local testing of the build if it is not broken in normal use, the press of one button.
Compared to my old guide from my first submission, that is really awesome, thanks a lot to all people that worked on that!
What if I don't like the Microsoft Store?
Naturally you don’t have to use the store (which implies some account you might not want and telemetry that you might want even less).
Alternate downloads are on our normal download page.
Or, if you want to be even more in control, and perhaps even willing to contribute, build it from source yourself, Craft makes that easy.
The Microsoft Store submissions are just a way to reach a larger audience.
Some people might even not be able to install stuff from other sources, depending how locked down their Windows installation is.
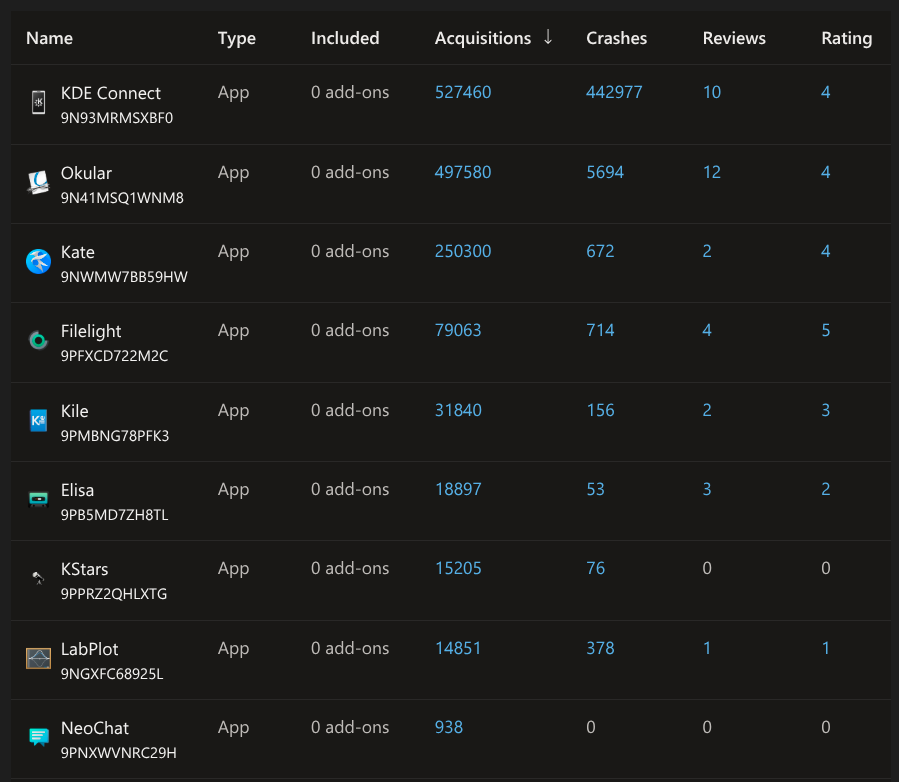
Current Statistics
Below the current statistics of the published applications sorted by acquisitions, that means more or less means individual user installs.
Not that bad, over half a million installs for KDE Connect, close to half a million for Okular and a quarter million for Kate.
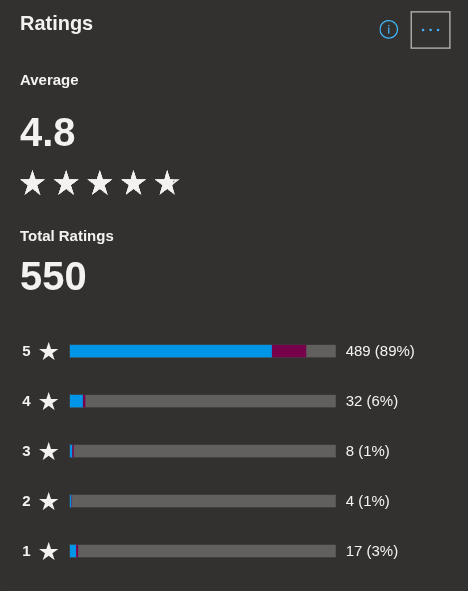
Current Ratings
The internal statistics of the store allow to see the ratings over the whole publishing time.
They look good, too.
KDE Connect Ratings
Okular Ratings
Kate Ratings
The Future?
We will need to update the versions in the store, Kate is now on 25.04, more to follow hopefully.
We need help with fixing Windows only bugs, too.
Just a random one for Kate can be found here.
Comments?
A matching thread for this can be found here on KDE Social or r/KDE.
A few years ago, I was among those who found Wayland too painful to use every day. Over time, I gave Wayland a try now and then. It finally got usable enough for me to switch to as my default a couple of years ago.
Recently, during the soft freeze before the Plasma 6.4 Beta was released, I used mainly X11 on both my laptops - for science! And by science, I mean regression testing. I was curious what the experience was like compared to what I've become accustomed to with Wayland.
In short, Wayland supports multiple displays and color so much better. It was painful using X11 again.
My setup for daily work
I was using two laptops and two external monitors. Both were running Plasma built from git-master.
Main: Dell XPS laptop, plugged into a dock. This is connected to 2 ultrawide monitors - one via Displayport, the other via HDMI.
Secondary: Lenovo Flex laptop, usually just using its built-in screen. Sometimes I swap the right hand monitor over to it, for testing display shenanigans.
Initial impression - so limited
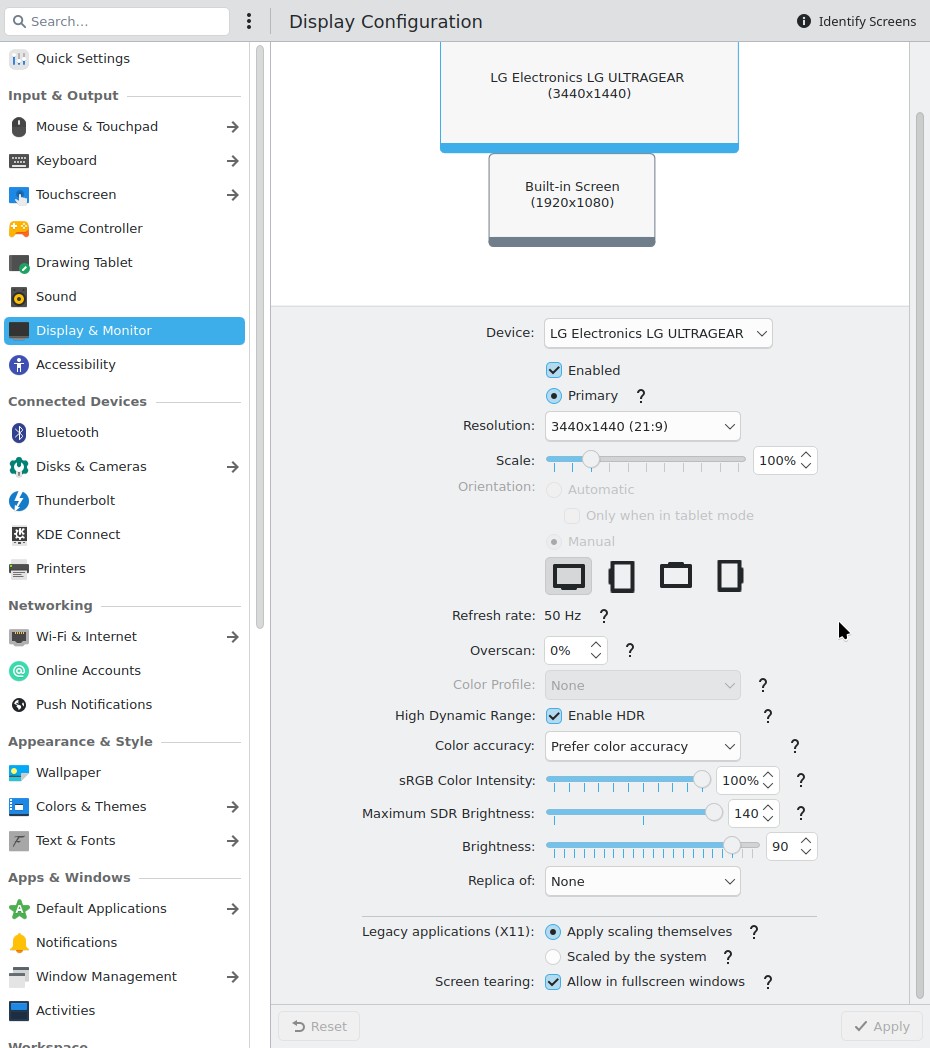
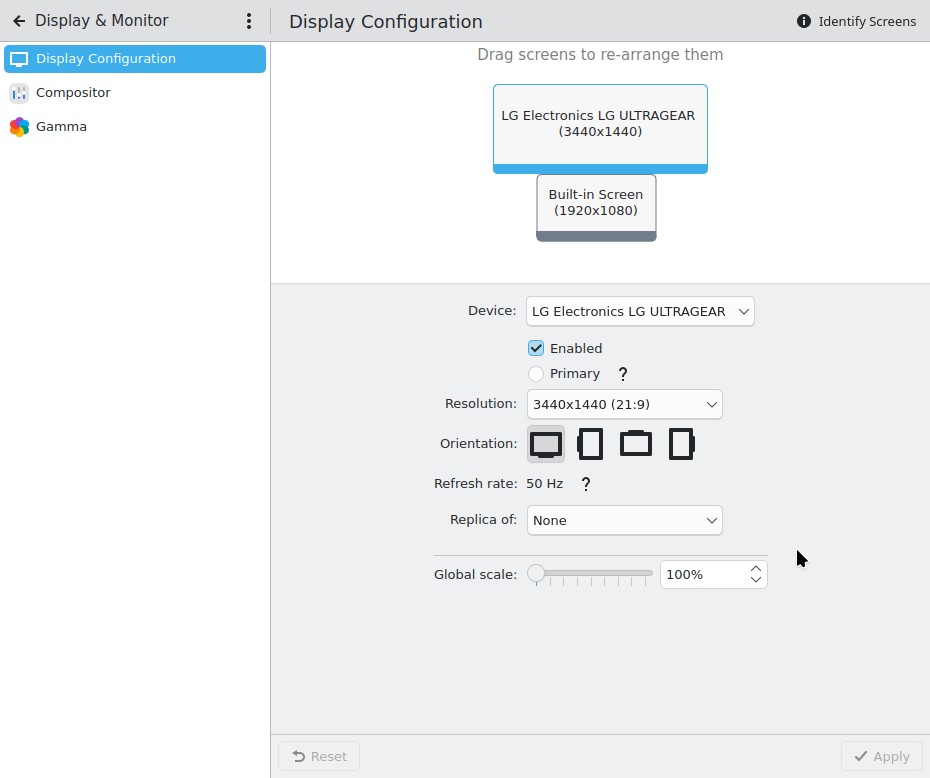
I fired up the XPS, did updates, and booted into an X11 session. Next, to Display Configuration to re-enable the right hand monitor (disabled the night before). Immediately, I was struck by how bare the settings window looks compared to Wayland. Here are screenshots of the settings for same HDR monitor on 6.3.5.
Wayland:
X11:
Second thoughts and hello, Dr Konqi
Time to enable the display. For reference, this takes moments in Wayland. It was just a wee bit longer and more fraught with X11.
After enabling the monitor and clicking Apply, all 3 screens went dark. After about 20s the laptop display came on. After about another minute, the right hand display finally got output before all 3 displays were dark again. I unplugged the laptop from the dock. It came up to the login screen. After logging in I saw the good Dr Konqi telling me there was a crash in plasmashell. We were off to a great start.
Like a good tester, I sent the crash report off. With some trepidation, I plugged the docking cable back in, as similar struggles from years past came back to haunt me. All three displays were black, although I could move the cursor around in them. It took a good couple of minutes for plasmashell to display everything, along with window decorations and panel contents. It was faster later, but wow, was this a noticeably worse experience than Wayland.
Other observations, or third thoughts
Wayland advantages
Fractional scaling - the ability to have a screen at, say, 110% zoom. See that lovely screenshot, above. When paired with how easy it is to change font face and style, this is great for accessibility. Being able to read the text on any display at whatever resolution can't be overstated. When I have to use Windows, where you can't adjust text separately from resolution, I have sadness. I also have eyestrain trying to read tiny text in dialogs.
Scaling per display - so my laptop's high resolution display can be at 150% and my external displays at 100% to make things readable on all of them. Another plus for accessibility.
HDR and color profile (ICC) support. This is important for getting the mos out of my monitor with games and more. Also... preeeetty.
Snappier overall performance (on my systems).
The ability to send a window to multiple desktops, or just one. In X11, you can ....THNG
The most annoying problem for me is with LibreOffice, since I use Calc almost daily. There's a bug (on their tracker) where, with multiple monitors with different scale factors, UI elements are too big.
Lack of a robust, easy to use text expander with a GUI - that actually works out of the box. Autokey has been on my installs for many years, used for work and personal stuff. While it launches, and I have access to my phrases, there's no actual text expansion. There's an open issue for Wayland support (that pre-dates the Pandemic) but it hasn't gotten much traction. I've been keeping an eye out for years for a decent replacement, and have tried a few things but not found what I'm looking for, yet.
Copy and paste to and from VMs
I use VMs a lot for testing things on different Linux distros. My workaround for this is to have text files saved in a directory that's shared from host to guest.
It took time and a few forks to get KVM software that was reliably developed and worked with Wayland.1 I had been using barrier on X11. A few software forks and experiments later, I've settled on deskflow.
X11 Advantages
Remembering window positions across reboots.
Working text expansion.
X11 pain points
Drawing the screen is slower after logging in or restarting plasmashell, for example, with the same hardware and open applications.
Floating panels and adaptive opacity are known to cause performance issues with X11 with an NVIDIA GPU.
Lack of scaling per-monitor. Text on my XPS's screen is too small to be readable if the external monitors are at a comfortable scale. I had to move any window I needed to read text on (most of them) to the external monitors.
The HDMI monitor was set to the wrong resolution and refresh rate if I connected it to the second laptop. I had to manually correct it.
After enabling HDR on that monitor with the Flex in Wayland, and switching to an X11 session, the monitor enabled HDR but the colors were over-saturated.
After working with a few windows, fonts in Firefox became badly hinted. This made characters look weirdly colored instead of white / black, and made reading things difficult.
Final thoughts
Once upon a time, Wayland was too painful for me to use as a daily driver. It didn't support some of my utilities and it wasn't stable enough with my multi-monitor setup.
These days, Wayland is so much more usable and stable with multiple displays that it makes using X11 painful by comparison. While there are still those few issues I mentioned, I feel Wayland's advantages outweigh them.
The KVM software journey... The first one I used was Synergy, which was amazing to me. Being able to use the same keyboard and mouse on both a Linux laptop and Windows desktop at the same time was magic. Unfortunately, Synergy took their UI in directions I didn't like. An open source fork named barrier emerged, which aimed to restore the simplicity I was looking for, so I switched to it. This served me for a long time, but development stopped in 2021. With the advent of Wayland, barrier was forked to input-leap which implemented Wayland support. Sadly, development seems to have languished. There is yet another project, deskflow, which is also free and open source. It's sponsored by the Synergy folks. We end where we began. ↩︎
In September 2024, the annual KDE conference Akademy was held in Würzburg. I've been to all Akademies from 2004-2020 (except 2005). Then came Covid, private life, etc. So it was kind of special that I finally made it to Würzburg again, which was just a ~2h ride away by train. And it was a good decision: Since many KDE contributors (also those who stayed with KDE a for a log time) came to this Akademy. It was a good opportunity to meet old friends again.
And that remided me of a blog post I wrote 15 years ago: The Power of Developer Meetings. In that post I was highlighting the importance of face-to-face meetings. What I wrote back then is still relevant today, so I'll just repeat:
Social aspect: You get to know the other developers involved in the project in real life, which is a great motivation factor and simplifies communication a lot.
Productivity: Since you are sitting next to each other discussions about what to do and how to do what are very focused. It’s amazing how quickly a project can evolve this way. (I still haven’t seen such focused work in companies yet, even 15 years later).
Knowledge Transfer: Since participants are experts in different areas, discussions lead to knowledge transfer. This is essential, as sometimes developers have very few free time to contributes to a project. Spreading the knowledge helps a lot to keep the project alive.
Steady Contributions: New contributors always pop up, which is in particular very nice. Everyone is welcome to set a patch, get commit access and join development. Experience shows that participants joining developer meetings / conferences usually contribute for years to come.
I enjoyed meeting KWin developers (new and old ones), plasma developers, and Kate developers again (of course!). All in all I am very happy to see the lively community that KDE managed to be for over 25 years - well done!
All of the Maui repositories have the newly released branches and tags. You can get the sources right from the Maui group: https://invent.kde.org/maui
MauiKit 4 Frameworks & Apps
With the previous version released, MauiKit Frameworks and Maui Apps were ported to Qt6; however, some regressions were introduced, and those bugs have now been fixed with this new revision.
Some of the changes and improvements were taking longer, so we skipped the February release and moved it to May, so here it is. With an ever-improving MauiKir set of frameworks powering the set os Maui Apps.
MauiKit Frameworks
A script element has been removed to ensure Planet works properly. Please find it in the original post.
The MauiKit controls templates for list and grid elements have been reviewed, and any binding loops have been squashed. Also, those elements such as GridBrowserDelegate, ListBrowserDelegate, ListItemTemplate, GridItemTemplate set their implicit sizes correctly.
It is now possible for third parties to create custom styles that adapt to MauiKit. Creating a custom QQC2 style is quite simple; to preserve Maui visuals, the new style should use MauiKit properties for setting colors, and elements, margins, padding, and sizing, etc. To allow this, please refer to MauiMan property allowCustomStyling. see [https://api.kde.org/mauikit/mauikit/html/classStyle.html]
Add more resize-edges to the ApplicationWindow in CSD mode
MauiKit ImageViewer type has gained more properties for finer control
MauiKit now disables effects when the software renderer is used.
In nested and composed controls, use the background of the top root element.
Fixes creating dialogs from component types.
TabView and Page controls now support grouped properties for the tabBar and header and footer columns, respectively, to tweak the margins. see [headerContainer.margins: 10]
The PageLayout control can now split the header elements into the footer, but also pick which section of the header will be moved when split, by using the property splitSection. see [https://api.kde.org/mauikit/mauikit/html/classPageLayout.html]
Tweak and better translucency effects for the Page and TabBar headers and footers. (To disable effects, refer to the MauiMan Theme property: enableEffects)
The Nitrux CSD theme has been improved to be more compact visually
The ToastArea for notifications is now keyboard navigable.
MauiKit-Filebrowsing fixes Tagging regressions and multithreading crashing issues.
MauiKit-Terminal fixes and supports for translucency, signaling current working directory changes, exposing background and foreground colors properties, and updating the touch area.
MauiKit-Documents fixes the search results highlights and supports initial text selection.
MauiKit-ImageTools now makes use of the KEviv2 library wrapper for managing image metadata editing. Includes a new image editor based on OpenCV, and improves upon the existing interface for text detection in images OCR.
MauiKit-ImageTools improves the keyboard navigation on its custom controls.
MauiKit-FileBrowsing, the Tagging interface, now emits the right signals upon new tag creations. Improve the OpenWith dialog with an informative header. Improve keyboard navigation and multiple file selection in FileBrowser component using keyboards.
Currently, the set of Maui Apps amounts to over 10+ apps. For this release, the focus has been to improve the experience in the main set of apps, such as Index, Pix, Statio, while keeping up to date with the other ones.
The apps now have better keyboard navigation support, include new features, and a cohesive layout/design where the app’s main content is put on the front by using a modern “floaty” style.
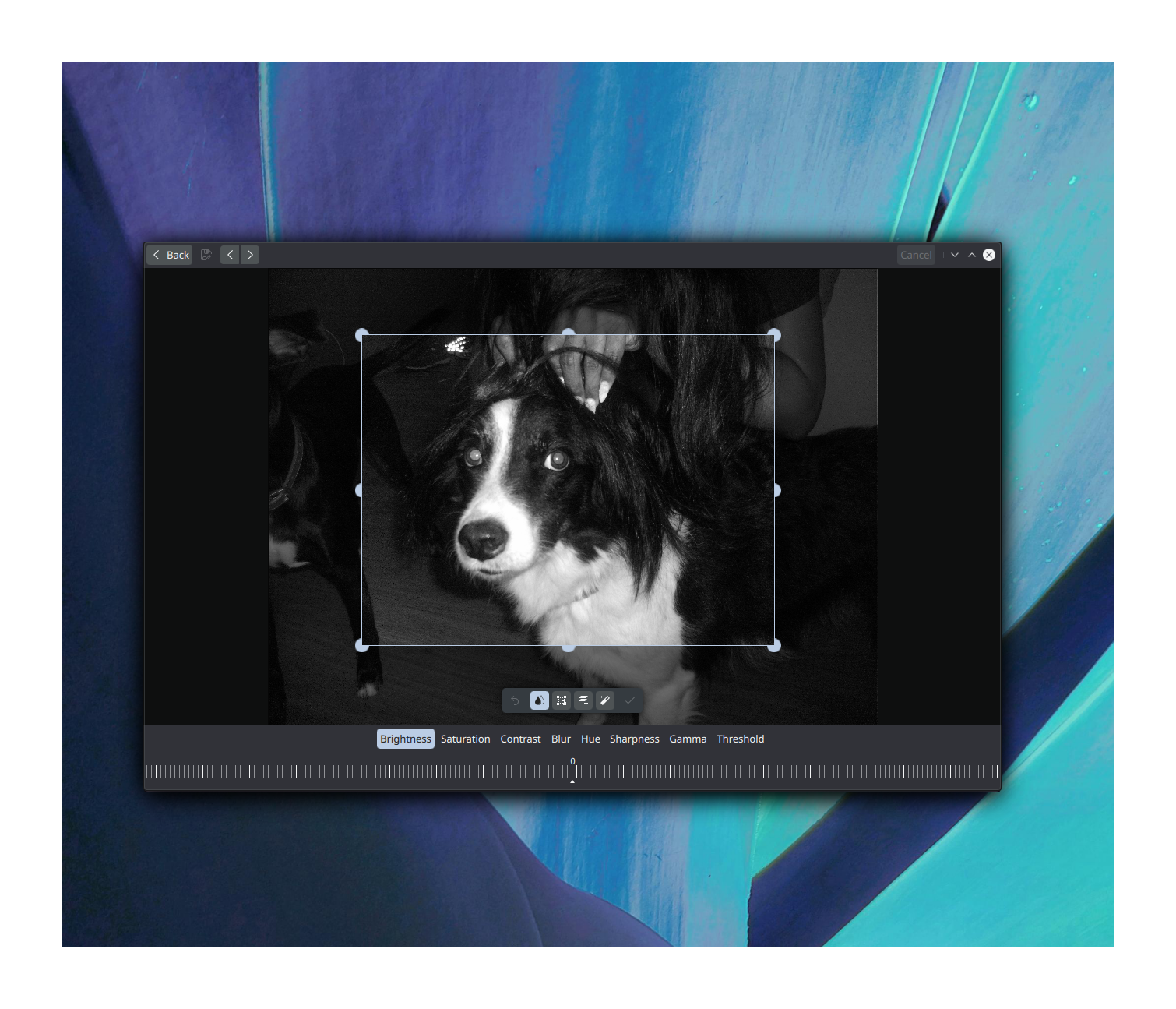
Pix now includes, in the viewer, OCR auto recognition, along with a ui/ux for quickly selecting the text found in images. A new image editor backed by OpenCV , improved navigation patterns, fixed GPS browsing, and a metadata reader and editor now using KDE’s library kexiv2. You can also quickly navigate multiple images from the editor, and in desktop environments, Pix supports opening an image per window.
Here you can watch Pix OCR in action:
The Pix image editor is coming from MauiKit-ImageTools, and for this initial release, it has the basic image manipulation controls, such as brightness, contrast, sharpness, etc. And some experimental filters. Upcoming versions should start adding up much more controls for more detailing editing. Algo object recognition is planned for upcoming releases by using OpenCV.
Station, the terminal emulator, now better supports command shortcuts in a new sidebar, which is useful for touch-based input. The sidebar is integrated using the new floaty style.
For those who fancy a good-looking terminal, Station brings back support for the translucency effect under Plasma. The screenshots below show Station on a PinePhone and a desktop under Plasma using the effect.
From previous releases, Station, can now launch and open URLs from the output by right-clicking on the selected text string. The touch area for mobile screens has been fixed, and the gesture shortcuts work great, and a bottom toolbar with common “keys” is available and responsive to the current program running, for example is running “nano” the keys will be relevant to that.
Index, out file manager, now has an action bar floating over the browser for quickly performing actions.
Index comes with improvements in the contextual menus when applying actions to multiple files and keyboard navigation.
A more focused UI design.
Index, Pix, and Vvave remember the last tag used and suggest it.
Notifies when a file has been tagged and allows opening the given tag from the notification
Fixes to the creation and destruction of dialogs.
The embedded terminal can now be manually synced by using the context menu or the ‘Ctrl+.’ keyboard shortcut
Buho now supports opening notes in different windows in desktop mode. And exposes a server method for third-party apps to save notes to it quickly, for example, Pix is now using this interface to save the text found in an image to a note in Buho.
Shelf, using MauiKit-Documents, now has text selection support and improved found text highlights.
You can follow the project on Mastodon or X to keep up to date on the changes being made. And if you are planning to work on an app for Linux and considering MauiKit for the UI, please do not hesitate to reach up to us for help, advice, or suggestions. Some updates coming from X follow:
Nowadays it is getting more and more popular to write Qt applications in Python using a binding module like PySide6. One reason for this is probably Python's rich data science ecosystem which makes it a breeze to load and visualize complex datasets. In this article we focus (although not exclusively) on the widespread plotting library Matplotlib: We demonstrate how you can embed it in PySide applications and how you can customize the default look and feel to your needs. We round off the article with an outlook into Python plotting libaries beyond Matplotlib and their significance for Qt.
Being the workhorse for more than a decade, it took me by surprise that Qt 5 is going to run out of support tomorrow. Honestly, Qt 6 was released in late 2020 and I prefer using modern code bases that use features from the C++17 and C++20 standards. So, no reason to hold me back.
I am pleased to announce the release of KDE Stopmotion 0.9.0. It consist of the Qt 6 port and has no additional features or bug fixes. Quite boring, it does not even look nicer or different at all. Many thanks to Florian Satzger and Mark Penner for helping with the port when I got stuck.
Behind the curtain, we use KDE CI templates for the build pipeline, increased the minimum required version numbers for Qt, CMake and C++, and some minor warnings got fixed. We are back using semantic versioning. New features are added with an increased minor version number. Increased patch numbers are for bug fixes only.
Adding sound does not work properly, this is a known bug.
You can create the tar ball using the 0.9.0 Git tag.
Get involved!
I was super happy to receive help with the Qt 6 port. It is so cool to work with strangers and achieve so much. Being united by the desire to create powerful software, is a strong motivation.
I am desperately looking for more people to get involved in KDE Stopmotion. If you are looking for a place to make a contribution, consider it! Some areas for contributors come to my mind:
Use more modern libraries to grab the images from cameras. We have several options and some of these are unmaintained for years. Adding more recent options would be great.
Starting with integration into KDE's software stack. Stopmotion is still in the incubation phase. The software uses Qt but not KDE frameworks or other things from the ecosystem like handling the translations or a neat integration of the documentation.
Improving our test automation would be great.
The code base is 20 years old. Some C++ patterns used in the code might no longer be the best choice and a replacement with C++20 code might improve the quality.

 @rossr:matrix.org
@rossr:matrix.org