Hello again, sorry it’s been a while since the last post. In this case, I’m doing a never-before-seen multi-month post!
This may be the last post in this series, as the KDE Promo team has launched “This Week in KDE Apps” which covers my work here (and I also have plans to contribute to… 😅) Nate Graham typically reports on my Plasma changes in his “This Week in Plasma” series. All that would be left is the uninteresting changes, so I was thinking it might be more sensible to do an emersion-style “Status update” that’s isn’t strictly KDE related. We’ll see!
Plasma
[Feature]
You can now tweak the pen pressure. This is useful if you prefer a specific style to your strokes, and you can’t change this directly in your preferred application. We plan to have add “soft” and “hard” presets to make using the curve easier. This is one of the last items paid for by our NLnet grant, so it’s exciting to see it finally come to fruition!
[6.3]

[Feature]
The stylus cursor is now hidden on the Calibration page but this will only work once your distribution switches to Qt 6.8. The credit belongs to Nicolas Fella as he’s the one who put in the work upstream in Qt!
[6.2.1]
[Bugfix]
The calibration accuracy is now improved slightly and refining your existing calibration further should work closer to how you expect.
[6.2.1]
[Bugfix]
Added more safety rails in the Calibration code to prevent possible crashes.
[6.2.1]
[Bugfix]
Made sure the calibration matrix is reset when you hit the “Defaults” button.
[6.2.1]
[Bugfix]
Now the Calibration window opens on the correct screen.
[6.2.1]
[Bugfix]
Now the action dialog doesn’t show up in the wrong place when your KCM scrolls a lot, like mine.
[6.2.1]
Tokodon
[Feature]
The welcome page when you first open Tokodon now looks much nicer and friendly. Hopefully it makes it clearer what Tokodon is, and also includes an even clearer badge to indicate what service it connects to.
[24.12]

[Feature]
Display public servers to ease registration for first-time Mastodon users. Right now there’s not any filtering options, but this is a huge improvement over an empty textbox and expecting users to know where to find a server.
[24.12]

[Feature]
My post tag display improvement was merged, which limits tags to one line. Note that this isn’t the final design we’ll go with, but they will no longer spill onto multiple lines.
[24.12]

[Feature]
It seems people want Cohost’s “Following” feed for Mastodon, and of course Tokodon could do it! So that’s what I did, and implemented Cohost’s “Following” feed. Albiet it’s currently limited due to the Mastodon API we have available, so it comes with two big caveats currently: You only see when people were last active by the day, and the pagination kinda sucks.
[24.12]

[Feature]
Added support for managing your social graph within Tokodon. For example if you don’t want someone to follow you anymore, or to quickly unfollow someone from your “Following” list.
[24.12]

[Feature]
Self-identified bots are now correctly identified on the profile page.
[24.12]

[Feature]
Due to limitations in the Mastodon API, we now put a button on the account page to denote there are more settings available online.
[24.12]

[Feature]
Changed the media tab to a grid view, making it easy to see a user’s media all at once. This works different compared to Mastodon Web as you can even filter by featured tag in this mode - but it’s not shown in this screenshot.
[24.12]

[Feature]
Laid the initial groundwork unread notifications. You now have a number indicator in the sidebar for unread notifications, and mark them as read.
[24.12]
[Feature]
Added list user management, so now you can use lists to their full advantage within Tokodon itself.
[24.12]

[Feature]
The warning iconography for “Content Warnings” are now removed, and replaced with “Content Notice” to denote it’s true and more generic purpose.
[24.12]

[Feature]
Added support for read markers, allowing you to continue reading where you last left off.
[24.12]
[Feature]
Now the authorship of links are displayed in link preview cards including a Mastodon account, if available. See this official Mastodon blog post for more details.
[24.12]

[Feature]
Added a way to view poll results before voting, finally.
[24.12]

[Feature]
Now it’s possible to see which poll options you voted for.
[24.12]

[Feature]
When clicking the “ALT” button, the media description pops up. This could be useful if you want to quickly view what the media is, before unhiding it.
[24.12]
[Feature]
Tokodon now supports displaying admin report, severed relationship and moderation warning notifications. These notifications can then be configured in the notifications settings as per usual. The details shown in the notifications can still use a bit of work, though.
[24.12]

[Feature]
The Notifications page is redesigned, to better suit non-English languages. I also added a button to go straight to Notification settings from here.
[24.12]

[Feature]
When you’re using Tokodon on a newer and emptier Mastodon account, the application is much friendlier with more helpful explanatory text everywhere.
[24.12]


[Feature]
Tokodon’s UI is now more responsive. The sidebar will appear on mobile devices if their screen is wide enough, like the Android tablet I use Tokodon on.
[24.12]
[Feature]
Timeline streaming and read markers can be turned off, if you prefer.
[24.12]

[Feature]
When viewing someone’s profile, a list of people you follow that you have in common is now shown. Hopefully this will make it easier to find new friends on Mastodon!
[24.12]

[Feature]
You can now edit your profile fields within Tokodon, without having to do it through Mastodon Web.
[24.12]

[Feature]
You can now see trending links (or “news”) on the Explore page, and also suggested users. I’m intentionally not showing a screenshot since it doesn’t look very good yet.
[24.12]
[Bugfix]
The font size in the post composer now follows your preferred font setting.
[24.12]
[Bugfix]
Tapping a post only works by tapping on the content itself, not the margins.
[24.12]
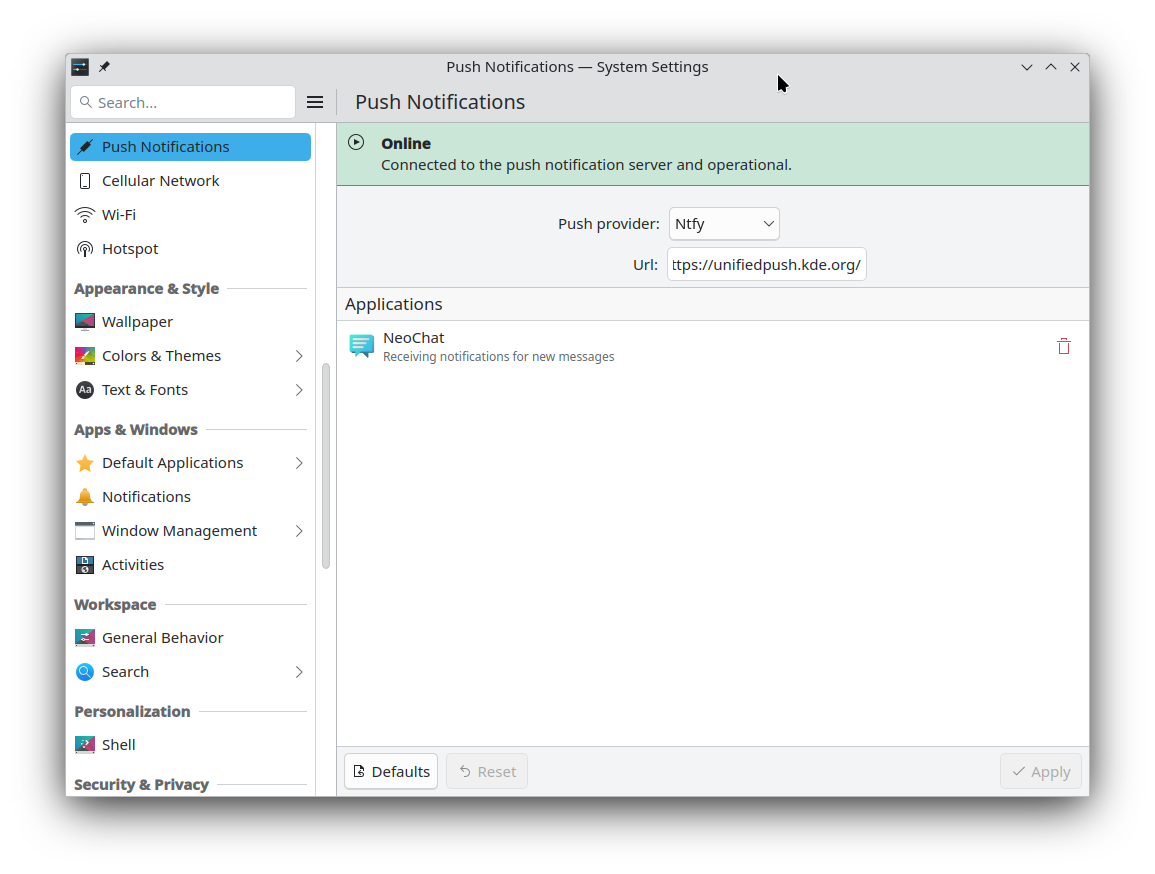
NeoChat
[Feature]
You can open location links in your preferred map application. This is the same Map application under the Applications KCM, so you can choose something like OpenStreetMap or even Marble.
[24.12]

[Feature]
The location chooser is now better in general. There’s a toolbar button to re-center the map, and if your device supports positioning then it can use that to center itself.
[24.12]

[Feature]
The security page is overhauled and now contains more relevant settings from other pages.
[24.12]

[Feature]
NeoChat’s welcome page when you first open it now looks a bit nicer.
[24.12]

[Bugfix]
Now when you only have friend invites and no messages a better icon is displayed, instead of none at all.
[24.12]

[Bugfix]
The buggy look of the date section header is finally fixed.
[24.08.1]
Itinerary
[Feature]
I added support for United Airlines reservations, so they can be imported to Itinerary and show up in KMail. Paired with Kalendar, this makes it really easy to keep track of my travel plans! I hope to add support for more North American airlines as I fly them, it’s surprisingly easy to write extractors.
[24.08.1]

Frameworks
[Feature]
Added support for separator actions in ToolBarLayout in Kirigami.
[6.7]
[Feature]
Added command names for “Remove Spaces” and “Keep Extra Spaces” in KTextEditor, for a secret future project.
[6.7]
[Feature]
You can now disable the scrollbar interactivity on ScrollablePages in Kirigami.
[6.8]
[Feature]
Initial support for QML bindings to the KTextAddons emoticons API. This means that eventually our applications will no longer need to have their own special emoji picker, and our Unicode data will be unified!
[1.6]
Libraries
[Bugfix]
The caption text in applications that use the Kirigami add-ons fullscreen image viewer is now copyable. I usually write alternative text for my artwork in Tokodon first, and then copy it elsewhere. So it’s really cool to be able to do this within Tokodon itself and not have to go through Mastodon Web.
[1.6]
KDE Goals
The goal I championed for, “We care about your Input” was selected! You can check it out on the goals page on the KDE website, which also includes links to our public workboard, chat and the original proposal. Let’s make KDE Plasma the perfect desktop environment for artists! (And everyone else too, I guess 😜)
Akademy
I also attended Akademy this year! You can read more about it in it’s dedicated blog post if you missed it.

It’s been almost a year since I started this series, and I can’t believe I’ve done almost a dozen of these. People seem to really like them, and I’m really appreciative of that! Like I said in the beginning, there will most likely not be a next part as it will be rolled into someone else’s blog posts now.
If you want a hint as to what I’ll be about blogging next, you might want to remember where this all began.
Like or comment on this post
 @pgandhi:matrix.org
@pgandhi:matrix.org GSoC
GSoC redstrate
redstrate