Our community stays vibrant and engaged with the Qt Project through our forums, mailings lists, asking and answering questions, offering technical advice, reporting bugs, contributing patches, and in many other forms helping Qt flourish.
KDE had a feature a lot of people didn’t know about. You could run a command when a notification triggered. The feature wasn’t very well documented and nobody really blogged about it.
However with the release of KDE Plasma 6, the feature was removed. I learned about it by accident, as it is tracked by Bug #481069. I really need the feature and I re-implemented it in KDE Plasma 6. I will be available in KDE Plasma 6.1 and KDE Frameworks 6.1.
KDE: Run a command
Text-to-Speech for calendar events
I’m using the “Run a command” feature for calendar events. Normally you get a popup notification. The popup notification is small and pop up where all of them are shown. When I’m concentrated and working on some code I simply miss them. If I play a game, I miss them.
The solution for me is to use a Text to Speech (TTS) Engine. I’ve setup speech-dispatcher with piper-tts on my system. When an a reminder triggers it says: “Andreas, you have an appointment in 10 minutes: Samba Meeting”.
KStars v3.7.0 is released on 2024.04.05 for Windows, MacOS & Linux. It's a bi-monthly bug-fix release with a couple of exciting features.
CI & CD Infrastructure
We say goodbye to KDE's binary factory as we transition to fully use Gitlab's CI/CD pipelines to build, test, and publish KStars. Over the last two months, Eric Dejouhanet worked with the KDE's Craft & System admin teams to transition KStars pipelines to the new framework.
Short status on pipelines:
Merge requests run the custom build and the CI builds
Master runs the CI build (though there could be other things we run, such as CVE scans)
Craft recipes are run from the last commit of the master or release branch, they require "build" and "build-and-test-stable" to be run manually beforehand.
Publishing to Microsoft store is available after the Windows Craft is run.
This is still an ongoing process and we hope to have this process fully automated by 3.7.1 release where we will automatically publish latest releases for both stable and master branches.
Donut Buster
Rejoice Newtonian, SCT, and RC owners! With KStars new Donut Buster feature, your donut focusing woes might be something of the past. John Evans implemented this experimental feature to help protect against outliers that might affect your autofocus routine. In addition to that, the Focus Advisor is now automatically applied when creating new profiles. Based on the type of equipment you have in your optical train, the Focus Advisor would try to guess the optimal focus settings for your setup. Both features are experimental and would benefit from your feedback.
Custom Views
Akarsh Simha introduced the ability to orient the sky map to match the view through any instrument.
A view is a collection of settings: the orientation of the sky map, how the orientation changes as the sky map is panned, whether it is mirrored or not, and optionally the field-of-view to set the map to.
If no views are defined, KStars introduces a set of standard / "demo" views by default. Existing views can be edited and new views can be added using the "Edit Views..." interface. They can also be re-ordered in the interface. The ordering of the views in the "Edit Views..." dialog defines the order in which views will be cycled through using the keyboard shortcuts Shift + Page Up and Shift + Page Down. Thus, you can set up the views for easily switching between naked eye / finder scope / telescope views for easy star-hopping.
Furthermore, there is a new option in the View menu that enables mirroring the sky map so as to be able to match the view through an erecting prism used for example on a Schmidt-Cassegrain or Refracting type telescope.
The rotation feature overlay now also marks East in addition to north and zenith, so as to know easily whether the display is mirrored or not.
Blinking
Hy Murveit added a very useful Blinking feature to the FITS Viewer tool. This adds several ways to blink; that is, compare multiple images.
In Analyze, one can now move from one session to the next (forward or backward). Keyboard shortcuts are provided for that.
Another set of keyboard shortcuts both advance and show the next image in the same FITS Viewer.
Thus, for example, one can advance through all the captured images of the evening, showing all the captures on the FITS Viewer by repeating a keyboard shortcut.
A useful complement to this might be adding the ability to delete bad captures, but for now that will have to wait for a rainy day.
In the FITS Viewer, the Open File menu command (both in the main KStars top menu, and in the FITS Viewer menu) now allows multiple files to be selected. If they are then the files are opened in individual tabs.
Shift-selecting would select files from the first to the shift-clicked file. Clearly one wouldn't want to select 100 files resulting in 100 tabs, but this can be used to, e.g. compare 10 images.
Going along with the above, keyboard shortcuts have been added to move to the next or previous FITS Viewer tab, Also helpful to the above is a new command to zoom in/out all tabs (not just the current one).
There is a new Blink Directory menu command (in both menus, as above) which will open a single tab with a list of all the images below the directory selected (that is, both in that directory, and in directories below it). It initially displays the first image, but new commands work in that tab to switch to displaying the next (or previous) image file in the list. This could be used to blink hundreds of files.
Sky Flats
Dušan Poizl added an option to capturing sky flats. When shooting flats at sky it often end up in never-ending loop of adjusting exposure because intensity of light change and calculation of exposure break down. Adjust the tolerance to 2000 ADU to higher for a better chance at capturing sky flats.
Scheduler Refactor
Wolfgang Reissenberger continues with his work on Separating Business Logic from UI in Scheduler. Over the years the Scheduler has grown to one of the most complex classes. With this release we refactored the Scheduler class and separated the UI from the underlying state model and its business logic. This opens the door for future development of new scheduling features and a much modular approach towards more flexible sequencing approaches.
Standalone Editor
To add any job to the scheduler, you need at minimum the following:
Target
Sequence File
The sequence file contains all your sequence settings (e.g. Capture 20x15 LRGB images). To create this file, you first need to add sequence job in the Capture module and then save the corresponding sequence. While this facilitates re-usability across different sessions, some users wanted to create sequence on-the-fly in the scheduler.
Hy Murveit developed the standalone sequence editor in the scheduler module where it relies on settings saved from your last astrophotography session. Now it's easier than ever to plan scheduler jobs without having Ekos or your equipment profile running!
If you have used a moderately complex application there are chances that you have
interacted with what is called a “modal” dialog. A modal dialog is a dialog that
requires you to close/address it before you can continue interacting with the main
application window. This can be implemented by the application in a straightforward
manner but compositor didn’t know if a dialog was modal or not.
That is until now the new xdg-dialog-v1 protocol
allows applications to mark their
dialogs as modal or not modal. This allows the compositor to adapt its behavior
according to this hint. For example when trying to activate the main window it can
activate the modal dialog instead. It also enables KWin to use the darkening effect
on the parent window on Wayland.
I implemented support for the protocol into KWin
and Qt which will be part
of the Plasma 6.1 and Qt 6.8 releases respectively. The protocol was created from
functionality in GTK and Mutter by Carlos Garnacho and I am happy seeing the overall
Wayland eco-system now being able to benefit from it.
With this blog post, we introduce the QtQuickComputeItem - a Qt Quick item that allows you to easily integrate compute shader into your Qt Quick Code. Compute Shader are used to perform arbitrary computations on the GPU. For example, the screenshot below shows a Qt Quick application that generates Gray Scott Reaction Diffusion patterns. The simulation is executed by a compute shader that is configured directly in QML.
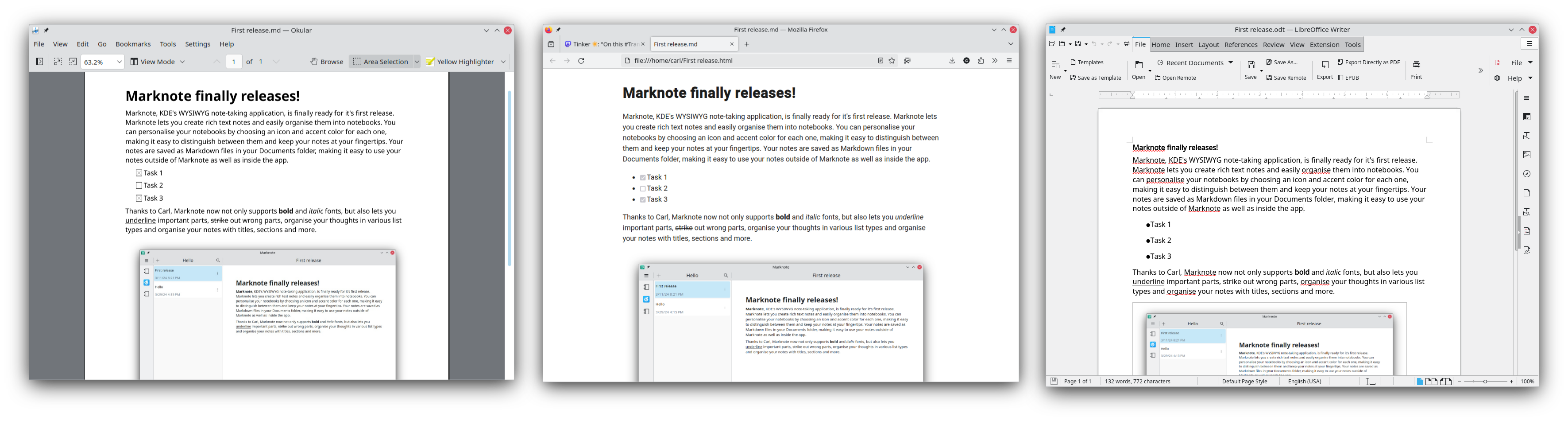
Marknote 1.1.0 is out! Marknote is the new WYSIWYG note-taking application from
KDE. Despite the latest release being just a few days ago, we have been hard at
work and added a few new features and, more importantly, fixed some bugs.
Marknote now boasts broader Markdown support, and can now display images and
task lists in the editor. And once you are done editing your notes, you can
export them to various formats, including PDF, HTML and ODT.
Export to PDF, HTML and ODT
Marknote’s interface now seamlessly integrates the colors assigned to your
notebooks, enhancing its visual coherence and making it easier to distinguish
one notebook from another. Additionally, your notebooks remember the last
opened note, automatically reopening it upon selection.
Accent color in list delegate
We’ve also introduced a convenient command bar similar to the one in Merkuro.
This provides quick access to essential actions within Marknote. Currently it
only creates a new notebook and note, but we plan to make more actions
available in the future. Finally we have reworked all the dialogs in Markdown
to use the newly introduced FormCardDialog from KirigamiAddons.
Command bar
We have created a small feature roadmap
with features we would like to add in the future. Contributions are welcome!
It’s again time for a new Kirigami Addons release. Kirigami Addons is a
collection of helpful components for your QML and Kirigami applications.
FormCard
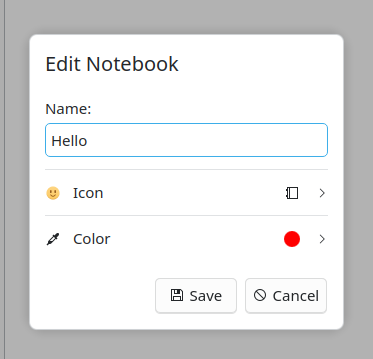
I added a new FormCard delegate: FormColorDelegate which allow to select a
color and a new delegate container: FormCardDialog which is a new type of
dialog.
FormCardDialog containing a FormColorDelegate in Marknote
Aside from these new components, Joshua fixed a newline bug in the AboutKDE
component and I updated the code examples in the API documentation.
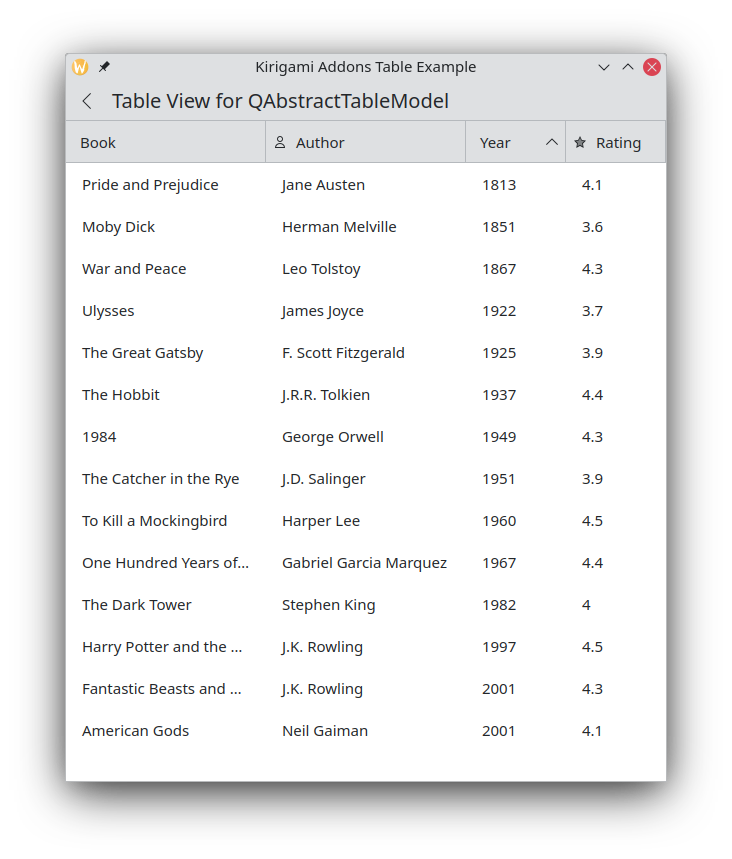
TableView
This new component is intended to provide a powerful table view on top of the
barebone one provided by QtQuick and similar to the one we have in our
QtWidgets application.
This was contributed by Evgeny Chesnokov. Thanks!
TableView with resizable and sortable columns
Other components
The default size of MessageDialog was decreased and is now more appropriate.
MessageDialog new default size
James Graham fixed the autoplay of the video delegate for the maximized album
component.
While everyone is busy analyzing the highly complex technical details of the recently discoveredxz-utils compromise that is currently rocking the internet, it is worth looking at the underlying non-technical problems that make such a compromise possible. A very good write-up can be found on the blog of Rob Mensching...


 GSoC
GSoC

 gladiac
gladiac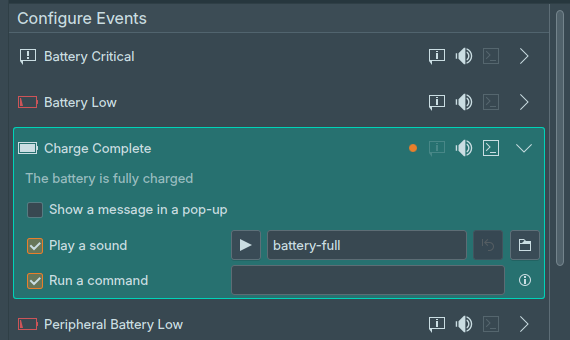



 @davidre:kde.org
@davidre:kde.org