I like to call myself git “expert”, but I failed pretty badly few weeks ago I needed to bisect the kernel source code to figure out one bug.
General git bisect process is, You have two known commits, one is good and one is bad, and you keep searching for bad commit by splitting history in two. Lets say you have following changelog (not the actual changelog I was debugging, but example):
KStars v3.7.2 is released on 2024.08.03 for Windows, MacOS & Linux. It's a bi-monthly bug-fix release with a couple of exciting features.
A few members of the KStars development team were enjoying their summer holidays over the past few weeks, but we still have a couple of exciting features in this release!
Multi-Camera Support
Wolfgang Reissenberger devoted countless hours to bring this complex feature that required lots of architectural changes in Ekos. If you have double rigs (or even more), we have a new great feature: multi camera support! If you have more than one optical train on your mount, you now will be able to run capture sequences for each of your optical trains in parallel from the same KStars instance. You simply need to create an optical train for each of your telescopes on your mount, create camera tabs for each optical train, create their own sequence and let them run in parallel.
This new feature may also be used in combination with the scheduler: in this release, the scheduler itself will control the first camera. On top of that, you could configure additional cameras in the capture tab which could execute their own capture sequences. Enhancing the scheduler such that it could control multiple optical trains in parallel is already under development and will be part of one of the next releases. So stay tuned!
Focus Advisor v4
John Evans refactored the Focus Advisor to make it simpler while still offering a lot of insight on parameters tuning. It is now more accessible to new users and has added functionality to optimize values for 2 of the more difficult Focus parameters: Step Size and Backlash (or AF Overscan).
In addition, Focus Advisor contains a convenience tool to locate stars by searching the range of motion of the focuser and another convenience tool to highlight differences between current Focus parameter settings and those recommended by Focus Advisor.
Akademy 2023 was almost year ago and soon Akademy 2024 is coming. This is probably good time to talk about Akademy 2023. I know it was in way too past but some of those who know me personally/professionally know that last year has been rollar-coaster for me emotionally and did not manage to write about event while recovering from it.
But since this post was sitting in draft from long time, it is finally time to finish and publish it.
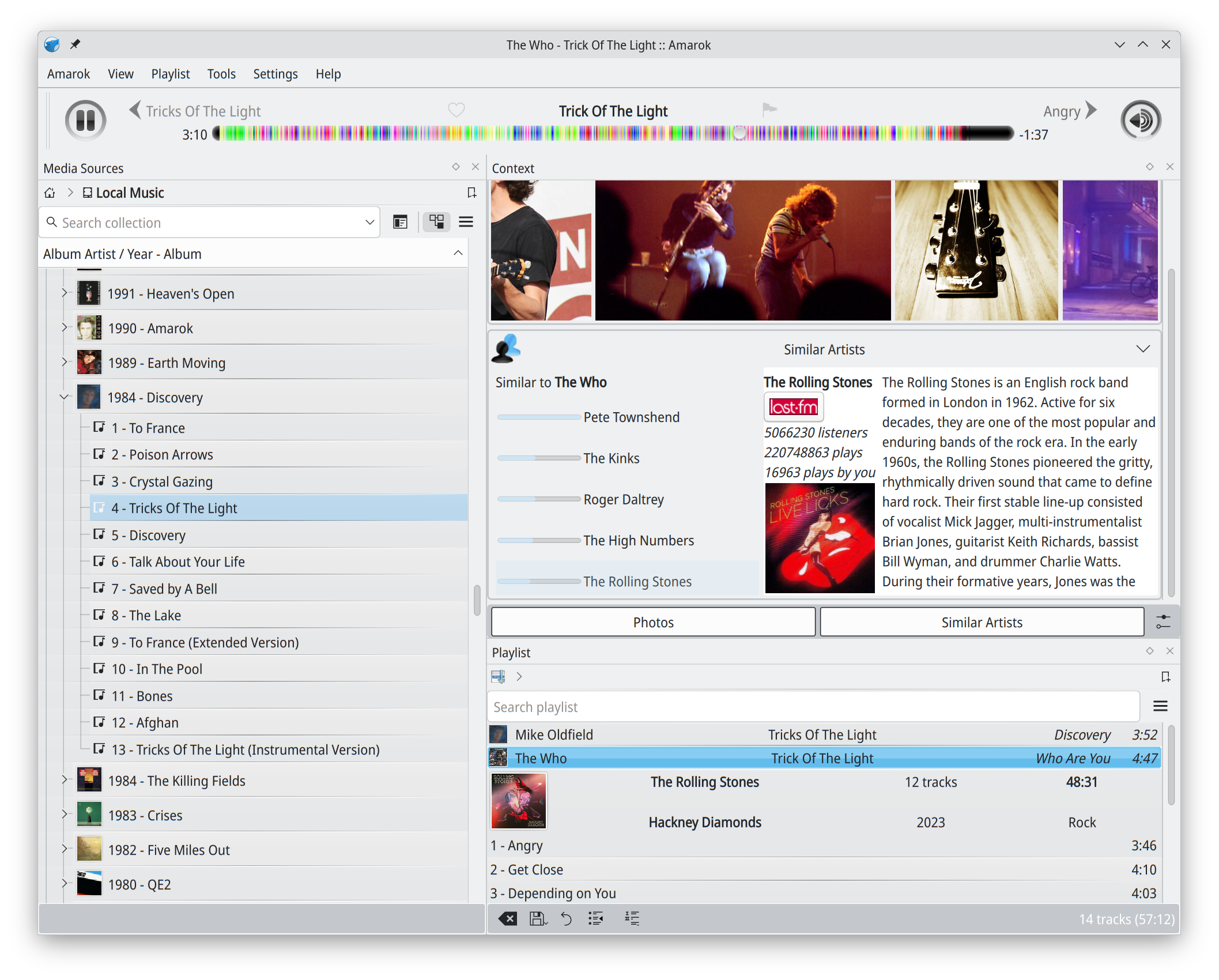
Coming three months after 3.0.0 and two months after the first bugfix release 3.0.1, the main development focus in 3.1 has been getting Qt6 / KDE Frameworks 6
based version closer. We are not quite there yet, but not that far away anymore. And there are some quite nice new features too! Amarok 3.1.0 brings in a refreshed Last.fm integration,
which uses more up-to-date account connection mechanisms, and is better at informing users of any Last.fm errors. Similar Artists context applet does a comeback,
and there's naturally also a nice bunch of smaller features and bug fixes; this time the oldest fulfilled feature request was filed just under 15 years ago.
Changes since 3.0.1
FEATURES:
Last.fm plugin updated to use token-based authentication method and to notify user of session key errors (BR 414826, BR 327547)
Reintroducing Last.fm Similar Artists context applet - a new Amarok 3 version
Remember the previous destination provider when saving playlist (BR 216528)
CHANGES:
Amarok now depends on KDE Frameworks 5.89.
Cleanup of unused code and various changes that improve Qt6 compatibility but shouldn't affect functionality. (n.b. one won't be able to compile a Qt6 Amarok with 3.1 yet, but perhaps with the eventual 3.2)
Remove old derelict openDesktop.org integrations from about dialog. This also removes the dependency to Attica framework.
Disable gapless playback if ReplayGain is active and the following track is not from same album, to avoid volume spikes due to delay in the applying of ReplayGain (BR 299461)
BUGFIXES:
Small UI and compilation fixes
Fix saving and restoring playlist queue on quit / restart (BR 338741)
Fix system tray icon menu reordering
Fix erroneous apparent zero track progresses on track changes, which caused playcount updates and scrobbles to get skipped (BR 337849, BR 406701)
Fix 'save playlist' button in playlist controls
Sort playlist sorting breadcrumb menu by localized names (BR 277146)
Miscellaneous fixes to saving and loading various playlist file formats, resulting also in improved compatibility with other software (including BR 435779, BR 333745)
Don't show false reordering visual hints on a sorted playlist (BR 254821)
Fix multiple instances of web services appearing in Internet menu after saving plugin config.
Show podcast provider actions for non-empty podcast categories, too (BR 371192)
Fix threading-related crashes in CoverManager (BR 490147)
In comparison to changes between 2.9 to 3.0, the git repository statistics between 3.0 and 3.1 are somewhat short:
However, this is an excellent spot to send a huge thank you out to everyone who has been on board outside the git history;
translators, packagers, bug reporters, writers, commenters, and of course: users - music fans all around the world!
Happy listening, everyone! You rok!
Getting Amarok
In addition to source code, Amarok is available for installation from many distributions' package
repositories, which are likely to update to 3.1.0 soon.
A flatpak is currently available on flathub-beta.
It’s been a while since my last blog post regarding text. Since then I’ve been working on the on-canvas text tool, as well as multiple reworks for rich text editing, the actual text properties docker for this rich text editing, and finally I’ve done a talk at the Libre Graphics Meeting about my work on the text tool.
I’m now at the point that I’m going over each property and thoroughly polish it. Because I’m also doing frequent updates on the krita-artists forum, I’m hoping to punctuate each polish session with an introduction to the property, and because I also have a lot of technical things to talk about, I’ll be making technical blog posts alongside that, of which this will be the first.
So the first thing that needed to be tackled after putting together the basic text properties docker and the related interaction is font selection. Krita’s text tool is based on SVG+CSS, and uses FontConfig to select fonts. Typically, a font selection widget will show the list fonts, and in some cases, it organises this in two dropdowns, where the first is the font family, and the second a sub family, like italic or bold. So obviously there’s meta data for this, right, and you should just plug that in the right places, and everything’s peachy? Well, we do have a lot of meta data…
Family Relations
For digital fonts, the OpenType format (in both ttf and otf flavours), is the most common digital format. For formats older than it, the family relations are usually limited to regular, italic, bold and bold-italic (‘RIBBI’), but OpenType also allows for weight/width/slant (‘WWS’) organisation, or even a completely arbitrary organisation under a single typographic family. All at once, too, because not all programs have the same font selection features. These are stored in OpenType names 1, 2, 16, 17 and 21, 22. You can model their relationship as a tree, as in the following example, where we have a single typographic family with a sans, a serif, both of which are WWS families, and each has a variety of RIBBI subfamilies, some of them (semibold) being a single font:
Typographic family (ids 16, 17)
Sans (WWS family, ids 21, 22)
Regular (RIBBI, ids 1 and 2)
Regular
Italic
Bold
Bold italic
Condensed (width variant)
Regular
Italic
Bold
Bold italic
Semi-bold
Regular
Serif
Regular
Regular
Italic
Etc…
This is of course not only stored in the names, it is also stored in the OS/2.fsSelection flags, and for WWS, there’s width and weight data in the OS/2 table. However for typographic family, there’s no way to identify separate WWS families besides the WWS name being present (besides a bit flag in fsSelection, which indicates there’s only one WWS family, but this too cannot be relied on). Furthermore, variable fonts don’t have subfamilies, but rather “axes”, and perhaps some “instances”, which are internal presets of those axes.
And that’s not all, not all fonts are required to have this data, only fonts that are not sufficiently described without all names present, so the default font of a given font family only needs names 1 and 2 to be present, the semibold only names 1, 2, 16 and 17, and so on.
FontConfig is somewhat build to handle this, the default ordering ( undocumented , of course) of the font family names being WWS, Typographic and finally the RIBBI family name. However, The WWS family name is quite recent, meaning there’s many fonts that only have a typographic and RIBBI name, despite having a difference in, say, optical size data, or one of those layer typefaces.
This works because many of these font selector widgets don’t select a family, but rather, they present a bit of ordering for you to select a font and finally store a specific identifier to that font, like the PostScript name, in the text object. Because we’re using CSS however, we store the font family, and specify the weight, width and slant. This has its benefits, as when a font is absent, we can still infer the intention that something was to be set bold or italic. But that does require that the font can be selected by family at all, so if FontConfig cannot associate a WWS family, that is kind of a problem.
Finally, some fonts have a STAT table, which gives even more info about those axes (if a variable font) and allows for non-variable families to describe their relations in an axis like manner. There’s no API to retrieve this info in Harfbuzz, however, FontConfig knows nothing about it either, and even the CSS working group hasn’t made any statements on whether to interpret the STAT table at all. Mind you, even with api for the STAT table, too many fonts don’t have it, so it is not a solution in itself.
Family Reunion
So, the best way to go about this is to sort the font families. This will require opening each font file up with FreeType or Harfbuzz, and retrieving the data you need, as fontconfig doesn’t store everything we need to identify the different families.
For this purpose, I created a struct to put the data in, and organized the structs inside KisForest, which is a templated container class that allows storing data in a tree, and provides a bunch of itterators to traverse said tree. This allows me to create a top level node (‘typographic family’ node) for each font as I find them, and then sort fonts into those. Then afterwards, go over each node again and sort them into individual WWS families, as WWS family names are in fact kind of rare, and the majority of fonts that need them don’t have them.
The second sort is done by going over each toplevel typographic node, and then take all the children. Of the children, you first select all “regular” fonts (the ones closest to width: 100%, weight: 400% and no italic or slant), and adding those first, each with their own WWS family, and then sort the rest into those. Care will need to be taken for fonts that have different optical sizes identified as well (there’s, of course, four ways this can be stored: OS/2 optical size range; size OpenType tag; ‘opsz’ variable axis and STAT table axis), as well as keeping track of situations where multiple formats of the same font are installed (The Nimbus family on many Linux distributions is often installed as OpenType font as well as two separate Postscript fonts, I’m currently sorting those into the same font family). For bitmap fonts, you want to sort the separate pixel sizes into the RIBBI family, depending on how you interpret bitmap pixel size.
Once that’s done, the CSS font matching algorithm needs to be implemented. CSS is explicitely vague about what it means by a font family (this whole blog has assumed up till now that if a give subfamily cannot be selected with CSS parameters, it needs to be in a separate WWS family), but it does specify that any localized names should be matched (localized names are rare and only really used for CJK fonts, but they do exist). So in practice, you end up testing all the possible names, that is, OpenType ids 1, 16, and 21, in the order of the lowest child node to the parent (because remember, the most default version of a given family only has id 1, so you want to test that first). Then comes the actual style testing, the algorithm of which is more or less the same along width, weight and slant, with weight being special for having a default range to test first, while slant needs to be multiplied by -1 first, which it needed anyhow to cohere the specs (CSS dictates that positive slant should skew to the right, while the OpenType spec requires negative slant to skew to the right).
After all of that, the filenames that rolled out of matching can be added to the FontConfig search pattern to prioritize them in the regular fallback search, which I am very thankful of.
While nowadays an example like this would be best off using a color font, there’s many examples of older fonts that are meant to be used layered (as in, two text shapes overlapped with the same text but different subfonts). This particular font, Sweetie Summer, predates any discussion about WWS, only having a typographic family and ribbi family, which lead it to be unselectable with fontconfig.
Presentation
But getting the matching to work for odd fonts wasn’t the only thing that was necessary. Fonts also needed to be displayed nicely. Even more, I really wanted to integrate them with Krita’s resource system, as that would allow tagging and search. These are important usability features as modern operating systems come with hundreds of fonts, so being able to tag fonts with “cursive” and “display” and then filter on that can make it much easier to find an appropriate font. Not all design programs have this feature, which has led to a number of designers to use a so-called font manager, which effectively allows installing and deinstalling fonts by user-defined group (KDE Plasma even has one of these build in, and I’d be suprised if there wasn’t one for Gnome somewhere). Inkscape has quite recently introduced font collections, whose purpose is similar, and given we spend 2 years reworking our resource system, which can do exactly this, it made sense to try and get this system working.
There’s some quibles however: vast majority of resources within Krita are tied to a file, while such a font family resource is an abstraction of a collection of files. This results in problems with getting a preview generated as well as updating an entry between restarts of Krita.
Then there’s selecting the style. This one is a bit abstract, so bear with me: So, as explained before, CSS selects the font file to use by using the user-defined font-family and a set of parameters (width, weight, slant, etc). This has both the benefit of having a certain intent (whether the text is condensed, or the weight is set heavy), as well as being a good abstraction that encompasses both regular font families and variable fonts.
This abstraction is implemented as each font family resource having a set of axes (for variable fonts these are the axes in the font, for non-variable, these are an accumulation of the different parameters associated with the subfamilies), and styles which form a sort of preset for those given parameters (encompassing the instances of variable fonts, and the actual subfamilies in non-variable fonts). This way, you can have fonts that use the OS/2.fsSelection bitflags for indicating bold and italic, you can have fonts that use the OS/2 table values, you can have fonts that have variable axes, and all these will have the same toggles in the same place. If in the future the STAT table is going to be read, the extra info for that will easily be integrated in the same system.
There’s some more toggles than the WWS parameters though, for example, toggles for synthesize slant and bold. Some people think that nowadays, these are not necessary, but that’s really only true for scripts with few glyphs. In fact, we had to implement synthesized slant and bold because CJK users were having missing it dearly in the new text layout. On the flip side, in European typesetting, synthesized versions are considered ‘dangerous’ as it can be hard to tell if the correct bold version was selected, so a toggle to turn it off is required. This needed some extra work with variable fonts, as active slant and italic axes are not testable in the usual manner. There’s also optical size, though this is only supported for variable fonts that have an ‘opsz’ axis, as the CSS Working Group doesn’t seem to have an opinion on the other three ways optical size can be indicated. Finally there’s the remaining axes, in case of a variable font with extra custom axes.
So, this sounds to work right? Where’s the issue with styles? Well, some might say that the split between a font-family and the style is unnecessary, it would be much better to just see all the styles at once. In fact, Inkscape has been implementing this recently. Which means I’ll be asked why I didn’t implement that, because obviously I should.
The main problem here is a philosophical one. The reason Inkscape is implementing this is because its user base wants this UI, and the reason the user base wants this UI is because other software they’re using has this UI. So far, so good.
However, other software has this UI because it has a different kind of text layout system. As noted before, the font selector in these programs is just a fancy way of selecting a specific font file. Within programming way of saying “select font file XYZ” is considered an ‘imperative’ way of programming. This is quite common in WYSIWYG (what you see is what you get) editors, as its easier to program. Markup based methods like CSS instead has a ‘declarative’ way of programming: “Select from this font family a font with these parameters, and otherwise these other font families”. A system like this usually tries to infer properties, which is harder to program, but also means less properties need to be set.
The philosophical difference here is that I don’t think it is wise to try to abstract away the underlying data structure, because I think it leads to bugs that are kind of hard to articulate if you don’t know the UI is not representing the underlying structure properly. This is also why it is weird to see people go “Well, UI should be completely decoupled from the business logic”, because even if you programmatically decouple UI and data, the fact remains that the UI can only do what the data structure allows. The data structure by itself belies a workflow, which in the case of mark-up based type setting general, is one that focuses on consistency, and that if you want to make a small modification, only a small modification is stored.
The importance of the underlying data structure is something that I always feel is missing from discussions about the UI of Free Open Source Software, which is why I am emphasizing it now. The main idea of “listening to your users” is not bad, and even for my own work I did talk to other artists on KA to try to get a feel of what artists using Krita prioritize. But text in particular is also far more tricky than this, because the main reason both the Inkscape folks and us went with an SVG+CSS based text layout is because it is a specification that is widely used (just not in graphics programs…) and has a lot of thought put into multi-lingual and non-European text handling (which is still quite rare today). And I think it is going to cause trouble if you try to apply UI conventions that belong to a different kind of text layout.
The main issue I foresee with this approach is that there’s no mind paid to font family fallback. In an online situation, font family fallback is mainly for what to do when a font family can be found. In a local situation like a graphics program, it is mostly useful in multi-script situations. Many fonts only have glyphs for a small subset of Unicode, often limited to a single script with supplementary punctuation and numbers. So in multi-script situations the CSS font matching algorithm requires you to check if a glyph can be represented, and if not, you must check other fonts on the system till you find one with the given glyph. Font family fallback allows you to have some control over this mechanism.
The font family list allows us to control the fallback. Many fonts only have glyphs for a subset of unicode, so controlling fallback can allow us to select fonts that seem to be in a similar tradition, like using a Serif Latin font for a Naskh Arabic font.Not all scripts have similar traditions, so control over the font fallback is also useful in selecting a font that may not fit within the same tradition, but might look good in terms of contrast, so the Latin text, in this case, stands out less.
Another thing that’s kind of difficult here is that it hides the fluidness of variable fonts. Because where before we could treat instances as a sort of preset for the parameters, they now are presented as a whole font to select. To further explain, one thing I’m fully expecting to happen for Krita is that we receive a bug report with “I turned off synthesis for weight, but still Krita is showing something for a weight value that doesn’t correspond to a style”, and I’ll have to reply with “Yes, that’s because you’re using a variable font”, expand on that, and then close the bug as RESOLVED, NOTABUG. By focusing too much on the styles as individual fonts to select, we’re inhibiting people from updating their mental model of how fonts can work.
Visuals
Of course, because there’s so much variation in what the different fonts can do, it is necessary to indicate the capabilities of a font. Many font selectors have at the very least an icon for the font type. Because there’s been a flurry of activity within OpenType in the last decade, there’s now also variable fonts to keep an eye on, and four (five?) different ways to do color font representation, and those can all be present at once. Krita only really supports the Bitmap and ClrV0 implementations, so we need to indicate which color font data is present.
Other than that, the font name should be present. As well as a preview for the given font. We could technically do the latter straight up with the text layout, by putting a KoSvgTextShape inside a QQuickPaintedItem, but I worry that might be slow on some systems. Instead, I’m laying out the text and converting the result to regular paths, storing the SVG, and then painting the path from that within a QQuickPaintedItem. The sample text chosen uses FontConfig supported languages list, though I am wondering if we’re not better off testing CharMap support instead, as to ensure we will always have some glyphs from the font available. Anyway, I’m quite pleased with the result, as it allows us to display the sample nice and sharp.
One thing that is also tricky is the localization. Basically all user-facing strings within OpenType can have localized variants within the font, and if those are present they should be displayed. In practice this means that these localized strings get stored in the KoResource as well. The models for tracking the styles and axes receive a ‘setLocales’ function, so that when the font name is requested within QML, the text label will receive the localized name. However, with the resource model this isn’t feasible, as the font family resource is the only one that holds localized names. Thankfully, a QVariantHash is treated as a javascript object/dict within QML, so the localized names could be stored into the metadata QVariantMap (note that QML does not support converting QVariantHash to a dict(!), and then tested against the KLocalizedString::languages() stringlist (though care must be taken to ensure the underscore is replaced with a dash).
Eventually, we’ll prolly need to do the same with the writing system samples. However, that should probably use the language the text shape is tagged with, as it is very common for multi-lingual artists to keep the software in English, so they won’t have to guess at a translation when doing an internet search for a given label. So in those cases where you’d need a different sample (like, a Arabic sample if you’re typesetting Arabic), it is probably combined with a different language being set on the text. Mind, there’s no language selector yet, because SVG+CSS uses BCP47 language tags, and I haven’t figured out how to capture the richness of those tags in a discovery friendly ui. Being able to limit the visible fonts based on whether fontconfig thinks they support the active language would also be useful in the same vein.
FontConfig Rescan Interval
When discussing the architecture of how to implement this, it was mentioned that FontConfig has a rescan mechanism. This is basically FontConfig checking if any changes had happened, and if so, updating the font list, and the default on most Linux systems for this is 30 seconds. I think most programs just turn this off, but the person I was talking with went “oh, yes, this is how you need to implement this”, which was a little confusing because our resource system doesn’t actually support refreshing resources during a session. I ended up implementing what they asked of me, as a show of good faith, but there’s multiple refresh problems with it (because our resource system was not build to handle this). It will probably be disabled in the end, unless the refresh problems turn out to be trivial to tackle.
Postamble
A returning theme in handling fonts, OpenType fonts in particular, is that there’s at the least 3-5 ways of doing one common thing. This is not unusual, and often happens when people need a certain function to be part of a specification so badly that there’s no time to standardize. Because of this complexity though, implementing a good font selector still took about a month. At the same time, I’m happy I spend time on this because it would otherwise hang like a thunderstorm over the whole text project, as it would be a matter of time we’d drown in bug reports about this-or-that font not being selectable. That is still going to happen, but at the least there’s a framework to deal with edge cases now.
The next topic I’ll be tackling is probably going to be font size and line height.
Appendix
TTF vs OTF
So an OpenType font should be in a file called the Open Type Format (otf), right? Then why are most of them in the True Type Format (ttf)? Aren’t these two the same?
ttf and oft are the same format, yes. The original spec was called TrueType, and the glyphs were outlined with quadratic bezier curves. One of the things that was added when the spec became OpenType, was that the glyphs could now also be outlined in CFF (compact font format, PostScript, basically), which uses cubic bezier curves. Since then, a font stored in a ttf file is an OpenType font with quadratic bezier curves, and a font stored in an otf file is a file with cubic bezier curves. I am unsure whether since the introduction of variable fonts this difference isn’t purely conventional however.
Italics and Obliques
Because blogpost is aimed at readers that are probably not typography (or lettering/calligraphy) nerds, let’s speed through the history of Latin script as to explain the difference between Italics and Obliques and why they’re sometimes confused:
The history of Latin script is basically the existence of a formal style of writing (a ‘ductus’), and then because clerics need to write a lot, them developing a less formal style that’s easier to write. That one then formalizes, and then a new style is developed. So if we start with Roman Square Capitals (like Trajan), it is followed by a variety of less formal styles like Uncial and Rustic Capitals. Around the middle ages however, the formal ductus and less formal ductus are unified into one system of capital (‘upper case’, also called ‘majuscule’) and miniscule (‘lower case’) letters. However, clerics needed a faster way of writing, so a given blackletter style would often be developed into a chancery or court style.
Fast forward to the Rennaisance. Italians are making their first printing fonts. For reasons I don’t want to get into, they choose Roman Square Capitals for the capitals of their typefaces and combine those with Carolingian miniscules. But they want more typographic richness, so the popular Italic chancery hand is turned into a printing font as well. There’s some notable difference between Carolingian miniscules and Italian miniscules, in particular, the ‘a’ and ‘g’ are written differently, as is the ‘f’:
Then, much later, in the nineteenth century, Sans-serif fonts were introduced, which find their origin in sign-painting. For some reason, these fonts don’t use an Italic ductus for their corresponding slanted style, in fact, the slanted style is just that: slanted (an ‘Oblique’). My best guess is that this is because this font style comes from sign painting and thus is optimized for legibility, and frequently uses an Italic ‘g’, combined with a Carolingian ‘a’ for this purpose. So they may have considered a simple slant much more distinguishable than trying to create a full Italic ductus compatible variant.
By the time computers get involved, a slanted version of the font is considered paramount, as many academic style guides require Italics to indicate quotes and book names. By this time, Oblique variants were considered acceptable, which is why ‘synthesized italic’ just ends up being a digitally slanted version of the original. Fonts that combine both a rare, but exist, so OpenType specifies an extra bit to indicate that a font is specifically an oblique version, but it seems that this didn’t catch on. Even now, with OpenType variable fonts and the STAT table making it much easier to define a slanted version, there’s still hesitance to use it as nobody knows which software supports selecting it.
Furthermore, many other writing systems use various script styles to indicate quotes and such, yet, these are not recognized as ‘Italics’ by computer software. There’s therefore something very arbitrary about Italics by themselves: There’s nothing stopping a font designer from creating a black letter or copperplate style for their font family, except how to handle the font files so that software can select these.
Slant
Slant, within variable OpenType fonts, is a different toggle from Italics. And it can go either way, similarly, there is such a thing as a ‘upright Italic’. So that begs the question: why are Italics usually slanted? This has to do with calligraphy, in particular, the reach of the right hand.
Because the right hand has a reach that goes from top-right to bottom-left, it is likely to skew vertical lines to the right.
If you write with a left hand the same as with a right hand, you get the same effect, but flipped.
For lefties like me, to do right-slanting calligraphy we need to either write with our hand over the line, or rotate the paper.
Now, for European scripts, this is usually for italics, but sometimes a slant doesn’t express a calligraphic quirk, but rather a feeling of forward motion. Which is why for right-to-left scripts, you will sometimes see a left-leaning font being used.
So after filtering out tiny movements and duplicate outputs, the thing left is to look at small corner inputs. Here's the three pointer that I'm working on in kis_tool_freehand:paint: ( Lets say the scenario is that we are drawing a straight line from left to right) We start at point(0,0) Right now there is no last drawn pixel, just a current pixel and a waiting pixel that is set to the current pixel . If there is another doStroke or mouse release we just draw this pixel. (basically always draw this pixel) Try to imagine that the waiting pixel is basically the current pixel that performs the drawing, but always slightly lags behind.
We moved the cursor to (0,1) That last waiting pixel of the last iteration is drawn, and becomes last drawn pixel. Now we are at point(0,1) where both the current pixel and waiting pixel is. Now we wait for the next doStroke or mouse up. Here is where basically nothing happens just waiting on another point to see if we are allowed to draw this waiting pixel.
two scenarios here: We moved the cursor to (0,2) from (0,1) 1.) If the NEXT currentpixel is still in the same x or y axis as the last drawn pixel, the waiting pixel is drawn and we reset waiting pixel = currentpixel.
We moved the cursor to (1,1) instead from (0,1) 2.) If the NEXT currentpixel is NOT in the same x or y axis as the the last drawn pixel, the waiting pixel is not drawn and we reset waiting pixel = currentpixel.
Now we are at (1,1) and we can practically restart from the start again. There is "no last drawn pixel", and we just draw at (1,1) and then apply the rest again (waiting for the next pixel, checking if its in a line. If so draw it, if not update waiting pixel without drawing and then restart again.)
A few problem that has come up is that, compared to other programs with pixel-perfect, this doesn't seem to proactively draw at the same time AND reactively get rid of the corner ( when you draw a straight line, the corner pixel does seem to pop up UNTIL you input a third non-striaghtline pixel, in which the last pixel in the previous line disappears ). I was wondering if there is a way that I can erase reactively like this as well, or maybe calling draw on m_d->previousPaintInformation with the previous color. The other problem I'm dealing with is the initialization of these Qpoints might be a little flawed because, depending on the stroke speed or the type of stroke, since at paint we might completely skip some pixels. I also need to work on some sub-pixel inaccuracies, probably by getting rid of floats.
[Feature]
Add an option to block invites from users who you may not know, to help users being spammed by bad actors on Matrix. This is could also be useful if you’re only using your Matrix account to communicate with friends & family.
[24.08]
[Bugfix]
Don’t mark invite notifications as persistent. This is also meant to cut down on the possible notification spam. This is especially important on KDE Plasma Desktop which doesn’t handle notification spam well at all, at the moment.
[24.08]
[Feature]
Added basic support for SponsorBlock which is turned off by default, but you can enable under Settings. You can’t configure which server to use (it’s possible, just not through the UI) or what specific categories to block yet. You do have the option to have PlasmaTube inform you when you’re inside of a sponsored segment or have it auto-skip.
[24.08]
[Feature]
Added a proper error page to the video player while my Invidious server is borked due to YouTube changes. It will display the error given by Invidious, and also a button to open the original webpage.
[24.11]
After my gargantuan post around the overhauled navigation gestures (and a still-in-progress one about KWin corner touch gesture support I'll hopefully have ready soon:tm:) let's tackle a few more smaller things. I'll try to make these somewhat regular (dare I say maybe even monthly?), but let's see how that shakes out, probably more like every 2-3 months if at all.
As an exciting update, near the end of June (the 25th to be exact) I got accepted to the KDE dev team. This means I now have the ability to properly manage submitted issues on GitLab and, only slightly terrifyingly, I'm now allowed to push code changes to the main repositories and review MRs. Let's see when, if ever, this feeling of trepidation over having to make quadruple sure I don't accidentally do stupid stuff subsides. Should it even subside or is being very extra super duper careful a good thing. I'll keep you posted whenever I find an answer to that :D
Anyways, let's get to code changes:
Merged Changes
Task Switcher/Gesture Navigation
I sat down and overhauled some of the animations around the navigation gestures of the mobile task switcher: The diagonal quick switch should now look smoother and not be nearly-instantaneous and the flick to homescreen is now a tad smoother and actually makes the task preview smaller while animating instead of looking like it's opening the selected task before suddenly vanishing.
Fixed minor logic bug around task switcher quick switch gesture. It should now correctly open the task switcher when you're trying to quick switch towards the end of a list - if there's nothing to quick switch to, it's better to open the full task switcher instead of just returning to the app you were in before.
I added a task icon list to the task scrub gesture in the switcher to make it visually more distinct to the "normal" task switcher and provide more useful info about the open apps you can switch to. In case you didn't know: In gesture-only mode w (I'll admit this one is a bit older, but this is the first installment of this kind of post so I'm not tooooo strict on the "in July" part): I'm still tracking an issue with this where when the task list becomes too long it's not properly centered anymore, but that should be a fairly simple fix once I get to it.
The main task switcher opening gesture now stops tracking the finger 1:1 in the vertical direction once it's moved a bit past its "fully activated" point. This is a bit awkward to explain, but basically it makes it "more reluctant" to follow the finger infinitely far up. If that still doesn't make sense, here's a video:
The task switcher gestures now have a haptic feedback in some places: When the conditions are met for the task switcher to open (eg: gesture progress is far enough and finger movement speed is slow enough) and when the task scrub mode starts there'll now be a bit of haptic feedback.
Misc
I've done some bug triaging and reproduction here and there, as well as tried to keep up to date on merge requests in the Plasma Mobile world. I still haven't really done a proper review and merge, but I'm trying to look through all of the other ones to hopefully learn how good reviews look like so at some point I'll be able to do them.
Unfinished
I tried my hand at fixing the task switcher navigation gestures being always active instead of just when the gesture navigation mode is actually turned on. To do this properly we probably need to refactor the mobileshellsettings plugin to be accessible via C++ (it's just a QML plugin currently), so let's see how that goes.
I started work on more mobile friendly notification popups. The new design uses a swipe-to-dismiss interaction instead of having a close button. While technically "working" from a functionality perspective, the visuals are kind of broken still. I hope to have this complete by 6.2, but there's still some open questions. I'll probably have to get in touch with more experienced Plasma devs to brainstorm why this is going wrong so badly, but I've not quite given up at bashing my head against this myself. Oh and before I forget: this also affects Plasma Desktop when in Touch/Tablet Mode.
Upcoming
For the next month I wanna try and finish up my work on KWin touch corner gestures (and get another oversized blog post out about those) and then implement them into Plasma Mobile. Once that is done I want to do more bug fixing, triaging and looking at knocking out some tickets for planned bigger picture improvements for 6.2. Let's see next month if a) I get any of this done or b) I even manage to make a blog post since I'll not be home for a while
classAA { public: virtualvoidprint(){ cout << "in class AA" << endl; }; };
classBB :public AA { public: voidprint(){ cout << "in class BB" << endl; }; };
voidtestDynamicCast(){ AA* a1 = new BB; // a1是A类型的指针指向一个B类型的对象 AA* a2 = new AA; // a2是A类型的指针指向一个A类型的对象
BB* b1, * b2, * b3, * b4;
b1 = dynamic_cast<BB*>(a1);// not null,向下转换成功,a1 之前指向的就是 B 类型的对象,所以可以转换成 B 类型的指针。 if (b1 == nullptr) cout << "b1 is null" << endl; else cout << "b1 is not null" << endl;
b2 = dynamic_cast<BB*>(a2);// null,向下转换失败 if (b2 == nullptr) cout << "b2 is null" << endl; else cout << "b2 is not null" << endl;
// 用 static_cast,Resharper C++ 会提示修改为 dynamic_cast b3 = static_cast<BB*>(a1);// not null if (b3 == nullptr) cout << "b3 is null" << endl; else cout << "b3 is not null" << endl;
b4 = static_cast<BB*>(a2);// not null if (b4 == nullptr) cout << "b4 is null" << endl; else cout << "b4 is not null" << endl;
a1->print();// in class BB a2->print();// in class AA
b1->print();// in class BB //b2->print(); // null 引发异常 b3->print();// in class BB b4->print();// in class AA }

 bshah
bshah












 @ken_lo:matrix.org
@ken_lo:matrix.org










 GSoC
GSoC