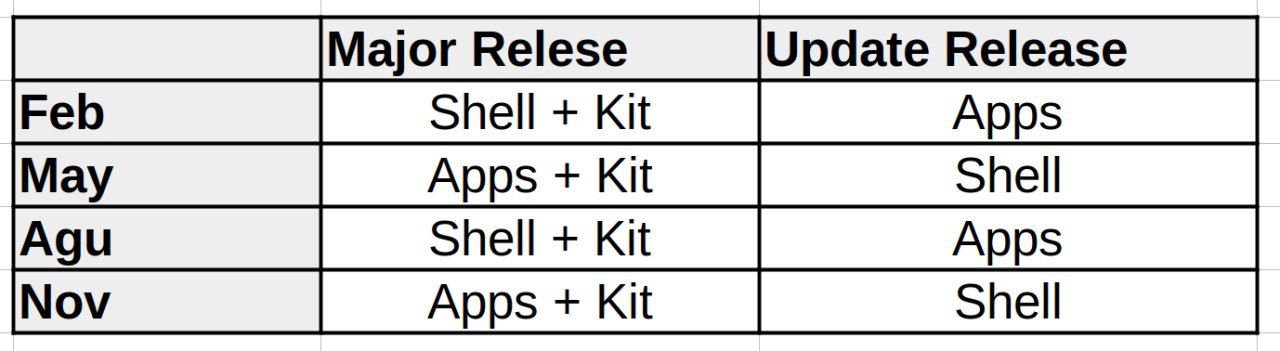
There are some plans to have a more official blog post on the plasma-mobile.org, these are my personal ramblings below…
Plasma 6 is coming together nicely on the desktop!
Coming back from hiatus, I was pleasantly greeted by a much more working session than when I last saw it in May; I have now completely switched over to it on my main machine!
On the other hand, there is still a lot of work to do on mobile to prepare it for the Plasma 6 release in February. I will outline the current situation and the work I have done in the past few months in order to make Plasma 6 a possibility for Plasma Mobile.
Context 🔗
I started working on KDE projects again in October (after an 8 month hiatus), slowly getting back into the groove of things. I unfortunately do not have as much spare time these days after work and school, but I try to do what I can!
The distro situation 🔗
For Plasma Mobile shell development on phones, we need to have distributions with KDE packages built from git master.
Many years ago, we used to have Neon images with Plasma Mobile that were maintained by Bhushan that were used for development, but required a large investment in time to maintain. We no longer have the (human) resources to maintain a distribution, so we are dependent on working with other distributions for development images.
Until this year, Manjaro had helped us by providing daily development images. Unfortunately, I have not really had contact with the project since one of their employees left earlier this year.
As a sidenote: Maintenance of the Manjaro Plasma Mobile images seemed to be inactive in the past few months, though there have been some encouraging signs from the forum in the past few days?
And so, there was a predicament. While I could develop the Plasma 6 mobile shell on the desktop, I had no way of testing it on a phone.
Thankfully, postmarketOS graciously took up the effort of maintaining a repository of KDE packages that track git master. Instructions can be viewed here. With the Plasma 6 beta release, there will be postmarketOS images that can be easily downloaded and tested with!
Seshan has also been working on an immutable distro ProLinux which has images that track git master as well, which have been useful to test with.
Porting 🔗
A big part of the porting effort is simply porting the shell and applications to Qt 6 and KDE Frameworks 6.
In the case of the shell, porting to Qt 6 was luckily fairly trivial. There were far more changes to the base KDE frameworks as package structures and QML plugins were being reworked, though that has stabilized in recent months. There are still some major regressions that need to be resolved before February (will be discussed later), but I am reasonably confident that the shell will in good shape by then.
For applications however, it is more of a mixed bag.
Several applications do not have active maintainers, and others need much more polish for mobile usage (as not all application developers have phones to test with).
Technically, I am responsible for KClock, KWeather and KRecorder, but I have typically done contributions to a multitude of applications to ensure that they work well on mobile. This time around though, I have only been really able to work on the shell with the limited spare time I have, and so I have not been able to do some of the heavier porting work for applications.
KRecorder in particular is unlikely to be ported in time for Plasma 6 as it depends on Qt Multimedia, which has had significant changes in Qt 6.
Beyond porting, I have also noticed some significant mobile-specific regressions in other applications that have been ported, which need to be addressed.
I would encourage anyone who is thinking of contributing to KDE to start here, application development is a very good way to learn Qt and get into further KDE contributions (as it is quite self-contained, compared to, say, the shell).
Styles 🔗
Plasma Mobile currently uses a separate Qt Quick style from the desktop (qqc2-breeze-style vs. qqc2-desktop-style), in which maintenance was lagging for Plasma 6.
The separate style is needed in order to have better performance, as it avoids some of the complex theming that the desktop needs to use for unifying styles between Qt Quick and Qt Widgets applications. However, it is a maintenance burden.
In November, I did a bunch of work on qqc2-breeze-style in order fix Plasma 6 related regressions, and to make it render more similarly to qqc2-desktop-style.
Task Switcher moving to KWin 🔗
In Plasma 5, the task switcher was built into the plasmashell process (which contains the homescreen, panels and most of what you see in Plasma), piping the application thumbnails from KWin.
In order to improve performance, it was a bit of a hack; the task switcher was built into the homescreen, so when it was opened, apps were minimized, showing the task switcher underneath. It was not optimal though, as it required convoluted logic in order to swap between the homescreen and task switcher views, and the thumbnails provided from the stream from KWin were not optimal performance wise.
With Plasma 6, I am moving the task switcher to be a self-contained KWin effect instead, which is inline with how the Desktop overview effect is implemented. This moves the task switcher off of plasmashell to KWin, cleaning up the code and potentially having performance improvements with how the application previews will be displayed.
We can also make use of KWin’s infrastructure for gesture-only mode (removing the navigation bar), rather than relying on a hack with invisible panels in order to trigger it.
The move has been a bit problematic though, as KWin developed regressions during Plasma 6 development that cause effect rendering to be broken on the PinePhone and SDM845 devices (possibly due to OpenGL versions?), but the issues are being worked on. As of Dec. 13, this has been fixed.
Rewriting Folio - the homescreen 🔗
Note: I will be writing a separate blog post that goes much more into detail in the future.
For some context, the default homescreen in Plasma 5 is Halcyon, which provides a simple way have a list of applications, while allowing them to be pinned and grouped into folders.
We also have the Folio homescreen, which was the original default (before Plasma 5.26) that was more similar to a traditional homescreen, having favourites pages and an application drawer to access the full list of apps.
The problem with Folio in Plasma 5 though was that it was particularly unstable (known to brick the shell), and was effectively an extended desktop canvas, so screen rotations and scaling changes would completely ruin the layout.
I knew that it would require a very significant effort in order to rewrite it and fix its issues, so I developed Halcyon as a stopgap solution until I had the time to fix Folio.

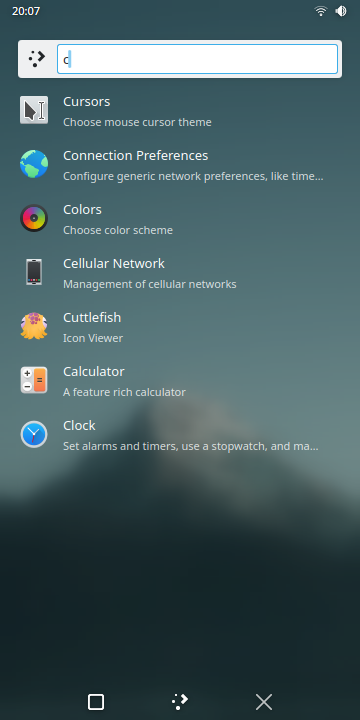
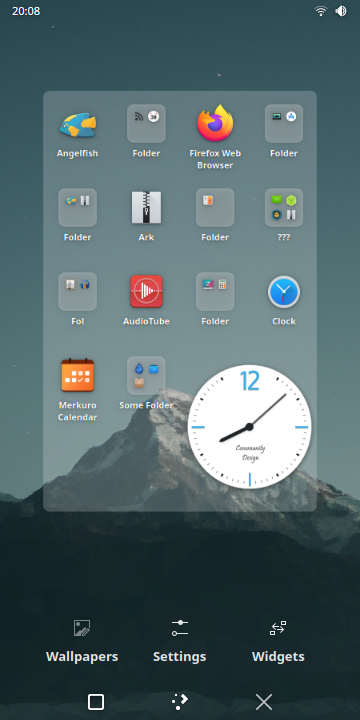
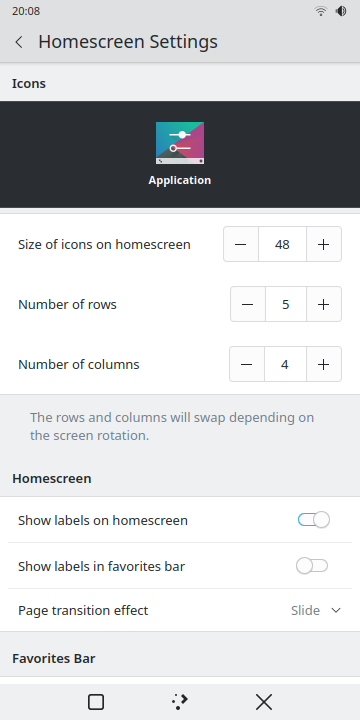
And so I spent about 5 weeks starting in October working solely on the Folio rewrite! It will be shipping as the default homescreen once again in Plasma 6.
I am pretty happy with how it turned out, it supports:
- An app drawer
- KRunner search
- Folders
- Pages
- Drag and drop between all of the above
- Applets/widgets
- Row-column flipping for screen rotations
- Customizable row and column counts
- Customizable page transitions
- Ability to import and export homescreen layouts as files
- … and more!
Applets in particular are pretty exciting, though still need some work. They use the same infrastructure that the Desktop uses, so we can use existing applets!
New applets for mobile apps can eventually also be developed, pending interest.
A new service: plasma-mobile-envmanager 🔗
Plasma Mobile relies on some configurations (set in files) for KWin and the shell in general that directly conflict with what Plasma Desktop expects.
For example, we use different look-and-feel packages to provide pieces such as the lockscreen theme, as well as tweaks for features such as disabling window decorations.
In Plasma 5, this was accomplished by having the distribution ship config files that are installed to /etc/xdg (from plasma-phone-settings), which overrode Plasma related settings for users.
This was problematic in that this would affect the desktop session, making it impossible to use both the desktop and mobile sessions without doing some tweaking before switching. This also made it a barrier to be easily installable as “just another desktop environment”, which was a common complaint.
In Plasma 6, I introduced plasma-mobile-envmanager a utility that runs prior to shell startup that automatically does the configuration switching between what is needed for Plasma Mobile, and what is needed for Plasma Desktop.
This now allows distros to drop having to install hardcoded configs onto the system, and makes it easy to simply install as a separate desktop environment for existing systems.
A new application: plasma-mobile-initial-start 🔗
I added an application that runs when starting Plasma Mobile for the first time, guiding users on configuration on their system, from setting up the Wi-Fi, to configuring cellular settings.
It currently exists as an application that runs when the shell is started for the first time.
However, it likely needs to eventually be ported to be a true first-start wizard similar to what GNOME has as well as pico-wizard (used by Manjaro), in order to have elevated permissions so that the user does not have to be prompted for their password.
Docked mode 🔗
With Plasma 6, I am making some steps toward improving support with attaching a monitor, keyboard and mouse.
A new “Docked Mode” quick setting was introduced that, when activated:
- Bring back window decorations
- Stops opening application windows in fullscreen
Eventually, some more work can be done in order to have the external monitors load desktop panels instead of the mobile ones, which should make the experience equivalent to Plasma Desktop.
Telephony 🔗
I have historically not done much work on the telephony front.
There have luckily been contributors that have worked on Spacebar and Plasma Dialer (shoutout to Michael and Alexey!) in the past few years, allowing me to focus on other things.
From recent testing though, there have been a lot of regressions in Plasma 6, so I likely need to start learning the ropes of how it all works in order to help out. Of particular focus for me will be improving the quality of the cellular settings and overall shell integration with ModemManager.
My current carrier only supports VoLTE so I have been unable to test calling, and I have had trouble with my PinePhone in getting cellular working, but I will probably try buying a USB modem to do testing on the desktop with.
Settings module consolidation 🔗
In Plasma 5, a lot of mobile specific settings modules lived outside of the Plasma Mobile repository, in places such as the settings application.
I moved these settings modules together to be in the Plasma Mobile repository. This also removes the need to have a separate build of plasma-nm.
Other things to address 🔗
A big pain point in Plasma 5 was the mobile lockscreen. There were many cases of it crashing (causing the white text on black screen issue) as well as extraordinarily slow load times.
Much of it likely stems from the fact that it has to load the QML files right after the device locks, which can be slow and sometimes has graphical issues when coupled with suspend. I have tried to optimize the load time in the past, but it may be the case that we need to rethink the architecture a bit, not sure…
Conclusion 🔗
I will be returning to a university term in January, likely making it harder for me to contribute for a few months again.
I have luckily finished most of the features I have wanted to get done for Plasma 6, and am now spending my effort fixing bugs and improving code quality. I hope that we can have a successful, bug-free Plasma Mobile release in February, but it is quite daunting at the moment as a single volunteer contributor for the mobile shell.
If you are interested in helping contribute, I encourage you to join the Plasma Mobile matrix room!
There is also some documentation on the wiki that can help you get started.
go konqi!


 @mahoutsukai:kde.org
@mahoutsukai:kde.org
 CarlSchwan
CarlSchwan














 Dear digiKam fans and users,
Dear digiKam fans and users,